這一篇我們介紹Data Catalog(一種metadata 的管理服務)可以搜尋與管理在你的Google Cloud裡所有的資料。同時我們也會介紹DataPrep — 一種資料預先(transformation/enriching)處理的工具. Data Studio資料視覺化工具。 Datalab — 一種 Data Exploration工具。
Data lifecycle有許多面向來決定與設計storage system. 資料也許是運作在以下幾種方式
在這篇我們將會討論如何使用Data Catalog, 一種metadata management service來支援在Google Clod裡dataset探索與管理。之後我們會將注意力轉到Cloud dataprep, 一種資料預處理(transforming and enriching)流程工具, 再來是Data studio(一種資料視覺化工具)與Cloud Datalab (與資料互動探索與腳本編寫),在每一個case, 我們也會討論到一些典型的業務需求。
Cataloging and Discovery with Data Catalog
企業運作的越久組織越大所積累的資料就會越多,對我們的挑戰就是如何持續追蹤在這些龐大資料裡的資訊(metadata)。例如,你可能有上千個Cloud storage裡面包含了上千萬的資料檔案。我們的管理責任就須要持續保有這些資料的資訊,像是file裡的內容,結構化資料的schema version,兩個file內data的相關性,誰可以access data等工作。這一類的資料的metadata就變得相當重要,因為這可以幫助我們了解資料是不是可用,它代表甚麼意思,以及如何使用它。
Data Catalog是 GCP 對資料進行管理的託管式metadata service。它的主要功能是對企業資料提供單一,綜合view。 meatadatay在Bigquery,Cloud Pub/Sub以及其他透過APIs執行資料匯入時就會自動產生。Bigquery metadata在datasets, tables, view的level被收集。 而在Cloud Pub/Sub topic metadata也是被自動收集的。在我們使用 Data catalog服務時,我們需要在peoject 中啟用 Data Catalog API.
