這幾天Gemini生成Colab檔案時,有附帶SOP步驟:
1. 安裝 mlxtend 函式庫
2. 接著建立一個簡單的交易資料集,代表不同顧客的購物籃內容。
3. 將交易資料轉換成適合 mlxtend 處理的格式,也就是一個 One-Hot 編碼的 DataFrame。
4. 使用 Apriori 演算法找出頻繁項目集 (Frequent Itemsets)。
5. 最後根據頻繁項目集找出關聯規則。
現在將昨天 ChatGPT 生成的其中10筆資料:
奶酥葡萄乾貝果, 藍莓乳酪, 奧利奧巧克力貝果, 濃心藍莓乳酪貝果
果漬藍莓鹽可頌, 濃心藍莓乳酪貝果
起司乳酪, 絲絨卡士達貝果
雙倍起司貝果, 藍莓乳酪
芝麻芋頭貝果, 流心芝麻, 絲絨卡士達貝果, 果醬藍莓貝果
濃郁巧克力貝果, 濃心蔓越莓乳酪貝果, 紅茶奶酥貝果, 蔓越莓卡士達貝果
生乳皇后吐司, 巧克力花生, 奧利奧巧克力貝果
爆漿巧克力, 藍莓乳酪, 果漬藍莓鹽可頌, 濃心藍莓乳酪貝果
濃郁巧克力貝果, 果醬葡萄乾鹽可頌
果香芝麻貝果, 藍莓乳酪, 濃心蔓越莓乳酪貝果, 濃心藍莓乳酪貝果
丟到 Colab 給 Gemini,請他替換資料
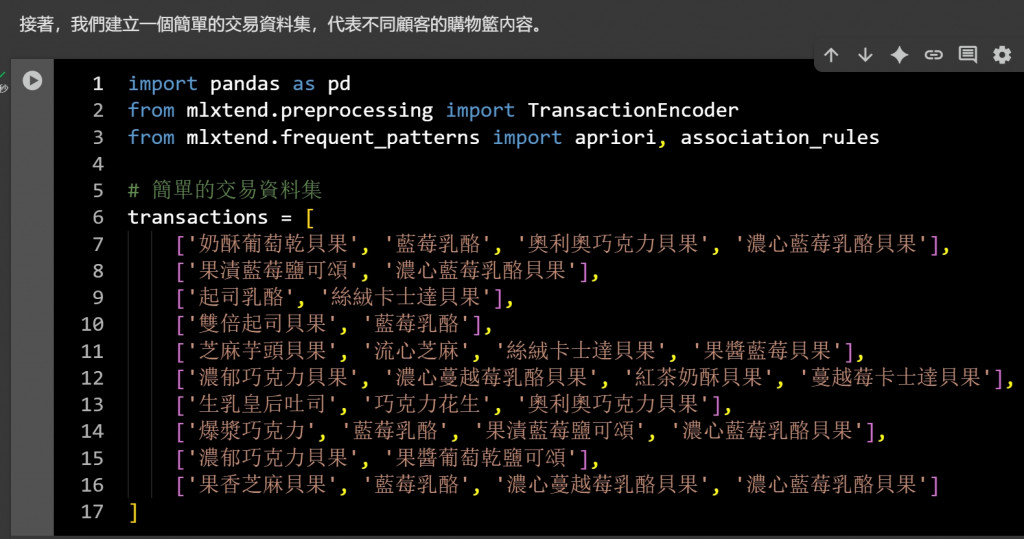
確定 transactions 資料換成新的後,按下全部執行前,可以請 Gemini 依照目前的需求調整一下
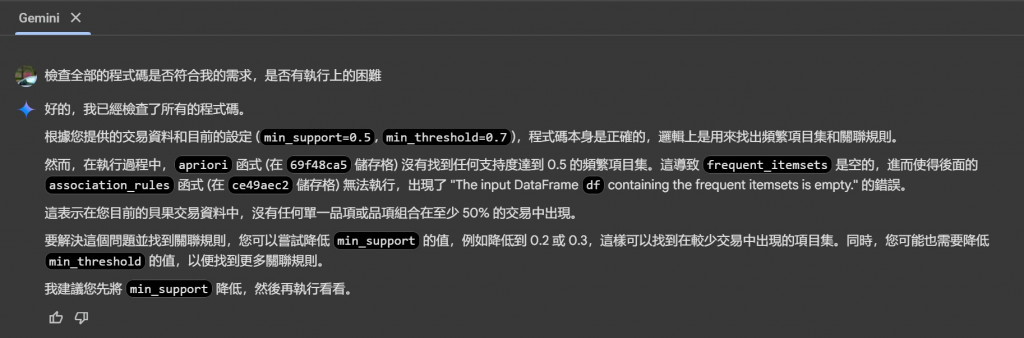
(依照Gemini的建議,要降低 min_support=0.5, min_threshold=0.7 的值,就改成 min_support=0.3, min_threshold=0.5 後,再執行)
這次導出一個結果就是"藍莓乳酪, 濃心藍莓乳酪貝果"是這次預設的資料集裡面最常一起出現,也就是說,如果消費者購買藍莓乳酪時,可以推薦濃心藍莓乳酪貝果給他

