前情提要
昨天分步驟講解如何實作 self-attention,如果照著步驟依序思考,相信你應該了解大概。
參考文章: https://www.cnblogs.com/rossiXYZ/p/18759167
1. 複習 & 總結
昨天練習完程式你可能會有一個疑問,說好的**加權求和呢?? **怎麼在 code 裡面沒看到類似的地方。
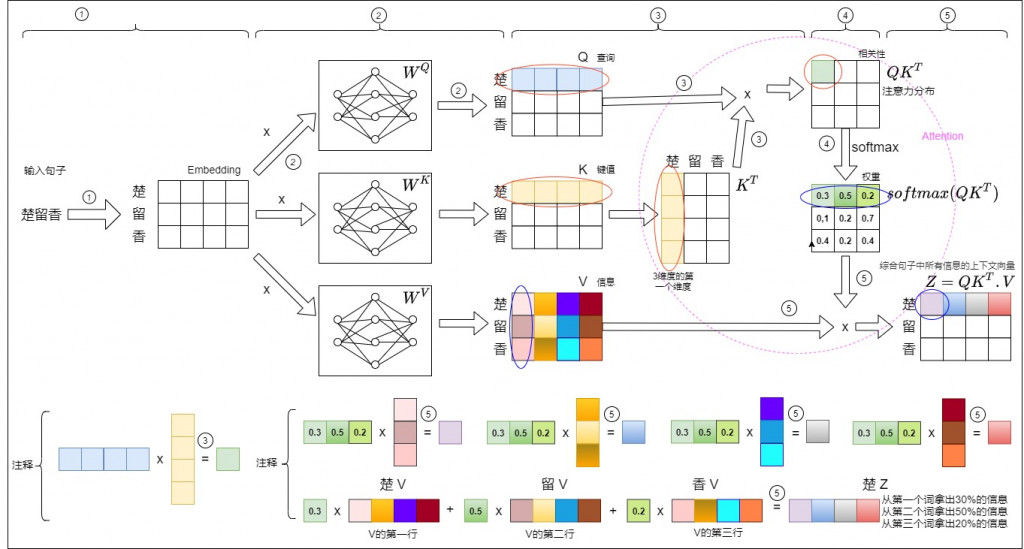
讓我們用下面這張圖做一個總結,圖片一樣來自於參考文章,讓我們分步驟了解下圖。
- tokenizer + nn.embedding: 楚留香 → ["楚", "留", "香"] → embedding
- x 經過線性轉換(nn.Linear) (WQ, WK, WV 是 linear 的 weight 矩陣) → Q, K, V
- q, k_T 做內積(運算: 一行藍色 內積 一列黃色 → 得到一個綠色), 但我們直接用 torch.matmul 得到整個矩陣結果, 而不用自己一行一列算
- 經過 softmax 將 attn scores → attn weights
- 加權求和在這 → 可以看最下面注釋的圖 (0.3 x 楚v + 0.5 x 留v + 0.2 x 香v),一樣我用透過 torch.matmul 得到整個矩陣結果,所以才無法直觀看出來加權求和
2. MHA 觀念
昨天講解及今天複習的 self-attention 只針對單獨某個向量空間而已,但這樣子難以有效的反應我們人類注意力的機制,比如說打場遊戲,眼睛看的視覺,手動的觸覺,耳朵的聽覺等等,我們是可以同時處理多個方面的訊息,所以接下來介紹的 Multi-head attention ,出發點是希望模型可以透過不同觀點或角度來分析和理解輸入的訊息,最終輸出包含不同子空間中的編碼訊息,從而增強模型的表達能力。