在Data Catalog 執行搜尋
這種搜尋功能就跟我們使用Gmail或Google drive的方式是一樣的。所以在執行搜尋時users可以filter與find native metadata, 這是從包含subject data和用戶生成的metadata的底層存儲系統中擷取的,這些metadata是從tag中收集的。我們稍後會提到tag這個概念。
要能執行這個功能,第一步就是要對這些data subject有權限,這些data subject像是 Cloud Pub/Sub topic的bigquery dataset. Data catalog就是一個單純對metadata執行收集與搜尋的功能,而不是在dataset, table, topic等等的這些資料。下圖為一個 Data catalog overview的範例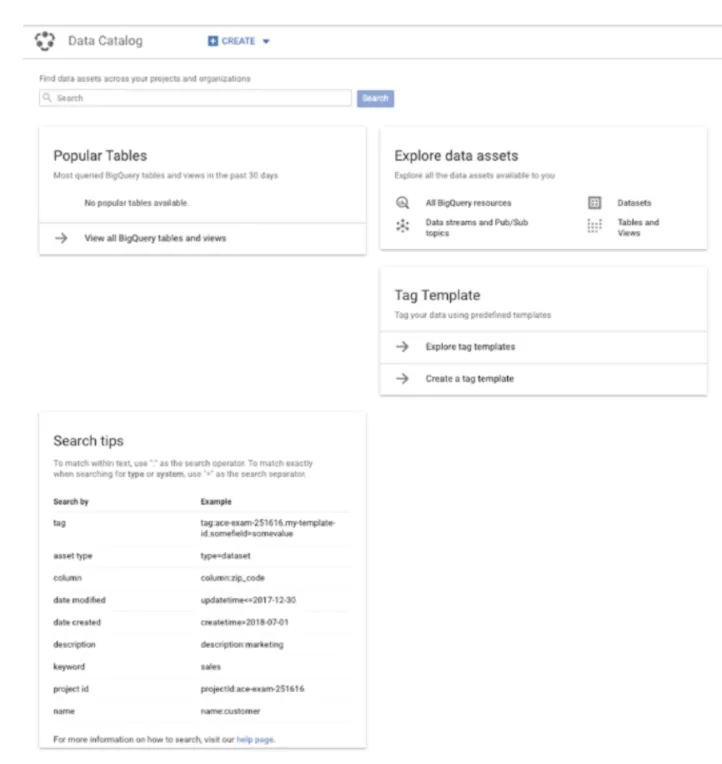
當這些storage system的metadata開始被收集後, Data Catalog就是一個read-only service. 任何metadata的異動都是其相對應的storage system能自行去更動的。Dara catalog 自動的從以下服務清單來收集
metadata也可以手動來收集。
Data Catalog的tag
Tag這一個概念是普遍在GCP與其他公有雲業者用在對其resource做metadata的儲存。Tags在metadata的使用是很廣泛的,像是如果有一個部門或團隊在Cloud storag裡的bucket or object給tag後就可以做資料分類的工作。
Data Catalog 使用template來協助管理使用者定義的metadata. 下圖為一個tag template, 這裡面包含了template detail以及tag的屬性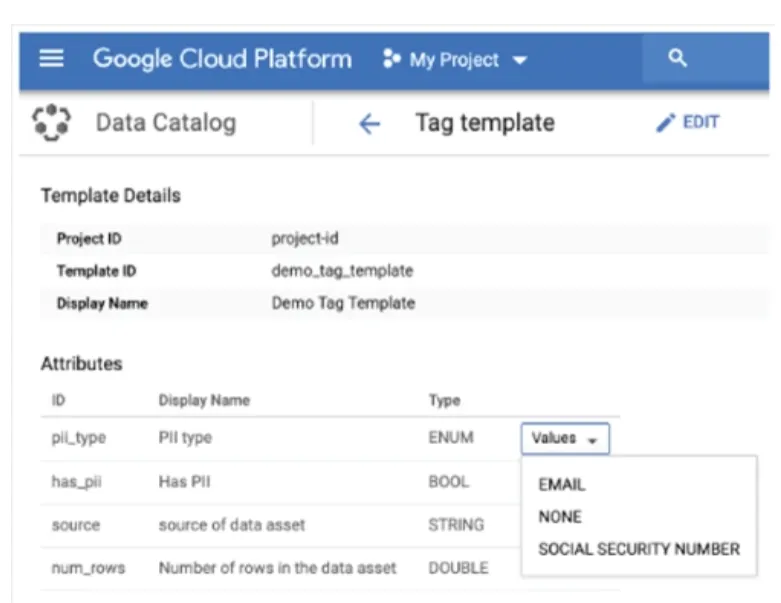
