本篇我們會學習到AWS針對機器學習(以下簡稱ML)會遇到的不同問題,如影像/聲音的分析,自然語言處理,文字轉成語音(或是反過來),或是建立推薦系統,時間序列預測等等問題所提供的各種不同的服務。AWS所提供的這些服務可以讓我們很快的建立我們所需要的ML平台,而不需要太高深的ML經驗或知識。我們將會學習到如AWS的SageMaker,這是一種全託管服務並且能夠提供給資料科學家與ML開發人員來建立,訓練,並且部署ML模型在AWS中。
AWS Rekognition
這是一個對圖片或 影像分析作業流程的服務。這是AWS累積了非常多基於圖片(例如圖片分類,影像中物件偵測,影像中文字的偵測,臉部辨識,情緒分析等等)的深度學習經驗後提供給我們的AI服務。
儘管開發影像分析模型背後有大量的深度學習研究,但訓練這些深度學習模型的電腦運算成本通常很高,並且可能需要一個團隊的資料科學家或開發人員的時間。 這時 AWS Rekognition 就能上場幫忙 。借助 AWS Rekognition,開發人員可以簡單地利用預先訓練好的模型或訓練自定義的ML模型,而不需要編寫演算法,或者設置/管理用於訓練和部署深度學習模型的基礎設施。 更重要的是,我們不需要任何先備的ML或深度學習知識即可使用此服務。
在我們進一步介紹 AWS Rekognition之前,我們很快地來看一下在深度學習中的圖片和影像主題上的一些基礎。影像辨識通常會需要依靠CNN(Convolutional neural network)架構。 CNN是由交替的卷積神經層(convolutional layer)組成的深度學習演算法,它對輸入的資料使用各種過濾器以擷取不同級別(scale)的不同資訊,通過polling layer的方式做資料流動,從而減少網路中的參數數量以及呈現的空間大小。初始層(initial layers)會擷取low-level feature,像是物體的邊緣與線條,接續的layer會建立high-level的物體到最終能辨識這項物體。在CNN中有非常多架構,例如ReNet或Inception V4,不過我們還是要能理解這些架構的概念。
在ML中,學習transfer learning 的概念也是相當重要的。Transfer Learning 是指採用在一個資料集上預先訓練好的模型,凍結初始層,並讓它在不同的資料集上重新學習模型的最後幾層。 這樣做的好處是:
在圖片分類領域,Transfer learning中使用的 Inception V4 與 ResNet演算法都是很普遍的。而Transfer Learning的用途不只可以用在 圖片或影像的資料型態,它也能用在自然語言處理(NLP)。
對於物件偵測(object detection),基本架構是相似的,但這個模型不是偵測貓與狗(這種有固定label),而是偵測在一定的範圍內想找的物件。 常用的演算法包括SSD(single shot detector)、R-CNN 或 Faster R-CNN,以及 YOLO v4。
最後,semantic segmentation實際上是通過對物件是否屬於特定的像素(pixel)進行分類來分割圖片中我們想找的物件。 一個例子是偵測人體組織中的腫瘤。 對醫生來說,不能只框出一個邊界就足夠了,還需要準確地將腫瘤組織與正常人體組織劃分開來。
我們可以使用 AWS Rekognition在以下的案例:
圖片與 影像的作業
AWS Rekognition可以用在靜態的圖片以及影像(已經錄製存放的)。圖片的操作是同步的,而影像則是非同步的。這意思是當我們使用 Rekognition處理影像的作業完成時,Rekognition會通知(使用SNS )我們。我們之後就可以呼叫一個"get* API"來存取產生的結果。而同步的API Call作業則在呼叫同時得到我們要的答案。
AWS Rekognition並不是支援所有影像的操作;例如,PPE detection API只能支援圖片。而人類的軌跡移動只能用在影像。
例如在圖片或影像中偵測一個物件。對於在圖片中偵測物件,我們的圖片來源可以是在S3中的圖檔(如 JPEG or PNG)或是一個byte-encode image input。 假如我們使用boto3( AWS的 Python SDK),我們就需要使用呼叫一個API call。(完整的範例與操作)
