Hi大家好,
這是我參加 iT 邦幫忙鐵人賽的第 1 次挑戰,這次的主題聚焦在結合 Python 爬蟲、RAG(檢索增強生成)與 AI,打造一套 PTT 文章智慧問答系統。在過程中,我會依照每天進度上傳程式碼到 GitHub ,方便大家參考學習。也歡迎留言或來信討論,我的信箱是 gerryearth@gmail.com。
當你開始將爬蟲任務交由 Celery 背景執行時,或許已經發現:當程式出錯或資料異常時,除錯變得不再直觀。
尤其是當爬蟲任務規模逐漸擴大、板塊變多,我們更需要一個有系統的方式來記錄每次執行的狀況。
今天,我們要來為爬蟲任務加入「執行日誌(Log)」功能,讓每次任務的成功與失敗都能被紀錄在資料庫中,方便後續的監控與除錯。
Log 模型,記錄每次爬蟲任務的執行結果為了方便管理日誌(Log),我們建立新的 app 叫做 log_app (因為 log 是常用保留詞):
python manage.py startapp log_app
記得在
settings.py的INSTALLED_APPS加上log_app
並在 log_app/models.py 中新增 Log 資料表:
from django.db import models
class Log(models.Model):
level = models.CharField(max_length=100)
category = models.CharField(max_length=100)
message = models.TextField()
traceback = models.TextField(null=True, blank=True, default=None)
created_at = models.DateTimeField(auto_now_add=True)
def __str__(self):
return f'{self.level} - {self.created_at}'
記得遷移資料庫!
先進入 Docker 的 Django ,再遷移資料庫:docker exec -it django_web /bin/bashpython manage.py makemigrations python manage.py migrate
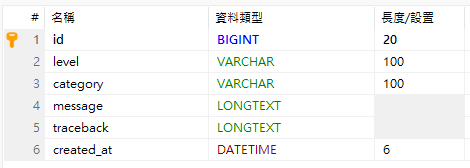
資料庫遷移後就可以得到 log_app:
| 欄位名稱 | 資料型別 | 長度 | 說明 |
|---|---|---|---|
| id | BIGINT | 20 | 主鍵,自動遞增 |
| level | VARCHAR | 100 | 層級 |
| category | VARCHAR | 100 | 訊息處分類 |
| message | LONGTEXT | X | 訊息 |
| traceback | LONGTEXT | X | 錯誤詳細內容 |
| created_at | TIMESTAMP | 6 | 發生時間 |
我用
category分類日誌內容:
- scrape - board (爬蟲的版面)
- user - api (使用者使用的 API)
打開 celery_app/scraper.py,將原來的 ptt_scrape 改成如下:
from log_app.models import Log
import traceback
def ptt_scrape(board: str) -> list:
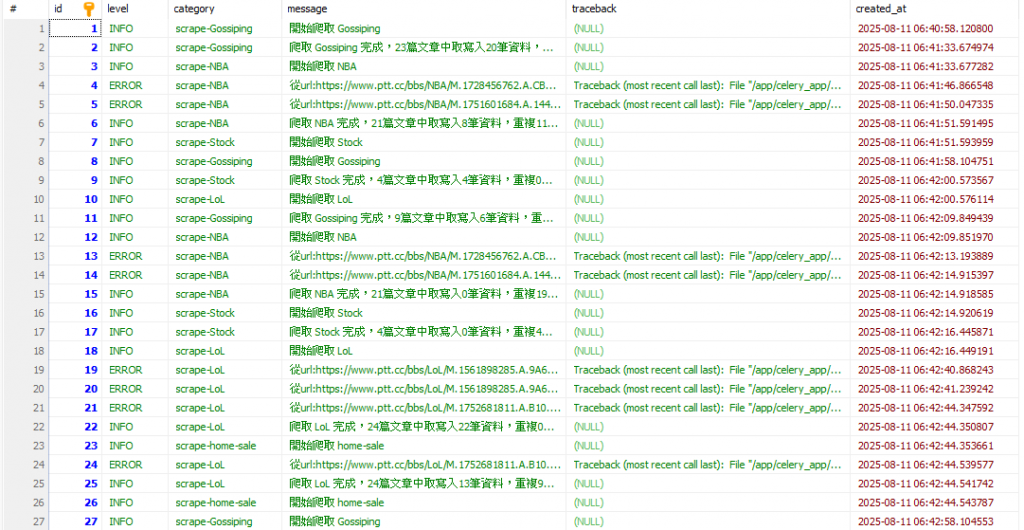
Log.objects.create(level='INFO', category=f'scrape-{board}', message=f'開始爬取 {board}')
board_url = 'https://www.ptt.cc/bbs/' + board + '/index.html'
board_html = get_html(board_url)
article_urls = get_urls_from_board_html(board_html)
article_id_list = []
num_of_same_article = 0
for article_url in article_urls:
if Article.objects.filter(url=article_url).exists():
num_of_same_article += 1
continue
article_html = get_html(article_url)
try:
article_data = get_data_from_article_html(article_html)
except Exception as e:
Log.objects.create(level='ERROR', category=f'scrape-{board}',
message=f'從url:{article_url}取得data失敗: {e}',
traceback=traceback.format_exc())
continue
try:
article = Article.objects.create(
board=board,
title=article_data["title"],
author=article_data["author"],
url=article_url,
content=article_data["content"],
post_time=article_data["post_time"]
)
article_id_list.append(article.id)
except Exception as e:
Log.objects.create(level='ERROR', category=f'scrape-{board}',
message=f'{article_url}Data插入資料庫錯誤: {e}',
traceback=traceback.format_exc())
Log.objects.create(level='INFO', category=f'scrape-{board}',
message=f'爬取 {board} 完成,{len(article_urls)}篇文章中取寫入{len(article_id_list)}筆資料,重複{num_of_same_article}筆資料')
return article_id_list
為什麼這麼做?
- 任務背景執行時,除錯較不方便
- 有 Log 可以追蹤爬蟲是否運作正常
- 未來可擴充 Log 欄位紀錄執行篇數、版面、錯誤類型等資訊
明天【Day13】Django REST Framework 入門介紹 - 打造高彈性 RESTful API 的利器,會讓大家了解什麼是 Django REST Framework(DRF),為專案的 API 實作打下基礎。


 iThome鐵人賽
iThome鐵人賽