Dataprep 的資料預處理
我們在處理資料時,花最多時間的可能是在資料準備階段。Cloud Dataprep就是一個託管式服務來大幅減低從資料的explore, cleanse, and transformation等這種工作的準備時間。
一般會使用到dataprepe的業務要求通常是我們的原始資料格式並不適合用來做分析。這些狀況可能是從最簡單資料格式轉換到更複雜的情境,像是需要偵測不一致或資料品質很差的資料。
Cloud dataprep是一個用拖拉元件到workflow的互動式工具。使用者可以直接讀取Cloud Storage 跟Bigquery的資料,也可以直接從本機上傳資料。當我們上傳資料時Cloud dataprep會嘗試去偵測資料的schema, value的data type, 數字型資料的分佈,與遺失或不正常的values。下圖為一個使用者會看到一個summary data的處理過程。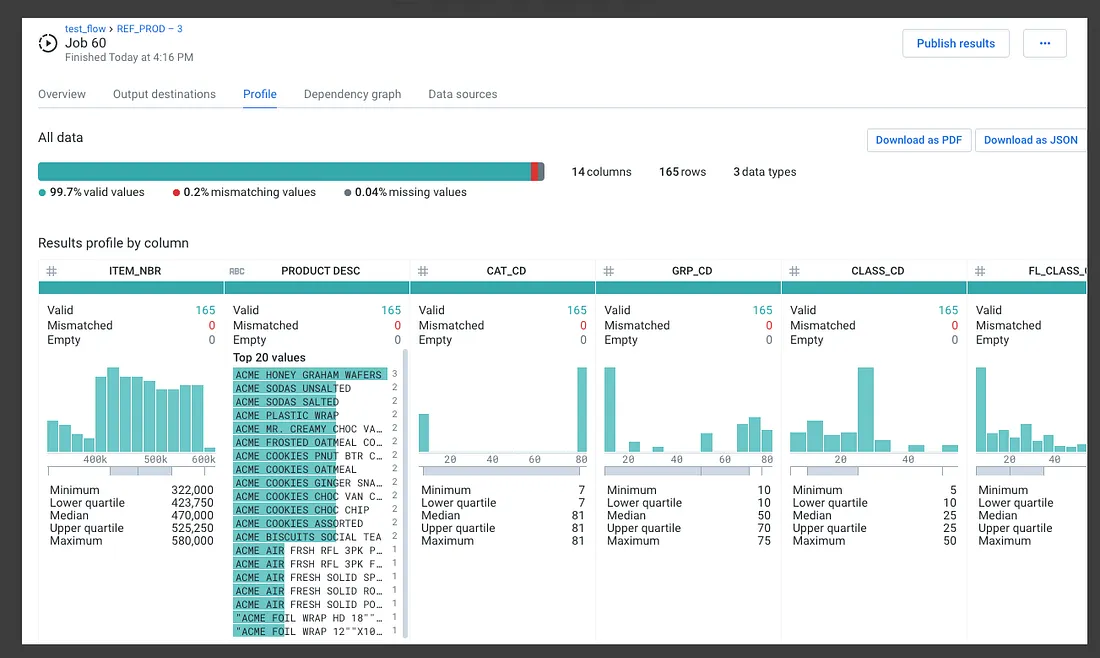
上圖是一個關於資料屬性的統計分佈圖。
資料清理(Data Cleansing)
資料清理其實是一種煩人的工作。它通常需要仔細關注dataset中幾乎任何地方的資料細節。在一些狀況下,只有少數values是遺失或是不正確的資料格式,而其他的狀況可能是某一個column中的每個value都修要被修正。
在Cloud Dataprep的主要清理作業圍繞在columns name的更改,reformatting strings, and working with numeric values. 以下有一些資料清理工作的範例可以用Cloud dataprep來處理:
在資料清理階段時我們與資料通常是交互的(iterative)。我們也許找到某些資料格式是需要去修改,然後開始資料探索後才能了解資料的異常並且修正。Cloud dataprep的交互特性支持這種臨時的、迭代的步驟序列.