經過上面的運算,運算結果會長得像以下這樣
通過指定 MaxLabels ,我們可以限制收到的回應數量,AWS Rekognition 將返回一個回應,來顯示圖片中偵測到的各種物件的邊界框和信心指數(confidence score),如上一個範例所示。 信心指數可用於下游作業。
相比之下,對於影像作業,我們不能傳位元型的資料,而必須傳存儲在 S3 中的影像位置。其 API 是 StartLabelDetection,我們還需要傳一個 SNS topic,以便 AWS Rekognition 在完成影像標記作業後向其推送一個 notification。 然後,我們可以呼叫 GetLabelDetection API 來存取結果。
另一個 AWS Rekognition 是可以用在串流影像。AWS Rekognition可以擷取(ingest)串流影像,但必須是從AWS Kiniese Video streams過來的資料,處理完成後再推送到Kinesis Data Streams。
小提示:
如果我們想要用的是一個可擴展的圖片/影像分析流程,我們可以考慮使用 AWS Lambda 來 製作一個 AWS Rekognition API calls。可以用AWS SQS來queue傳入的資料,限制會進到 AWS Rekognition API。詳細的架構可以參考此連結。
AWS Textract
這是一個可以讓我們從各式各樣的文件提取我們想要的文字,而讀取文字的方式是使用OCR(optical character recognition)。使用Textract,我們不再需要建立深度學習影像模型來提取這些文字(例如從PDF檔案)。這一個服務能夠讓我們在現今充滿大量數位文件的世界中快速建立自動化的文件處理流程。而Textract可以處理"非結構化”及”半結構化”的資料(free-form text/ tables等)。
不過此項功能只有提取文字的作用,它並不能對文件進行分類,情緒分析,或辨別整份文件。而這些功能只有AWS Comprehend才有,後面會提到。不過在我們商業流程中, textract與 Comprehend是經常組合一起使用的。
使用AWS textreact的常見場景如下:
同步與非同步APIs
文件有著多種的形式與大小,例如掃描後的圖檔或是一個檔案有很多頁的PDF檔。
對於同步 API,我們可以用byte array或 S3 object將資料傳到Textract進行處理。 我們可以使用 DetectDocumentText 或 AnalyzeDocument 等同步 API 來返回包含偵測到或分析的文字的 JSON output。 Analyze API 還識別文件中的層次結構,例如form data、tables以及text的行列和字。 Detect API 僅偵測文字。
雖然文件通常都被歸類為非結構化資料,不過它們通常還是有結構存在的。例如,一些制式化的銀行申請表單一定會有一個姓名欄位,後面就會有一個名字,如Jason Kao。現在Textract掃描後返回這一個名字後,這一筆資訊就可以讓我們傳到下游系統繼續處理。
AWS Textract 將文字轉換成key-value pair ,允許我們將這些輸出直接的存到key-value DB。類似如table 和table data分別作為 Block 和 Cell objects,提供有關文件中表格位置的邊界框資訊,然後是有關表格中底層cells的資訊。
對於 PDF 檔案或大於一頁的文件,需使用非同步 API StartDocumentAnalysis 和 StartDocumentTextDetection 。由於偵測大型文件中的文字可能需要一些時間,Textract 將在背景處理文件並將完成狀態發送到 SNS topic。這個topic的subscriber隨後將收到作業已完成的通知,並可通過使用 GetDocumentAnalysis 或 GetDocumentTextDetection API 查看結果。然後可以將作業的結果存儲在 DynamoDB table、S3 bucket。
