⚡《AI 知識系統建造日誌》這不是一篇純技術文章,而是一場工程師的魔法冒險。程式是咒語、流程是魔法陣、錯誤訊息則是黑暗詛咒。請準備好你的魔杖(鍵盤),今天,我們要踏入魔法學院的基礎魔法課,打造穩定、可擴展的 AI 知識系統。
昨天我們剛讓 RAG API 上線,系統終於能回應問題,算是把魔法陣刻在地板上了。
但問題來了——光有咒語,卻沒人聽見,不就等於在黑暗森林裡自言自語?
所以今天我們要升級,把「知識」包裝成每日快遞,送到每個訂閱者的信箱。這不只是寄封信那麼簡單,而是一次大型魔法實驗:
今天的任務,就是讓這整套流程能「自己動起來」,而不是靠工程師半夜手動按下傳送鍵。
若你錯過前情,可以先看看這幾篇:
Day 8|Email Pipeline 技術拆解(上) - 打造訂閱系統
Day 9|Email Pipeline 技術拆解(下) - 打造訂閱系統
Day 13|資料管線魔法進階:Prefect 架構與自動化全解析(下)
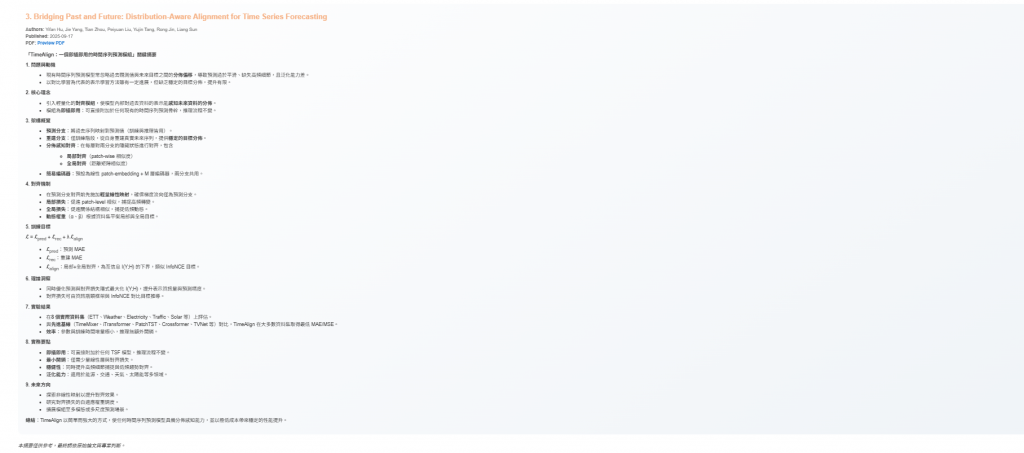
今天要讓它變成 可以按時執行。核心程式碼 pipeline.py 不會特別說明
容器設定
services:
email-flow:
build:
context: .
dockerfile: ./services/emailservice/Dockerfile.email
image: email-flow:latest
container_name: email-flow
command: bash /app/deploy_flows.sh
environment:
PREFECT_API_URL: http://orion:4200/api
volumes:
- ./email:/app
env_file:
- .env
networks:
- ai-net
orion:
image: prefecthq/prefect:3-latest
container_name: prefect-orion
command: prefect server start --host 0.0.0.0 --port 4200
ports:
- "4200:4200" # Web UI + API
environment:
PREFECT_API_DATABASE_CONNECTION_URL: sqlite+aiosqlite:///prefect.db
volumes:
- ./data/prefect_data:/root/.prefect
networks:
- ai-net
Dockerfile.email
# --- 基礎映像 ---
# FROM python:3.11-slim
FROM prefecthq/prefect:3.4.18-python3.10-conda
# --- 工作目錄 ---
WORKDIR /app
# --- 安裝系統依賴 ---
RUN apt-get update && apt-get install -y --no-install-recommends \
build-essential \
git \
curl \
&& rm -rf /var/lib/apt/lists/*
# --- 複製依賴檔案 ---
COPY services/emailservice/requirements.txt ./requirements.txt
# --- 安裝 Python 套件 ---
RUN pip install --no-cache-dir --upgrade pip
RUN pip install --no-cache-dir -r requirements.txt
# --- 複製程式碼 ---
COPY ./email /app
# 預設 command 可以空著,由 docker-compose override
CMD ["bash"]
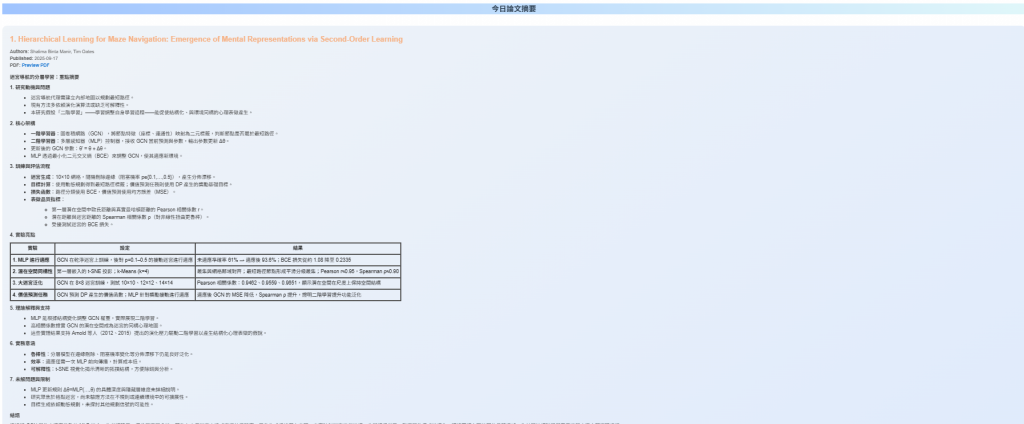
pipeline
# ----------------------
# Flow
# ----------------------
@flow(name="Daily Subscribe Flow")
def daily_papers_flow(top_k: int = 3):
# 初始化 Firebase
cred = firebase_admin.credentials.Certificate(
f"{FIREBASE_KEY_PATH}/serviceAccountKey.json"
)
firebase_admin.initialize_app(cred)
logger = get_run_logger()
start_flow = time.time()
logger.info("Daily Subscribe Flow started")
# Fetch all subscribed user emails, user_id, translate, and user_language
users = get_users_task()
papers = fetch_papers_task()
if not papers:
logger.info("No new papers found, skipping flow")
return
content_map = fetch_paper_content_task(papers)
for user in users:
user_unsent_papers = filter_already_sent_papers(
user["user_id"], papers
) # 返回 dict list
logger.info(f"user {user['user_id']}")
logger.info(f"user_unsent_papers {len(user_unsent_papers)}")
if not user_unsent_papers:
logger.info(f"user {user['user_id']} - All papers have been sent, skipping")
continue
# 打亂順序
random.shuffle(user_unsent_papers)
# 取 top_k
assigned_papers = user_unsent_papers[:top_k]
logger.info(f"got top_k {top_k} paper, sorest paper {len(assigned_papers)}")
# 發送給使用者
result = process_user_task(user, assigned_papers, content_map)
logger.info(result)
logger.info(f"Daily Subscribe Flow completed in {time.time() - start_flow:.2f}s")
執行流程概覽(文字流程圖)
[Developer] ──> 編寫 Flow / Task
│