Discovering Data
對資料分析或進行機器學習的另一個處理資料的步驟就是辨認資料的patterns與不一致性。Cloud Dataprep針對這一步驟提供以下的功能:
Enriching Data
有時,資料本身必需透過額外的columns增強資料本身的可分析性。例如,資料也需許會透過 join or append。 Cloud dataprep支援以下幾種data enrich資料的作業:
Importing and Exporting Data
Cloud Dataprep可以支援匯入以下檔案格式的資料:
同樣的Cloud dataprep也可以export data, export支援格式如下:
Structuring and Validating Data
Cloud dataprep 具有用於更高階transformation的功能,包括以下內容:
Reshaping data
Splitting columns
Creating aggregations
Pivoting data
Manipulating arrays
Manipulating JSON
還有驗證數據,包括profiling source data。 Profile 的資訊包含:
Mismatched values in columns
Missing values in columns
Statistical breakout by quartile
在資料準備作業完成後,接下來我們就可以進行資料視覺化的作業。
使用Data Studio進行資料視覺化
這是一種報表與視覺化的工具。Data studio可以直接讀取並將資料轉化成表格與圖表。下圖為一個利用Data studio產生的報表。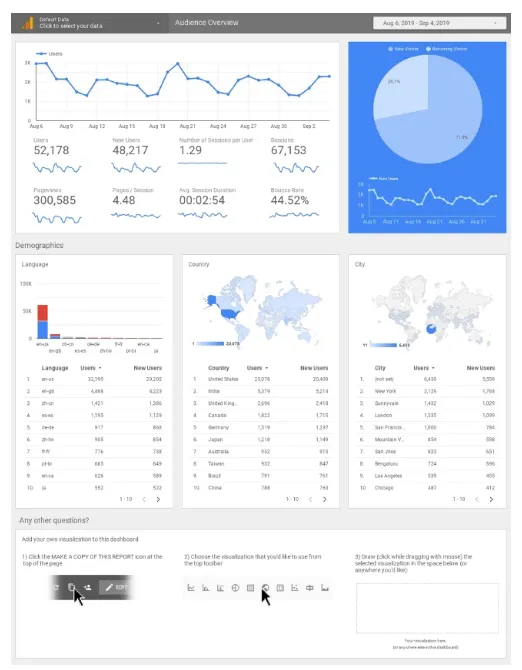
Data Studio可以使用的場景有很多,像是data warehousing 的報表和監控系統的dashboard. Data studio有三個基本作業,分別是連接資料來源,資料視覺化與報表共用。
連接資料來源
Data studiog使用一種稱為connector的概念來連接data source,而data source稱為Dataset。Dataset的型式有非常多種包括relational DB table, Google sheet, Bigquery table。 Connector可以連接data source 中的全部或部分columns。而這樣的連接通常需要有授權(authorize)。
以下有三種類型的connector
Data Studio可以連接的 data source也有三種型態
當我們在Data Studio連接好Data Source後就可以視覺化資料了。
資料視覺化
Data Studio 採用元件拖拉的方式來製作報表。 Data Studio reports是一個表格與視覺化的集合。而這些視覺化的元件包含如下:
報表共用
當我們完成報表後就可以與他人共用,我們可以給其他人view或是edit的權限。我們也可以排程來產生報表並轉成PDF檔案後發出email給相關人士。
使用Cloud Datalab進行資料探索
這是一個交互式的資料探索工具,除了資料探索還能進行資料轉換。Datalab 作為容器的instance運行,意思是我們在使用Cloud Datalab時,實際上是run一個 compute engine instance, 然後在上面跑一個container,之後用browser來連接在上面運行的Cloud datalab notebook, 如下圖
Cloud datalab container運行的就是一個Jupyter Notebook instance.
Jupyter Notebooks
jupyter notebook 是可以包含code和text的文檔。 code和text位於cell中。 單cell內的所有text和code都被視為單個 unit。 例如,當一個cell被執行時,cell中的所有code都會被執行。
Jupyter Notwbook被廣泛的使用在資料科學,機器學習與其他適合交互式、迭代開發工作。並且也支援多種開發語言包含Python 與SQL。
管理Cloud datalab instances
這是一個相關簡單的作業(create and use Cloud datalab instance)。當我們安裝好Cloud Software development kit(SDK),在安裝時要勾選 Datalab component的選項。這時我們就可以使用command line方式來create instance,例如下面例子
datalab create — machine-type n1-highmem-2 jason-datalab-1
當instance完成後,我們可以使用 datalab connect這個command line來連結節。而instance預設的port number 是8081,當然這個port是可以變動的。在上面create instance的範例中我們需要在後面加上 — port的參數來指定我們想要的port number。我們也可以用datalab list 來列出所有正在運作的instance。
當使用完畢時我們可以用datalab delete來刪除instance. 但是這只會刪除instance並不會刪除這個instance的 persistent disk。如果確定真的裡面的資料不要了,在我們delete instance時可以加上參數 — delete-disk。
在Cloud Datalab instance加入library
資料科學家或機器學習工程師通常在使用Python時會需要將library import近來。一些我們會常用到的library如下:
Numpy : 一種高效能的科學機算package
Scipy: 一個用在 science 與engineering的open source
Pandas: 一種用在tabular data的open source package
Scikit Learn: Open source的機器學習package
TensorFlow : Open source的深度學習的package
一些常用的library其實都有安裝在Cloud datalab中了,但如果沒有你要使用的library,你可以使用 conda install 或 pip install這兩種command line來安裝你所需要的library。例如我們要安裝資料分析的package — scikit-data,哪我們在Jupyter notebook cell的command就會是如下
!pip install scikit-data
驚嘆號的意思是告知Jupyter notebook這個command 是shell command不是python statement.