讓我們看一個使用案例,一家醫療公司希望從病患表單中提取文字以後讓下游系統繼續處理,例如使用ML改善整體病患體驗。該公司目前在 S3 中存儲了數百萬個 PDF 文件。由於這是一家醫療公司,因此保護病患資料是頭等大事,並且HIPAA法規是任何雲端服務的一項要求。最後,公司高層不完全信任基於ML的解決方案,並希望人工審查一些由ML產生的結果。
首先,AWS Textract 在這裡可能是一個潛在的解決方案,因為它符合 HIPAA 標準,並且具有非同步 API,可以使用PAYO(pay-as-you-go)定價模型從大量 PDF 文件中提取文字。此外,AWS還有一項名為 Amazon Augmented AI (Amazon A2I) 的服務,可以直接與 Textract 文件分析 API 整合,根據特定threshold condition(例如對偵測到ML很低信心分數的文字)發送文件以供人工審核(如下圖 )。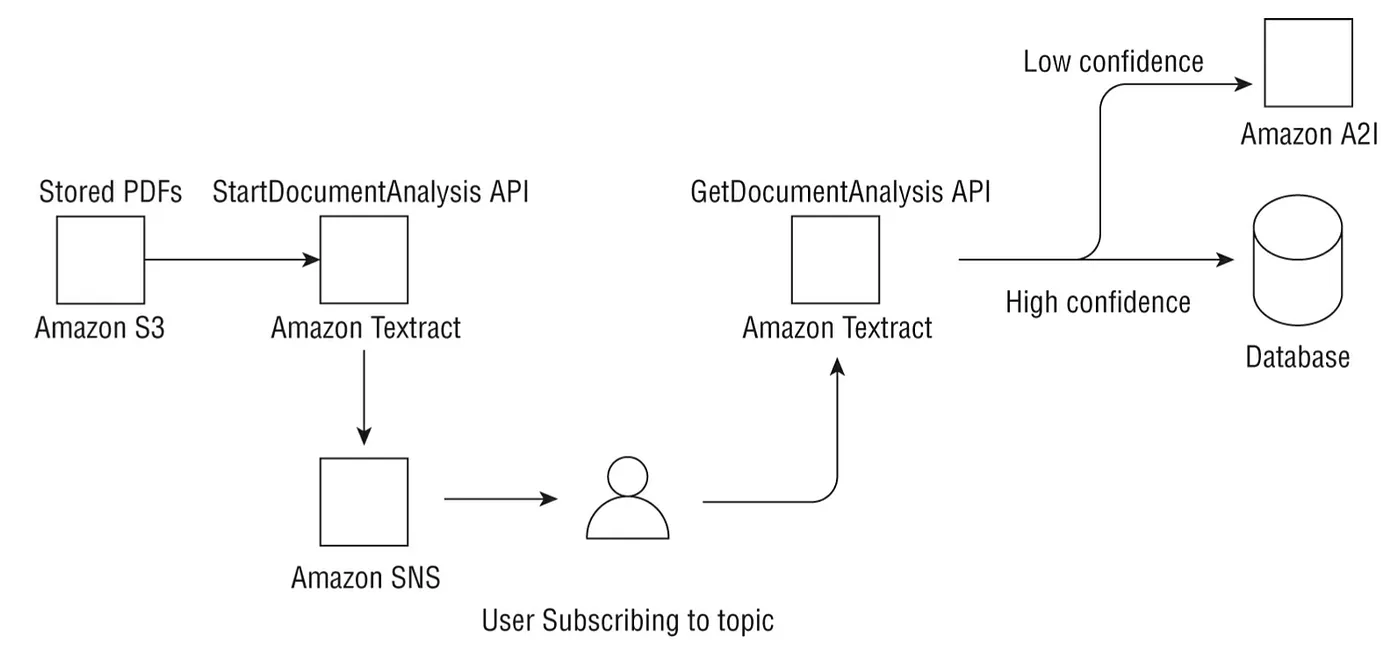
AWS Transcribe
這是一項適合大型客服中心的服務。這個客服中心可以每天處理客戶電話的voice data(real-time/streaming and batch)錄音作業,由於每天要接成千上萬通的電話並且有著多種語言的服務。我們需要一套系統來幫我們解決這一項作業,並且是具成本效益與可擴展還有不需要太多的設定。
傳統的客服中心通常都是把聲音錄成音檔格式。而電腦可以將這些音檔轉換成文字。為此,現代化方法稱為ASR(Automatic Speech Recognition),並為 Amazon Alexa 等技術提供支援。 這些技術使用神經網路將 audio sequence作為輸入(input),並使用稱為sequence-to-sequence的模型產生由文字組成的output sequence。 然而,準確地建立這些模型需要大量資料,而並非所有公司都會有的。
AWS Transcribe 利用與 Amazon Alexa 相同的技術,但可作為transcription service使用,讓我們無需任何ML知識即可轉錄我們的語音資料。 以下是其中的一些功能。
Transcribe Features
Stream and Batch Mode — Transcribe支援用串流或批次的模式。如果是 串流,audio會直接用HTTP/2協定的方式傳入。也可以用Transcribe提供的streaming client,或者是我們也可以使用 WebSocket協定。如果是已經存在S3的音檔,我們可以使用 批次錄音作業(batch transcription job)中的StartTranscriptionJob API來完成。
多語系支援 — AWS Transcribe 支援多種語言,並且AWS會持續更新語言清單。
多語系轉錄 — 我們的音檔中可以包含多個語言。如果我們知道我們的音檔中包含一種以上的語言則可以通過指定 LanguageOptions 將language code作為 API call的一部分進行傳輸。
Job Queuing — 為了不把API服務打爆(API throttling),可以使用此種功能將job送往queue,這樣就不用建立一套邏輯防止API被打爆。
Custom Vocabulary and Filtering — Transcribe提供類似一個字典功能(這是可以自訂義的),來讓Transcribe可以使用辨認其語音,像是特定名詞或是特定領域的詞彙。當然我們也可以去除一些文字,例如不好的語言。
自動內容編輯 — 假如你的音檔包含了一些敏感的個人資訊,Transcribe可以讓你編輯這些敏感資訊在處理後的資料中,或是分成兩種腳本(編輯過與未編輯過的)。
語言辨識 — Transcribe 可以辨識在我們的錄音檔中的主場語言是甚麼。
發言者辯識 — 在transcriptio中可以辨認不同的發言者。
讓我們回到客服中心的例子,現在要開始對AWS Transcribe進行POC(proof-of-concept)。由於在音檔轉文字的過程中我們需要移除個人資訊並且另外儲存這些資料,這一點Transcribe PII detection 功能可以做到。但我們在POC的過程中發生了一些狀況,雖然整體功能良好,但是在某些特定領域有一些狀況,就是轉錄的文字不夠精確。再來,這個領域的高度特殊的詞彙大小超出了 50KB的限制。為此,我們需要建立自訂義的模型。而我們也需要有training dataset來訓練這一個模型。
