今天來介紹embedding:
embedding是把文字轉換成一個向量的過程,這樣電腦就可以用數學方式理解它
它可以是一個維度為 n 的數字陣列
例如: "我喜歡拉麵" → [0.12, -0.54, 0.78, ..., 0.03]
因為轉換後的向量具有以下性質:
在 NLP 中,最常見的是 詞嵌入(Word Embedding) 或 句子嵌入(Sentence Embedding)
我利用Sentence-Transformers 的MiniLM-BERT模型(原本設定每個句子384維),全部個句子都各化為2維,參考一下就好~~
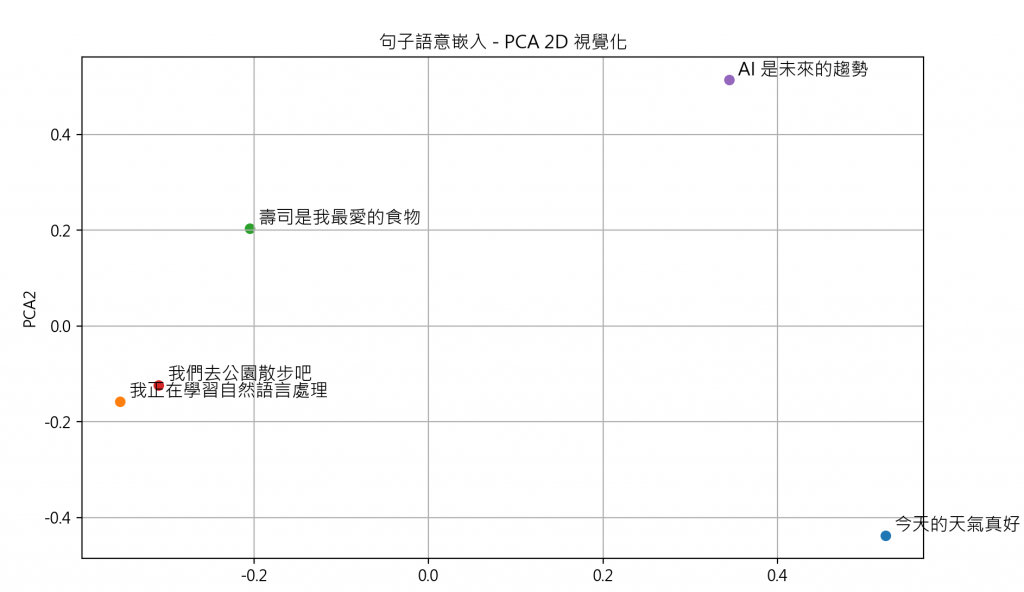
越靠近越相似,可能會是結構相似、語意相似……

