今天要來學習網頁爬蟲,我是跟著yt的影片一步步操作(連結放置下面的資料來源),以Books to Scrape這個免費練習爬蟲的網頁來學習如何在n8n操作。
網路資訊非常多樣,且資訊幾乎都在網頁上,然而問題是:
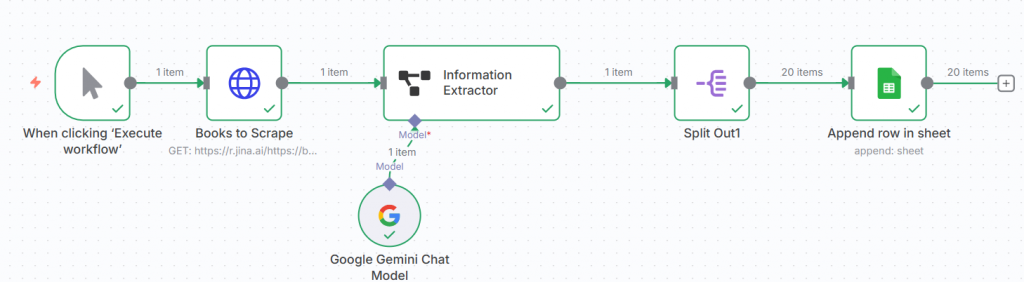
將網站某一頁的20筆資料進行scrape,並且進到每個書籍詳細頁面把資料抓出來放進google sheet。
使用jina.ai網站取得網頁的api,複製所生成的代碼
💡Jina AI公司提供一個好用免費開源工具 Reader API ,只要在想要解析的網址前加上https://r.jina.ai/ 就能直接取得該網頁的純文字內容。這個功能對爬蟲來說非常實用!
建立HTTP Request節點
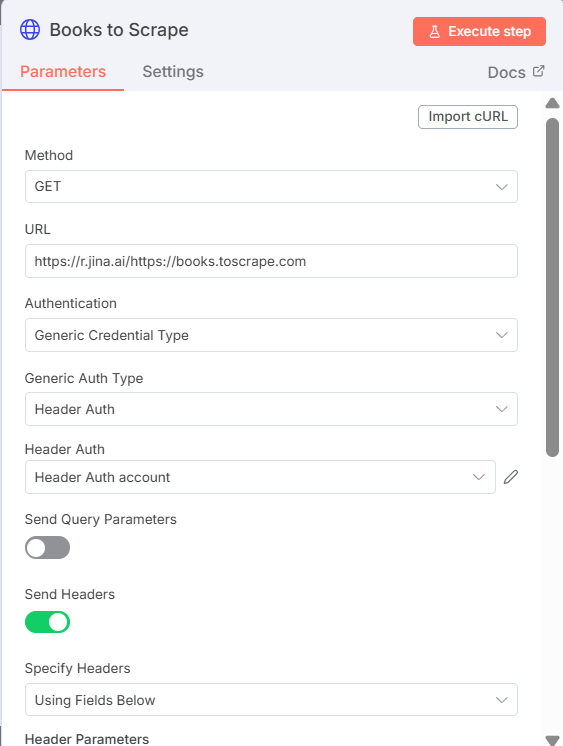
建立Information Extractor節點,並接上gemini
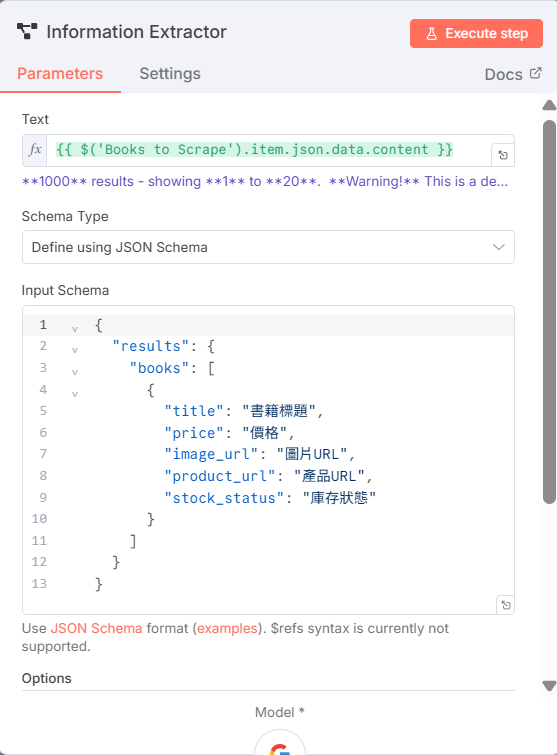
建立split out節點(重要的一個步驟)
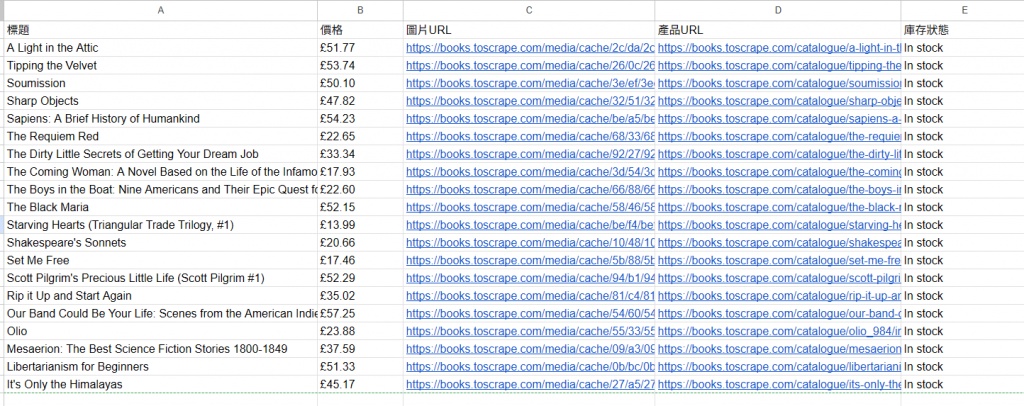
建立google sheet節點
https://jina.ai/
https://books.toscrape.com/
https://www.koc.com.tw/archives/542920
https://youtu.be/FhSJJVREZec?si=zddjxUEtI1S-QB9I
https://youtu.be/y_awxPv3bfY?si=UT0YdctLSZdxthth


 iThome鐵人賽
iThome鐵人賽