小提示:
AWS Transcribe自訂義的model與AWS Comprehend有甚麼分別呢?Transcribe自訂義的model只能用在聲音轉錄成文字。Comprehend Custom是可以針對文件進行分類與entity extraction。
Transcrible醫療領域的使用
醫療領域高度專業化,特殊詞彙的量很大。 因此,大多數常見的深度學習模型在該領域都不能很好地發揮作用,除非它們經過專門的醫學資料訓練。 AWS Transcribe Medical 是一項 ASR 服務,可讓我們轉錄醫療音檔,例如醫生口述、患者與醫生的對話和遠距醫療。 Transcribe Medical 可在串流與批次模式下使用(僅適用於一般性問診),允許我們建立自定義詞彙表並從我們的串流轉檔中編輯PHI。
AWS Translate
假設專門為一家在全球多個不同國家/地區營運的全球連鎖飯店工作,我們希望匯總和收集客戶服務的線上對談資料以改善客戶體驗。 唯一的問題是,使用場景會發生在不同的語言中,而且用不同的語言建立基於神經網路的翻譯模型既困難又昂貴。 第三方翻譯工具可能還有品質問題,而我們可能更喜歡按使用pay-as-you-go的定價模式。 使用 AWS Translate,這是一項文字翻譯服務,它使用先進的深度學習為沒有任何深度學習經驗的客戶提供高品質的翻譯功能,並採用按需付費的定價結構。
現在我們進入POC階段,如果我們已經有所有的線上對談資料。但業務團隊提出了以下兩個問題:
AWS 的翻譯功能
以下是AWS的翻譯功能:
同步與非同步API : AWS翻譯功能能夠讓我們非同步與批次的處理大量的文件資料,batch job最大資料為5GB(使用 StartTextTranslation API)。這個API的好處是當單一文件包含的collection是很小的,例如社群媒體的評論或評分。而size很小的文件我們也可以用 TranslateText API來處理它。
自定義的術語與平行資料:此外,我們可以通過提供自定義術語(CSV 文件)來自定義翻譯的輸出,該文件提供原始語言中的自定義術語和所需的目標術語。 我們還可以傳入parallel data,向這個翻譯服務展示我們希望如何翻譯文章段落。 不過,並非所有語言都適合自定義術語;我們可以在AWS網站找到相對應的文件。
Translate 不允許我們建立自己的自定義翻譯模型; 它使用由AWS訓練的模型。 因此,AWS可能會使用客戶資料來提高其演算法和模型的品質。 如果不要 AWS Translate 和其他 AI 服務用我們的自訂義資料,我們可以選擇退出此功能,請參閱這個文件。
下圖是完整的batch-based流程來處理已儲存的資料,這個範例是從西班牙語轉成英語然後運行一個 custom entity 或lebel detection model(使用的是 AWS Comprehend)。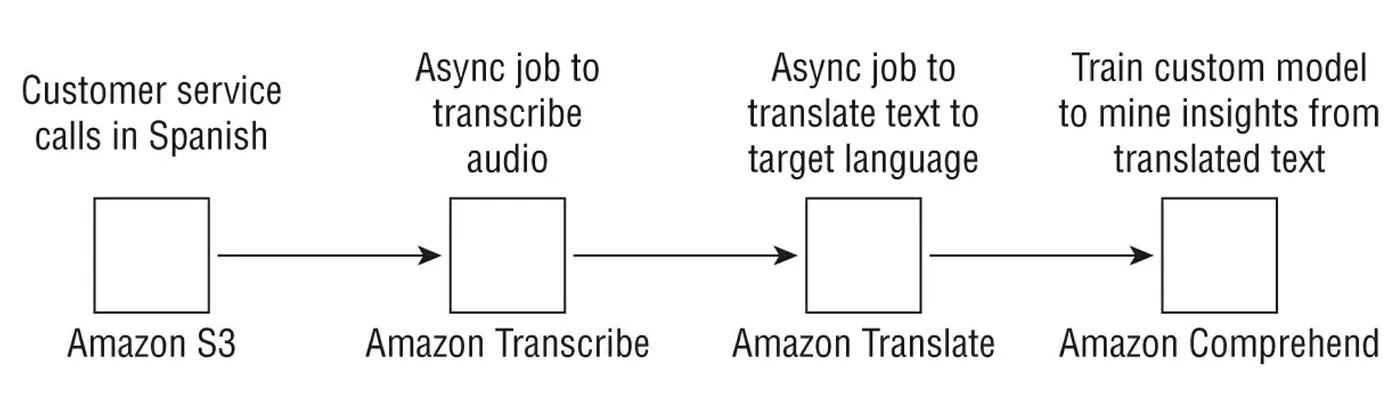
AWS Polly
這跟Transcribe是相反的服務,這是從文字轉成音檔(Text to speech)。這主要提供一個文字檔(plain text)或使用 SSML(Speech Synthesis Markup Language)語法。Polly會去讀這個語句並可以產生不同語言的音檔。
那麼語音合成是如何作業的呢? 標準語音合成 TTS 的工作原理是將稱為音素(phonemes)的基本語音單元串在一起,形成聽起來自然的合成語音。 諸如深度學習之類的AI技術已應用於文字轉成音檔以產生 Neural TTS(NTTS)。 Neural TTS 模型由所謂的sequence-to-sequence模型組成,該模型採用輸入序列(通常是一個句子)並生成一個輸出序列(由模擬大腦在處理語音時使用的聲學特徵的頻段組成的頻譜圖)。 該模型的結果會傳遞給Neural vocoder。 Neural vocoder是相當於將頻譜圖轉換為語音音素的語音。
哪麼何時使用TTS或NTTS呢?