在某些情況下,探索性數據分析(EDA)本身就是目的,但在許多情況下,它是定義將重複性工作負載的第一步。 在這種情況下,我們可以使用 cloud composer 來編排這些工作負載。
使用Cloud Composer編排workflow
這是一個基於 Apache Airflow的全託管流程(workflow)編排服務。Workflow在Python是被定義為一個 Directed Acyclic Graph(DAG-有向無環圖)。而這種有向無環圖的workflow可以被使用在GCP的以下服務:
Bigquery
Cloud Dataflow
Cloud Dataproc
Cloud Datastore
Cloud Storage
Cloud Pub/Sub
AI Platform
在wsorkflow裡的element可以跑在地端或是其他的雲端業者,如同跑在GCP服務中。
Airflow 環境
Apache Airflow是一種分佈式系統,並且它需要好幾種GCP服務。當我們部署它時,Cloud composer environment也被同時部署。所謂的Environments是指一套運作在GKE上獨立的deployment。因為這樣,所以我們可以在同一個Project部署多個Cloud composer environment.
這個Cloud composer environment我們可以使用console或command (gcloud composer)來create。當我們create instance時,我們需要指定node / network configuration與其他環境相關的變數。
Creating DAGs
Airflow DAGs 在 Python 中被定義為一組operators和operators間的關係。一個operators就是在整個workflow其中的一個單一作業。最經常使用到的operators如下:
BashOperator: 在Bash shell執行command
PtyhenOperator: 執行Python函數
EmailOperator: 傳送email message
SimpleHTTPOperator: 傳送Http request
Database operators: 包含 PostgresOperator, MySQLOperator, SQLiteOperator, JdbcOperator
Sensor:等待creation event,例如特定時間或文件或其他資源的創建
Operators的執行順序是用 >>的符號。假如我們要使用 PythonOperator執行一個 write_file_python後再使用 BashOperator 執行 delete_tmp_files_bash,哪我們可以順序可以寫成以下
write_file_python >>delete_tmp_files_bash
Airflow Logs
在Airflow環境中會有兩種log的產生: Airflow logs 與 streaming logs. Airflow logs是每個單一的 DAG task產生出來的。這些log 檔案會存放在Cloud storage的 cloud composer environment的folder中。即使環境被關閉這些log還是會存在。所以這些log是需要手動刪除的。
streamming logs則是Airflow logs的 superset. 這些log是被存放在stackdriver並且能使用Logs Viewer來觀看。我們還可以使用基於log-based指標進行監控和告警。Airflow會有以下幾類的logs
Airflow-database-init : DB的初始化
Airflow-scheduler: scheduler產生的logs
Airflow-webserver: web interface產生的logs
Airflow-worker: 執行DGA作業時產生的logs
Airflow-monitoring:監控時產生的logs
Aitflow: 其他沒有分類的logs
總而言之,Cloud composer 的關鍵在於它是一種工作流程編排服務,它在 GKE 中運行並執行由執行tasks的operators組成的 Python 腳本中指定的執行時間。 任務可以按schedule、手動或回應外部事件執行。
 不明
不明

 iThome鐵人賽
iThome鐵人賽