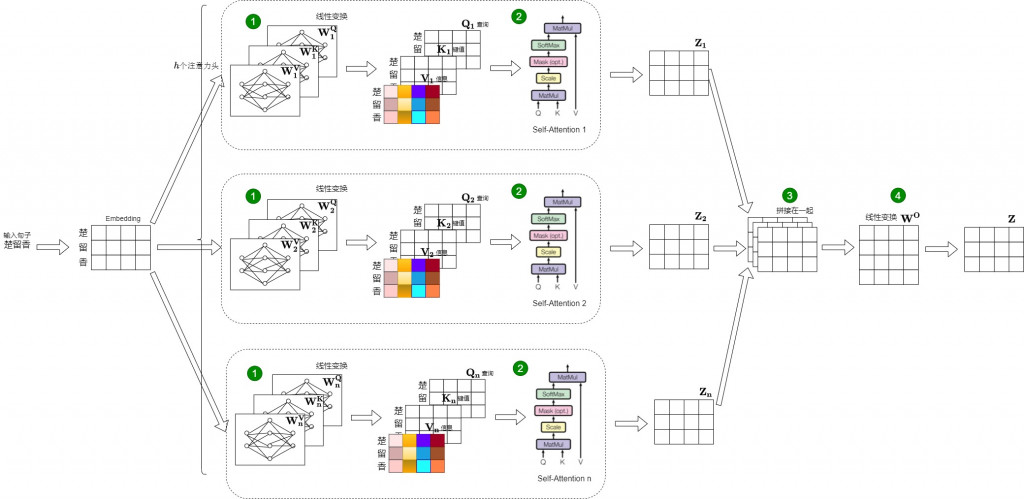
核心觀念: 一組 Q, k, V → 多組 Q, K, V → 多觀點處理事情
沒錯楚留香又來了,可以跟上面的圖做一些比較(大家來找碴)
- 最前面多了切割,圖出分成 3 個子空間
- 從 WQ, WK, WV → [(WQ_1, WK_1, WV_1), (WQ_2, WK_2, WV_2), (WQ_3, WK_3, WV_3)]
- 多了合併的步驟
- 最後多一個 WO 最線性轉換
理解:
- 透過 multi-head 將輸入的 embedding 做切割有助於學習
ex: 可以想像一個攝影師拍一張圖片,要顧局全部的細節是很難的,但如果分成八個攝影師,每個攝影師專注照一部分,最後再合併,那是不是效果就會不錯。
- Q: 剛開始會有點疑惑,因為 self-attention 和 multi-head attention 都是使用三個 linear,參數量一樣那有甚麼區別?
A: self-attention 和 Multi-head attention 都使用三個 Linear 層來產生 Query、Key、Value,理論上參數量可以相同。但 Multi-head attention 將 hidden size 分成多個子空間(即多個 head),每個 head 各自進行注意力計算,最後再將所有 head 的輸出拼接起來再做一次線性轉換。因此即使參數量一樣,也能學到更豐富、更有表達力的表示。
- 雖然圖上看起來是分成很多個 head 做 loop 計算,但其實只需要單一的矩陣運算就好
分步驟講解
以下圖為了方便講解,所以作者並沒有將 batch size 一起畫,圖片來源皆來至於: https://medium.com/data-science/transformers-explained-visually-part-3-multi-head-attention-deep-dive-1c1ff1024853