訓練 NTTS 模型準確需要大量資料,想爾當然它們還不是在所有語言中都可用。 因此,首先,我們要檢查 NTTS 是否適用於我們要翻譯成的語言。 如果我們正在尋找新聞播音員的演講風格,則必須使用 NTTS。 通常,如果我們可以選擇,與標準 TTS 相比,NTTS 會生成更優質的語音。
如果我們想控制語音輸出的產生方式,例如放慢或加快速度或控制音調或說話風格可以 使用SSML tags。將 SSML 視為一種類似於 HTML 的語言,它允許我們使用tag來定義如何呈現特定對象。 有關 SSML tag和 AWS Polly 支援的tag的更多資訊可以參閱AWS的文件。
SSML 類似於語音的 HTML。 通過指定諸如 tag 之類的標籤,我們可以控制語調、音量和語速。 同樣,如果我們想用不同的語言拼寫一個單詞,使用 tag。
通過指定 volume=”loud”,我們可以使用這個tag讓聲音變大。如果要讓聲音變柔和可以用 volume=”soft”。
或者,AWS Polly 還以speech maker的形式返回一個產生語音關聯的metadata。 這些可以告訴我們特定音頻在什麼timestamp開始、speech mark的類型(句子、單詞、SSML 等)、開始和結束偏移、哪個可用的 Polly 語音 ID 正在說話,等等。 有關speech marker的更多資訊更參閱AWS文件。
AWS Lex
客戶/消費大眾現今利用聊天機器人與我們的軟體互動,而這些軟體也了解這些使用者的意圖並且有正確的回應。普遍的案例包含電子商務/銀行的客戶支援,醫院門診的預約,旅館、機票等等的預定。
AWS Lex是AWS所提供的自然語言理解(NLU-natural language understanding) 與自動語音辨識(ASR- automatic speech recognition),這些服務讓我們能夠建立與佈署一個跟我們的軟體與人類之接的對話介面。使用AWS Lex我們可以為客戶打造量身定制的個性化體驗,無需任何深度學習專業知識即可與我們的軟體互動。
小提示:
Lex 與Polly的不同:
Polly也有使用到ASR, 但Polly只會把文字轉成語音。而Lex是一個中介的介面,介於我們的軟體平台跟使用者的意圖。
而主要在開發聊天機器人程式時通常有以下一些關鍵步驟:
Lex概念
所謂Bot(機器人)是一個實體(entity),它可以實現客戶想要的作業/操作。以電商/銀行的程式來看,這類的作業可能是客戶的下單,呼叫真人,或是進到後端資料庫找客戶想要的資料。
AWS Lex會呼叫Lambda函數這一類的背景作業來完成。例如,我們的bot可以幫我們預約到附近診所的醫生看診,哪就可以讓Lambda寫這一筆資料到RDS或DynamoDB。同樣的Lambda可以進到資料庫查找這一筆資料來提醒使用者看診的時間。
而在面對使用者的前端,bot需要了解使用者的意圖。這需要使用者輸入這個bot了解的語言(或數種它了解的語言)。關於AWS Lex的支援語言在這個AWS文件庫。
使用者的意圖就是bot要去執行的作業。話語就是使用者實際要求的內容。例如,我們要訂一個pizza,哪話語應該會是"我要一個pizza"而意圖就是去"下訂一個pizza"。
這時NLU與深度學習就要上場了。AWS Lex需要一些從使用者提供的少量的範例意圖資料來建立一個模式,而這個模式可以概括為使用者可以要求某事的無數方式。
