深度學習是機器學習的一個分支,它試圖模仿人類大腦中神經網路的結構和功能來進行學習。所謂的「深 (Deep)」,通常指的就是神經網路的「層數」很多。這些層層堆疊的神經元,能夠自動地、層級化地從數據中學習特徵——淺層的網路學習簡單的特徵(如邊緣、顏色),深層的網路則將這些簡單特徵組合起來,形成更複雜、更抽象的概念(從物體的部件到整個物體)。
感知器是由 Frank Rosenblatt 發明的一種演算法,它可以被看作是史上最簡單的、單層的人工神經元模型。運作流程如下
接收輸入:接收一個或多個輸入值 x_1, x_2, ..., x_n。
加權求和:每個輸入 x_i 都被乘以一個對應的權重 w_i。權重代表了這個輸入的重要性。然後,將所有的加權輸入求和,並加上一個偏置 b。
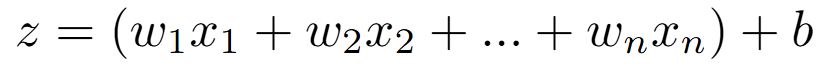
感知器的學習過程,就是透過不斷地調整權重 w 和偏置 b,來使得其輸出結果與真實標籤盡可能一致。然而,單個的感知器有一個致命的缺陷:它只能解決線性可分 (linearly separable) 的問題。
人工神經網路 (Artificial Neural Network, ANN),也常被稱為多層感知器 (Multi-Layer Perceptron, MLP),就是由多個神經元層組成的網路結構。一個典型的 ANN 包含三個部分:
輸入層 (input layer): 接收原始數據。神經元的數量等於輸入數據的維度。
隱藏層 (hidden layers): 介於輸入層和輸出層之間,可以有一層或多層。這些層是真正進行大部分計算和特徵提取的地方。
輸出層 (output layer): 產生最終的預測結果。神經元的數量等於類別的數量。
為了能學習非線性關係,現代神經網路中的激勵函數,也從簡單的階梯函數,演變成了更平滑、更適合梯度計算的函數,例如 sigmoid、tanh、ReLU (Rectified Linear Unit)。
如果像我一樣是 AMD 的用戶,目前仍需要在 Linux 環境下下載 ROCm ,或使用 ZLUDA 才能使用 GPU 進行 PyTorch 的訓練。ROCm 的安裝方式可參考這裡 https://rocm.docs.amd.com/projects/install-on-linux/en/latest/。
安裝完相關前置後,可到 PyTorch 官網,依照使用的環境在終端輸入、下載 PyTorch。
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
# --- 1. 設定超參數與設備 ---
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"將使用設備: {device}")
input_size = 784 # 28x28
hidden_size = 128 # 隱藏層的神經元數量
num_classes = 10 # 0-9 共 10 個類別
learning_rate = 0.001
batch_size = 64
num_epochs = 5
# --- 2. 載入並預處理 MNIST 數據集 ---
# 定義數據轉換
transform = transforms.Compose([
transforms.ToTensor(), # 將圖片轉換為 Tensor
transforms.Normalize((0.1307,), (0.3081,)) # 標準化 (使用 MNIST 的均值和標準差)
])
# 下載訓練集和測試集
train_dataset = datasets.MNIST(root='./data', train=True, transform=transform, download=True)
test_dataset = datasets.MNIST(root='./data', train=False, transform=transform, download=True)
# 建立數據載入器
train_loader = DataLoader(dataset=train_dataset, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(dataset=test_dataset, batch_size=batch_size, shuffle=False)
# --- 3. 定義神經網路模型 ---
class NeuralNet(nn.Module):
def __init__(self, input_size, hidden_size, num_classes):
super(NeuralNet, self).__init__()
# 定義網路的層
self.fc1 = nn.Linear(input_size, hidden_size) # 輸入層 -> 隱藏層
self.relu = nn.ReLU() # ReLU 激活函數
self.fc2 = nn.Linear(hidden_size, num_classes) # 隱藏層 -> 輸出層
def forward(self, x):
# 定義數據的前向傳播路徑
out = self.fc1(x)
out = self.relu(out)
out = self.fc2(out)
return out
# 建立模型實例並移至指定設備
model = NeuralNet(input_size, hidden_size, num_classes).to(device)
# --- 4. 定義損失函數與優化器 ---
criterion = nn.CrossEntropyLoss() # 交叉熵損失,適用於多分類問題
optimizer = optim.Adam(model.parameters(), lr=learning_rate) # Adam 優化器
# --- 5. 訓練模型 ---
print("開始訓練...")
for epoch in range(num_epochs):
for i, (images, labels) in enumerate(train_loader):
# 將數據攤平成 (batch_size, 784) 並移至設備
images = images.reshape(-1, 28*28).to(device)
labels = labels.to(device)
# 前向傳播
outputs = model(images)
loss = criterion(outputs, labels)
# 反向傳播與優化
optimizer.zero_grad() # 清除之前的梯度
loss.backward() # 計算梯度
optimizer.step() # 更新權重
if (i+1) % 100 == 0:
print(f'Epoch [{epoch+1}/{num_epochs}], Step [{i+1}/{len(train_loader)}], Loss: {loss.item():.4f}')
print("訓練完成!")
# --- 6. 評估模型 ---
# 將模型設為評估模式 (這會關閉 Dropout 等層)
model.eval()
with torch.no_grad(): # 在此區塊中,不計算梯度,節省記憶體
correct = 0
total = 0
for images, labels in test_loader:
images = images.reshape(-1, 28*28).to(device)
labels = labels.to(device)
outputs = model(images)
# torch.max 會回傳最大值和其索引
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print(f'模型在 10000 張測試圖片上的準確率: {100 * correct / total:.2f} %')
結果
模型在 10000 張測試圖片上的準確率: 97.44 %


 iThome鐵人賽
iThome鐵人賽