
在《為什麼我改用 Iceberg》系列中,我從成本與效能的角度,說明了將 Google BigQuery 替換為 Trino + Iceberg on S3 的原因,並介紹了 Iceberg 的兩大特點:基模演進 與 增量查詢。
接下來的《Trino + Iceberg ELT 實作》系列,將分別從實作步驟、框架轉換過程中遇到的問題、以及 資料驗證方法 等面向,詳細解析替換 ELT 排程的完整過程。
之前都較著重於官方文件的說明。在進入 ELT 實作之前,筆者想先總結這次架構轉換專案的背景與原因,接著介紹公司現行的 ELT 架構,並進一步說明轉換前後的差異。

上表筆者對於 Trino + Iceberg on S3 與 Google BigQuery 的比較做了總結,主要是以企業用戶思考架構選行的角度去切入,例如:架設與維運的難度、查詢的效能、可擴展性、可併發性、成本以及使用場景的考慮。
對於創業初期的公司而言,為了快速達到客戶需求並且完善自家功能,完全託管的架構便是一個好選擇。
然而公司發展到了穩定期便要開始思考如何在不降低對客戶的服務品質的條件下,還能降低企業成本,這時候自建、開源之類的產品就對老闆們產生了很大的吸引力。
另外,除了成本之外還有一個很重要的因素,也就是 *供應商箝制 (Vendor lock),過度依賴特定供應商的產品或服務對公司來說都不是太好的消息。
*供應商箝制 (Vendor lock)
一旦你採用某個雲端服務或軟體平台後
因為它的 專屬技術、封閉標準 或 強烈整合,會讓你很難、或付出極高成本才能轉移到其他供應商。
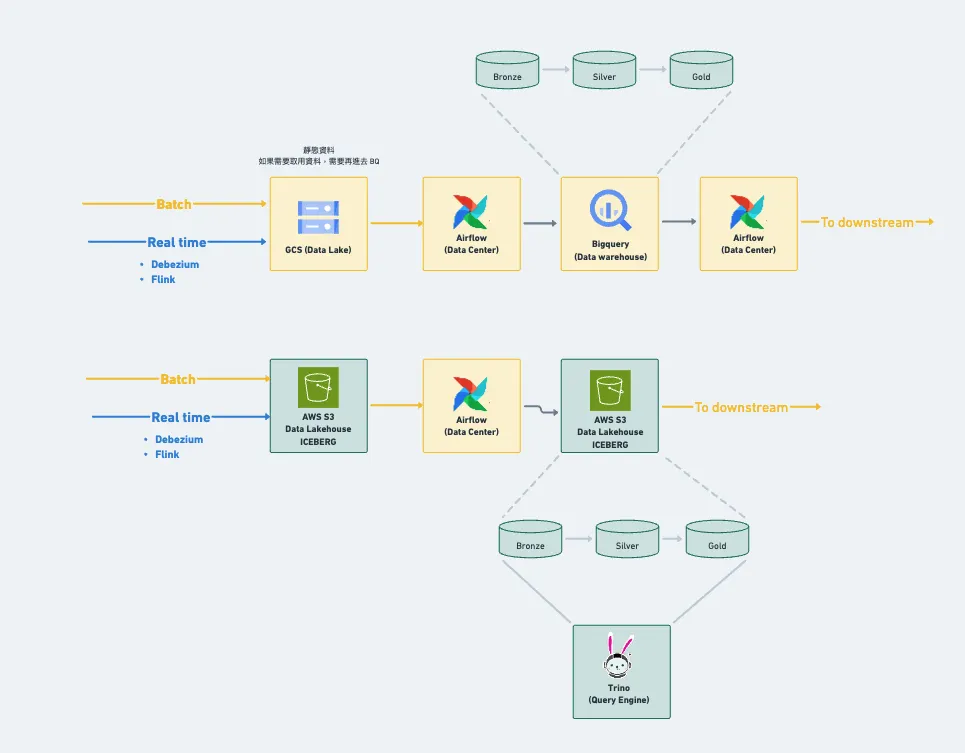
此專案啟動之主因在於長期依賴 Google 原生 BigQuery,使整體分析架構過度綁定於 Google 生態系,缺乏靈活性。
同時,筆者公司主要基礎設施多建置於 Amazon 環境 (以 EKS 管理的 EC2 節點為主),而在 BigQuery 的使用量相對有限,因此難以與 Google 談到更具競爭力的折扣方案。
因此,將 ELT 流程中的分析架構使用開源軟體置換這個點子便萌發了,上圖上半部是筆者公司舊的 ELT 架構,儲存使用 Google 原生的 GCS、ELT 使用 BigQuery 做運算,並同時當作分析倉儲使用。
上圖下半部是置換成 Trino + Iceberg on S3 後的樣子,儲存置換成 Amazon 原生的 S3、運算改用 Trino 伸手對 Iceberg 做處理。
看到這邊讀者可能會疑惑,上節的架構圖無論新舊,皆顯示了 ELT 分成Bronze Silver Gold 三個階段,這到底是什麼緣故?
解釋之前,必須先說明架構圖上所提到的 ELT 流程:
而為何 Transform 這步驟需要將資料分成 Bronze Silver Gold 三個階段做處理呢?原因是這樣的資料 分層設計 有幾個好處:
Silver 資料,減少 邏輯重複 與 重複資料衍生出來的 維運成本。Silver,儀表板則用 Gold ) 。明日《Trino + Iceberg ELT 實作 (二)》將延續今日介紹之 ELT 三層架構,繼續說明 end-to-end 的 ELT 搬遷實作流程。
My Linkedin: https://www.linkedin.com/in/benny0624/
My Medium: https://hndsmhsu.medium.com/


 iThome鐵人賽
iThome鐵人賽