讓我們回想一下在深度學習之前這是如何作業的。開發人員需要首先提供可以發出特定要求的所有方式的本體,然後建立一組規則來以某些方式對意圖做出回應,而如果使用者的話語不是機器人詞彙的一部分,哪麼就要提示使用者以不同的方式提出問題。
通過深度學習,該模型可以概括到新的話語,而無需有預先定義的規則。我們可以提供一些範例話語,例如“我想要披薩”、“我可以訂購披薩嗎”,Lex 將建立一個模型來概括到其他意圖。
Slot是定義使用者要求的一組參數,slot type是該slot的特徵(characterization)。該Slot可用於使聊天機器人對話。例如,如果使用要訂購比薩,則slot type可以是pizza,slots可以是小、中和大,這樣組合起來就是由小到大的pizza。機器人可以要求使用者提供尺寸或配料清單。一旦提供了所需的slots,聊天機器人就可以連接後端 Lambda函數,然後這個函數將呼叫 API 來下訂單或將訂單寫入訂單表。為了簡化聊天機器人應用程序的建置,Lex 為常見項目(如日期、姓名、號碼、電子郵件、地址和時間)提供了一組內建的slot和slot type。
如果我們正在使用 Lex 建立機器人,並且我們的機器人效能不佳,請嘗試增加範例話語的數量。我們提供的example越多,模型就能夠更好地概括沒見過的話語(utterance)。
如果機器人不理解使用者講甚麼怎麼辦? AWS Lex 會自動包含fallback intent(就是機器人會說: 對不起,我聽不懂你說的),因此我們無需自行建立。這一類的intent(意圖)會發生是,當機器人在設定的重試次數後無法識別意圖,或者該意圖無法將使用者的輸入識別為slot value或對確認提示的回應時。
通常,如果發生了 fallback intent,我們可以讓 Lambda 函數執行一些預先定義的操作,例如連接到人類客服。通過這種方式,對話流程給人一種對話式和自然的感覺。或者,如果我們的機器人無法理解使用者的要求,它可以觸發文件搜尋以提供答案(雖然很多人都不喜歡這種回應方式)。為此,我們可以使用 KendraSearchIntent API,它在後台利用 AWS Kendra。
下圖顯示如何使用 Lambda函數將後端的 Lex 與不同的 AWS 服務整合。 在這種情況下,AppointmentBot 使用關聯式 和非關聯資料庫向終端使用者顯示相關資訊。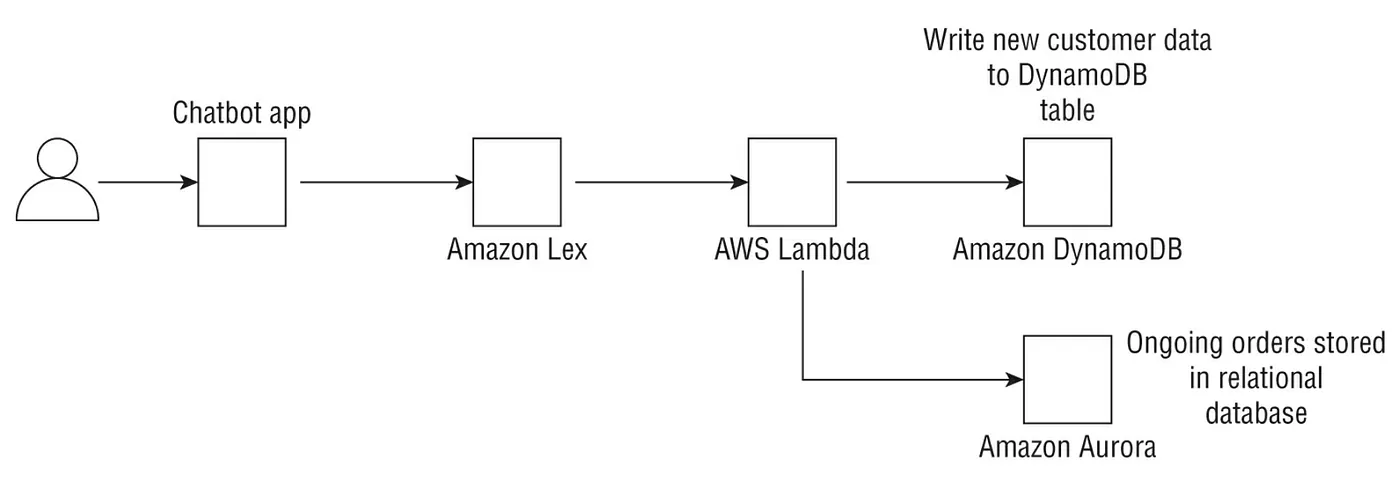
小提示:
Slots是可以設置的參數,utterance(話語)是實際的句子,而inetnt是整體的對話意思。在定Pizza的範例中,slots可以是pizza的大小或要加甚麼樣的配料,intent是要訂一個pizza,並且句子是說"我要一個夏威夷pizza","我要一個小pizza"等。
AWS Kendra
一個跨國企業需要在員工之間共享的內部資訊。此外,這些資訊通常以非結構化文件格式可能包含在來自 Microsoft Word 、Microsoft PowerPoint 、PDF 甚至第三方工具(如 Confluence、Salesforce、ServiceNow、Microsoft OneDrive 和 Microsoft SharePoint)的不同資料來源中。
該企業的 CIO 希望建立一個應用程式,允許內部員工查詢和搜尋這種非結構化資料並對其進行data mining以得到新的見解,並為使用者搜尋功能是能快速回應的,以提高知識共享和員工生產力。什麼 AWS 服務將允許我們建立這樣的應用程式?