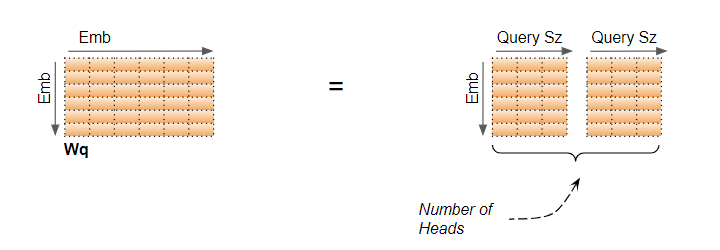
- WQ_1 是怎麼來的,他是由 WQ (線性變換的權重) 依照 head 的數量被 "邏輯上的切分",為甚麼是邏輯呢?? 因為我們寫 code 的時候不用真的宣告多個切割完的 linear,切分會表示在運算上。
圖中的 Emb 就是宣告 nn.Linear 裡面的維度,前面我們是用 hidden_size。
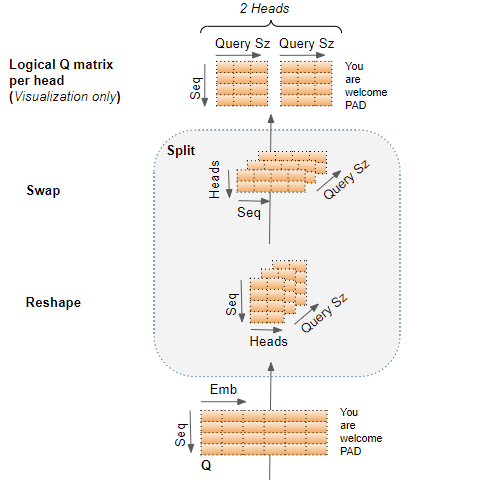
- 接下來看輸入怎麼做切割
像步驟1一樣,對 emb 照著 head 的數量做切割,得到 Query Sz(Logical Q matrix per head 右邊的圖),然後想像把它疊在一起 (對應Reshape 右邊的圖),之後我們交換一下順序 (對應 Swap 右邊的圖)
- 這裡我先把整個流程放上來,可以清楚看到步驟2就是 split 那個 block 的操作,之後計算 attention score 的部分就跟之前一樣囉
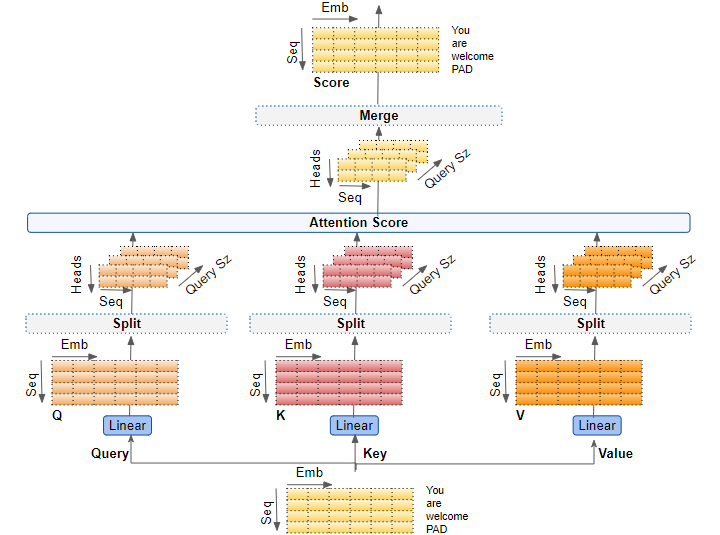
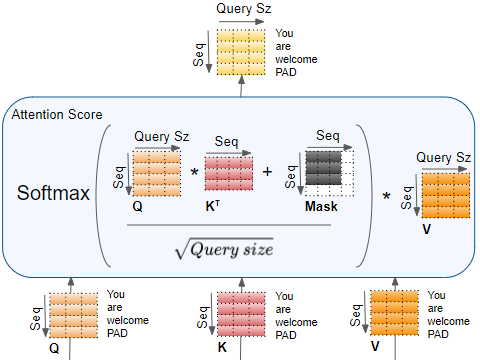
- 這部分運算就跟 self attention 一樣,不過要小心分母是 Query size 的根號,那下圖還有一個 mask,這個我們後續會講到它的作用,這裡可以先看看就好。
- 最後就會 merge 多頭做出來的結果,再經過 WO 輸出回原先輸入的 shape
今天主要是將昨天觀念再加強,然後加入點新觀念,怕篇幅太長大腦已經過載,所以就將程式擺到明天,今天就先到這裡囉~


 iThome鐵人賽
iThome鐵人賽