在前一篇文章,利用一個免費的爬蟲練習網站來用n8n抓取網頁資料,其中學到如何設置HTTP Request節點與split out節點,今天要嘗試另一種做法,以HTML擷取,因此需要找到CSS selector。以這個方式比較可以適用於其他網站。這次一樣是從YT影片做學習。
在寫爬蟲時,CSS Selector 是一個非常實用的工具。它原本是前端用來指定網頁元素並加上樣式的語法,但在爬蟲裡,我們用它來精準找到要抓的資料。
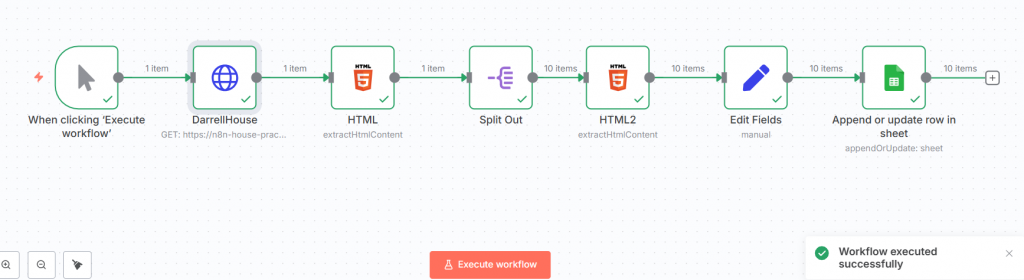
主要流程是建立HTTP Request→整理HTML取得CSS Selector→存進檔案
建立HTTP Request節點
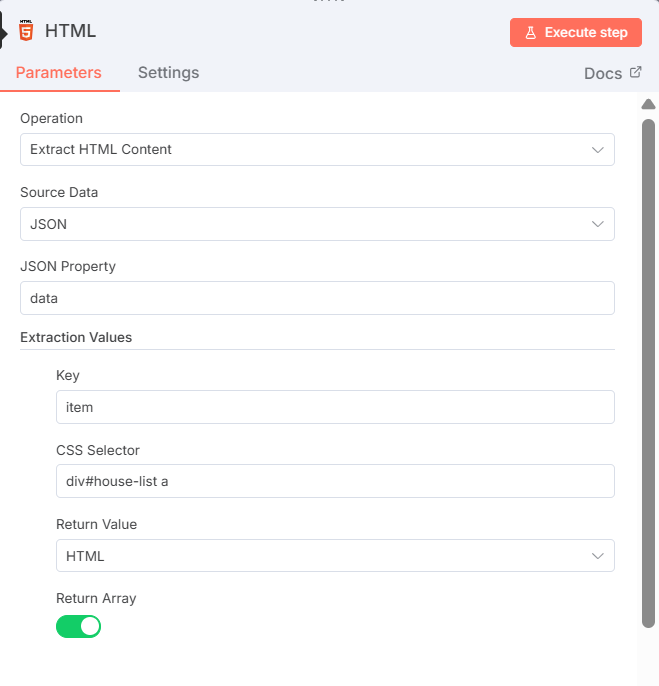
建立HTML節點,選用Extract HTML Content功能
建立split out節點
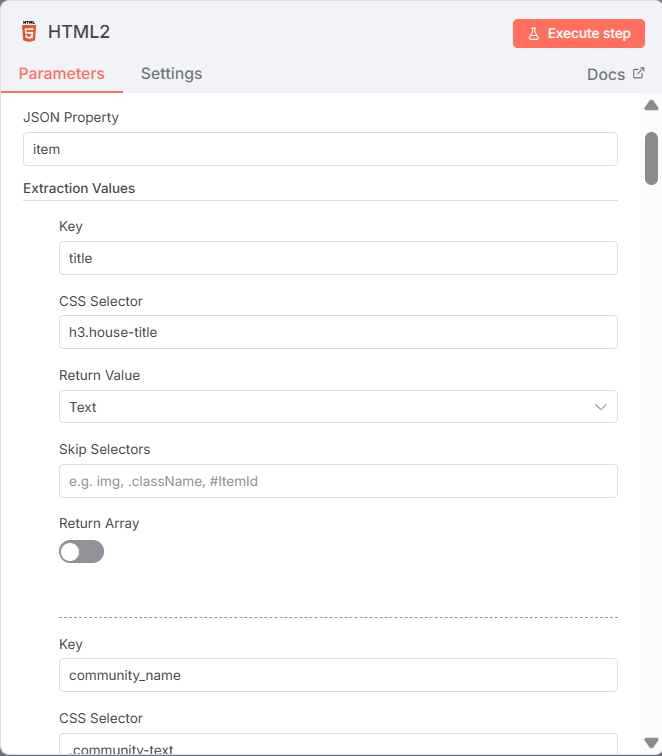
建立第二個HTML節點,選用Extract HTML Content功能
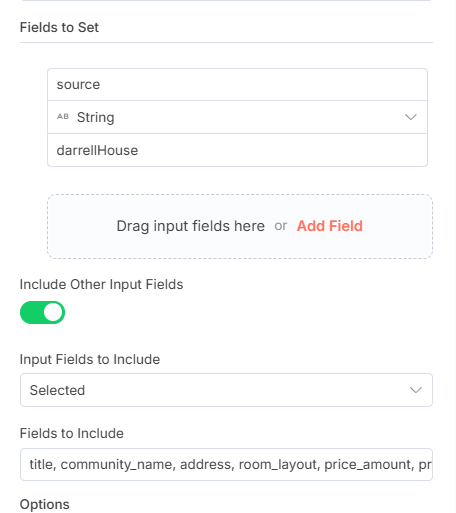
建立Edit Fields節點
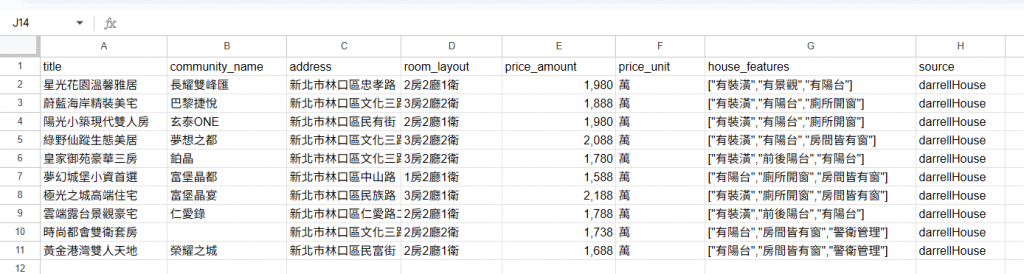
建立google sheet節點 https://docs.google.com/spreadsheets/d/1XzmNiw4FGyeRyehxBkGdkFOtnREs3delcX4MWbZC4ro/edit?usp=sharing
https://n8n-house-practice.darrelltw.com/
https://youtu.be/pfd9YSh5eJ8?si=_5D5HbBeLeXY035T