看著敘述,我們可能認為這是要求我們從各類文件資料中提取字串,我們可能認為 Textract 是正確的服務,但這裡有兩個關鍵點:
CIO 不是要求我們簡單地提取字串;而是要求我們搜尋文件並建立一個提供有足夠智慧答案的應用程式。
資料來源不是只有 PDF。這兩點都會告訴我們 Textract 不是這裡的解決方案,而是 AWS Kendra。
AWS Kendra 允許我們使用自然語言建立我們自己的搜尋應用程式,為使用者查詢提供高度相關的回應,就像我們從組織內的人類專家那裡得到的一樣。使用 Kendra,我們可以獲得事實(例如阿里山的高度)的答案,以及複雜問題的描述性答案,例如“什麼是 合作夥伴表格?”甚至是使用者可以輸入“廠商匹配”或“退休福利”的關鍵字搜尋。
本質上,Kendra 由深度學習演算法提供支援,但效益是這一切都是從終端使用者那裡抽像出來的。原因很簡單,為自然語言建立和訓練高度準確的深度學習演算法既昂貴又複雜,並且需要企業對很難找又貴的ML專家進行大量投資。儘管並非所有企業都能負擔得起這樣的投資,但提供可擴展的內部搜尋平台的需求是普遍存在的。認識到這一點,Kendra 提供了兩種定價模式:開發者版和企業版。兩者都是PAYG,但後者通過在三個AZ運行來提供更高的可用性,允許更多查詢,並且可以傳入更多文件和文字。
Kendra是如何作業的
以下是Kendra基本的核心概念:
1.Index
首先我們需要建立針對文件建立索引以方便我們進型搜尋。索引是由 Kendra 管理的物件,它帶有關該文件的一些metadata,例如建立和更新的時間、版本以及我們可以作為使用者修改的custom fields(例如日期和數字)。
2.Documents
其中包括 Kendra 將編制索引的實際文件。 它們可能包括FAQ或純粹的非結構化文件,例如 HTML 文件、PDF、純文字或 Microsoft Word 或 Microsoft PowerPoint 。
3.Data sources
我們是否需要手動index documents? 答案是不用; 我們只需向 Kendra 提供資料來源,例如 Confluence server、Microsoft SharePoint、Salesforce sites、ServiceNow instance或 S3 bucket,Kendra 將為文件編制索引,並將資料來源與索引同步以保持相關性和更新。 有關AWS Kendra 支持的source data的完整清單在這裡。
我們可以按內容脈絡或類別(例如某個人創作的文件)來過濾搜索。 我們還可以根據自定義屬性對搜尋到的資料進行排序。 預設排序順序是 Kendra 根據我們的搜索由回應資料的相關性指定的。
通常,當我們搜索某個item時,我們通常不會用確切的名稱。 例如,如果我們正在搜索 Amazon Web Services; 我們可能會用簡寫“AWS”,或使用 Kendra 代替 AWS Kendra。 我們可以在同義詞庫文件中提供 Kendra 的同義詞清單,其中可能包括公司內部第一個字母的簡寫或特定於產業領綠的常用簡寫。
小提示:
Kendra與Comprehend同樣的地方在於他們都有使用到NLP,不同處在於,Kendra只能進行智慧化的文件搜索。而Comprehend能夠使用預訓練或自行訓練的模型來進行情感分析,文件分類,與實體標註。
回顧到現在所介紹的AWS AI/ML服務,在之前關於 AWS Lex 的部分中,我們介紹如何在沒有任何 ML 知識的下在 AWS 上建立聊天機器人應用程式。 我們現在可以使用 Lex 和 Kendra 建立端到端的FAQ解答對談機器人。 Lex 提供了基於話語(utterance)識別使用者意圖的前端,它可以通過將意圖作為輸入傳遞來使用 KendraSearchIntent 呼叫Kendra。 然後,Kendra 可以搜索並傳回聊天機器人顯示的最相關的結果。
AWS Personalize
個人化服務已迅速成為廣泛的垂直領域中無處不在的案例,例如以下範例:
金融服務 一家為客戶提供個人化保險體驗的保險公司提供
電商平台 一家公司為其客戶提供購買或基於客戶搜索歷史的推薦系統
旅遊公司 一家為客戶提供旅行地點、活動或住宿地點建議的公司
媒體和娛樂業務 一家根據其他客戶推薦的下一部片觀看內容的偏好和歷史
Amazon Personalize是一項ML服務,允許企業快速開發個人化推薦系統,為終端客戶提供更好的客戶體驗。從ML的角度來看,所有這些不同的業務問題都有一些共同點。它們都依賴於三種形式的資料:
使用者資料
這可能包括有關使用者年齡、位置、收入、性別、個人偏好和其他人口統計資訊的資料。
商品或服務資料
這是關於公司銷售或試圖推薦的實際產品或服務的資料。
使用者-商品的互動資料
這是關於一組使用者如何與這些商品進行互動的資料,例如他們過去是否購買過這些商品,他們喜歡或不喜歡這些商品,或者他們是否提供了對這些商品的評論或評分。任何個人化服務的目標都是獲取這些資料並提取有意義的見解,從而引導客戶購買產品或服務。
傳統上,這是通過幾種方式完成的:只使用使用者資料,公司會將使用者聚合到相似的群組中並推薦該群組中其他人購買的商品,或者他們將商品聚合到相似的群組中並向使用者推薦”相似已購買商品”或根據”使用者的feedback”。這通常分別稱為clustering和content-based filtering。
還有一種稱為collaborative filtering(協同過濾)的方法,其中使用者-產品互動資料通常用於推薦產品。這個使用者-產品互動資料通常是一個非常大的sparse-matrix(用戶數量產品目數量成正比)。例如,像 Netflix 這樣的公司,擁有數百萬訂閱者(使用者)和數十萬部電影和節目(產品)。協同過濾(collaborative filtering)將大型sparse-matrix分解為更小的矩陣(matrix factorization),以提取每個使用者和每個產品的hidden或latent vectors。這些會積累出最終分數,它決定了是否推薦一個產品。