▼
[Flow] ──> 定義 Task 執行順序與依賴
│
▼
[Task] ──> 執行實際邏輯(抓資料 / 解析 / 索引)
│
▼
[Orion] ──> 記錄每次 Flow Run 與 Task 狀態、日誌、結果
Flow / Task/ Orion 介紹過了,來說說 deploy_flows.sh 、 建立 Queue 、 註冊 Flow
負責 註冊 Flow 並設定 排程。
from pipeline import daily_papers_flow
from prefect.schedules import Cron
# 建立 Interval schedule
# 每天 06:00 台北時間 (等於 UTC 22:00)
interval_schedule = Cron("0 22 * * *", timezone="UTC")
daily_papers_flow.serve(
schedule=interval_schedule,
parameters={"top_k": 3},
)
自動化部署腳本,流程如下:
#!/bin/bash
set -e
# 等待 Orion 啟動
echo "Waiting for Orion API..."
until curl -s http://orion:4200/api/health | grep "true"; do
echo -n "."
sleep 2
done
echo "Orion is ready ✅"
# 印 Prefect 版本
prefect version
# 建立 Work Pool / Queue
prefect work-pool create default --type process || true
prefect work-queue create email-queue --pool default || true
# 部署 flow
echo "Deploying flows..."
python /app/prefect_entrypoint.py
├── deploy_flows.sh # deploy flow
├── prefect_entrypoint.py # flow.serve 註冊 flow 並套用 schedule
├── config.py # Configuration settings (API keys, DB connections, environment variables)
├── pipeline.py # Main pipeline orchestrating the process of fetching, summarizing, and emailing papers
├── logger.py # Centralized logging utilities
├── serviceAccountKey.json # Firebase service account credentials for authentication
│
├── services/ # Core services for fetching, processing, and delivering papers
│ ├── embedding.py # Functions for generating embeddings from paper text
│ ├── fetch_new_papers.py # Fetch newly published papers from source (e.g., ArXiv API)
│ ├── fetch_paper_content.py # Retrieve and parse the full content of papers
│ ├── filter_already_sent_papers.py # Filter out papers that have already been sent to users
│ ├── generate_summary.py # Generate summaries of papers using LLM
│ ├── get_subscribed_users.py # Fetch the list of subscribed users from Firebase/DB
│ ├── get_user_email_from_firebase.py# Retrieve user email addresses from Firebase
│ ├── langchain_client.py # Wrapper for interacting with LangChain (LLM interface)
│ ├── prompt_template.txt # Prompt template used for LLM summarization
│ ├── record_sent_papers.py # Log and persist which papers have been sent
│ ├── send_email.py # Utility to send emails with paper summaries to users
│ └── template.html # HTML template for summary emails
│
└── storage/ # Storage and persistence layer
├── __init__.py # Package initialization
├── minio.py # MinIO client for storing PDFs or assets
├── model.py # ORM models or schema definitions for stored entities
├── qdrant_client.py # Qdrant client for managing vector storage (embeddings, similarity search)
├── storage_metrics.py # Metrics/logging for storage operations
└── wait_minio.py # Utility to wait for MinIO service readiness before startup
Pipeline Layer (pipeline.py)
Services Layer (services/)
embedding.py)template.html)Storage Layer (storage/)
minio.py)qdrant_client.py)model.py)storage_metrics.py)wait_minio.py)Configuration & Utilities (config.py, logger.py, serviceAccountKey.json)
到這裡,我們已經完成一個能 自動運轉的每日知識快遞服務:


 iThome鐵人賽
iThome鐵人賽