雖然這是一種非常普遍的技術,但如果我們沒有很多產品,matrix factorization通常運作效果會很差。在這種情況下,我們可以考慮使用其他方法,例如使用 XGBoost 和Factorization machine等模型進行監督式學習。在這邊,我們是根據模型預測使用者購買商品的概率,並推薦概率最高的產品。
Collaborative filtering的缺點之一是它”不納入時間因素”。 它不考慮使用者的購買或對話歷史。 例如,如果我們一個月前在電商平台上購買鞋子,現在對Apple watch感興趣,那麼好的推薦系統可能不應該向我們推薦鞋子。
出於這個原因,科學家們開始使用RNN(recurrent neural networks),它能夠”保留使用者的對話歷史資料作為模型訓練的一部分”。 深入的RNN 架構,可以參考 Balázs Hidasi、Alexandros Karatzoglou、Linas Baltrunas 和 Domonkos Tikk 撰寫的"Session-based Recommendations with Recurrent Neural Networks" 。
AWS的科學家將其進一步擴展到名為 HRNN-Metadata 的模型,該模型使用 RNN 來存儲使用者歷史記錄,還能夠將使用者和產品的metadata作為訓練的一部分。 這使他們不僅可以解決時間歷史問題,還可以同時解決cold start problem — 即推薦者無法向新的使用者推薦產品,詳細介紹可參閱此篇文件。
Multiarmed bandits(MAB)從High level來說,MAB 使用了探勘-開發權衡(exploration-exploitation trade-off)的概念。 目標是在固定數量的步驟後最大化total reward。 在探勘階段,演算法探索可以最大化效益的不同可能組合,記錄每一步的reward以建立reward distribution。 在開發階段,它選擇一個已知的選項來增加overall gain。 當與現行選擇相比,探勘可能會降低收益時,就會出現權衡。 但是,除非我們進行探勘,否則我們將不知道是否還有其他選項可以取代我們當前的選擇。 有關 MAB 的更多詳細資料,可參考此篇文件。
AWS Personalize 是一個 AI 服務,它將個人化的這一領域知識轉化為 Web service,允許客戶將推薦系統構建到他們的應用程式中。 AWS Personalize 採用recipes的概念,針對特定的user case分為三種類型。 Recipes 允許我們在沒有任何先前 ML 知識的情況下建立推薦系統:
User Personalization Recipes
這些recipes有三種。 首先,user-personalization 使用 user-item interaction data並測試不同的推薦場景。 這是推薦的個人化recipe,並使用我們之前討論的exploration-exploitation trade-off來建立。 其次,流行度計數(popularity count)會推薦所有用戶中最受歡迎的item,並且是比較其他recips的良好baseline。 最後,還有一些涉及我們之前討論過的 HRNN 和 HRNN-meta models的傳統方法。
Ranking-Based Recipes
這是一個使用HRNN,但也同時使用排名(ranks)的推薦方式。
Related Item Recipe
這是之前提到的 collaborative filtering 演算法。
除了recipes之外,AWS Personalize 可以識別三種的資料集分別是: user data/item data/interaction data。user 與 item 資料集都屬於 metadata type並且只使用在特定的recipes。詳細的資訊可以參考此篇文件。當AWS personalize使用 HRNN recipes, interaction data需要包含timestamp來辨識其互動的歷史。
使用AWS personalize 建置一個個人化的模型在AWS上稱為solution。當我們上傳資料後,第一步是create 一個solution(會包含一個recipes)。AWS personalize 會根據我們提供的資料而有不同的solution 版本並且會自動切割資料分成訓練(90%資料)/測試(10%資料)。我們可以調整演算法的超參數(hyperparameters)或讓Personalize幫我們代操。然後它將在評估或測試資料集上評估solution版本,但將最舊的 90% 的text data作為input提供給它。 然後,它將根據最新的 10% 的test data評估建議。
模型的效能基於評估指標,例如 Precision at K 和 Mean Reciprocal Rank at K。了解這些指標的含義很重要,以便能夠判斷模型的質量:
更多有關於AWS personalize的其他指標細節,請參閱此篇文件。
Create solution版本後,我們可以建立一個campaign來即時或批次為item評分。 Campaign用於為使用者提供推薦。 Personalize 提供了一個SQL-like的界面,可以即時和批次使用場景中的查詢來過濾推薦。更多關於campaigns的資訊請參閱此文件。
一個常見問題是,當有新的user-item data時,需要多久重新訓練一次模型。對於某些recipes,Personalize 允許我們在推薦中包含real-time event data,而無需每次都重新訓練模型 ,通過將新資料加到我們的user history並使用新資料自動更新模型。更多的基於 real-time event data建立的推薦請參閱此文件。
也就是說,許多客戶會根據他們推薦的新鮮度(或相關性)以某個固定的節奏(每晚、每週)重新訓練他們的模型。 這通常是一個業務性題 — — 在某些產業中,客戶的喜換變化的速度可能比其他產業快得多。 通常,在建立任何 ML使用場景時,我們將希望與相關業務利害關係人合作來回答這些問題。
AWS Personalize 使用一些獨特的術語,並且能夠對應到一般性的資料科學工作流程(如下圖)。
 不明
不明

 iThome鐵人賽
iThome鐵人賽