⚡《AI 知識系統建造日誌》這不是一篇純技術文章,而是一場工程師的魔法冒險。程式是咒語、流程是魔法陣、錯誤訊息則是黑暗詛咒。請準備好你的魔杖(鍵盤),今天,我們要踏入魔法學院的基礎魔法課,打造穩定、可擴展的 AI 知識系統。
延續昨天的資料管線架構介紹,若你錯過前情,可以先看看這四篇:
Day 12|資料管線魔法初探:讓 AI 系統每天自動抓論文(上)
Day 3 | 攻略第一個據點 — Arxiv Pipeline 技術拆解(上):Metadata 抓取與 PDF 處理
Day X|資料才是英雄——Docling 的 PDF 解析秘笈 📄🛡️
Day 4 | 征服第二個據點 — Arxiv Pipeline 技術拆解(下):PDF 向量化與 Qdrant 上傳
orion:
image: prefecthq/prefect:3-latest
container_name: prefect-orion
command: prefect server start --host 0.0.0.0 --port 4200
ports:
- "4200:4200" # Web UI + API
environment:
PREFECT_API_DATABASE_CONNECTION_URL: sqlite+aiosqlite:///prefect.db
volumes:
- ./data/prefect_data:/root/.prefect
networks:
- langfuse-otel-net
功能:
http://localhost:4200)PREFECT_API_URL 與 Orion 通訊arxiv-flow Container
arxiv-flow:
build:
context: .
dockerfile: ./services/arxivservice/Dockerfile.arxiv
image: arxiv-flow:latest
container_name: arxiv-flow
command: bash /app/deploy_flows.sh
environment:
PREFECT_API_URL: http://orion:4200/api
volumes:
- ./arxiv:/app
- ./docker_cache/hf_cache:/root/.cache/huggingface # avoid space out, you don't need to add this.
- ./data/arxiv_worker:/data
depends_on:
- orion
env_file:
- .env # <- 指定要讀的環境變數檔
networks:
- langfuse-otel-net
Dockerfile.arxiv
FROM prefecthq/prefect:3.4.18-python3.10-conda
WORKDIR /app
RUN apt-get update && apt-get install -y --no-install-recommends \
build-essential \
git \
curl \
&& rm -rf /var/lib/apt/lists/*
COPY services/arxivservice/requirements.txt ./requirements.txt
# --- 安裝 Python 套件 ---
RUN pip install --no-cache-dir --upgrade pip
RUN pip install --no-cache-dir -r requirements.txt
# --- 複製程式碼 ---
COPY ./arxiv /app
# 預設 command 可以空著,由 docker-compose override
CMD ["bash"]
[Developer] ──編寫 Flow / Task
[Flow] ──定義 Task 執行順序
[Task] ──實際執行邏輯
[Orion] ──接收 Flow Run / Task 日誌
│
└─(deploy_flows.sh 自動部署)
├─ 等待 Orion 就緒
├─ 建立 Work Pool / Queue
└─ 註冊 Flow → 可排程自動執行
角色:設計者與操控者
職責:
工具:
可以把 Developer 想像成魔法師,手持魔杖(鍵盤),設計魔法陣(Flow)與咒語(Task)。
from datetime import timedelta, datetime
from prefect.schedules import Cron
from arxiv_pipeline import arxiv_pipeline
# 動態計算日期
today = datetime.utcnow()
date_to = today.strftime("%Y%m%d")
date_from = (today - timedelta(days=30)).strftime("%Y%m%d") # 過去 30 天
# 建立 Interval schedule
# 每天 14:01 台北時間 (等於 UTC 06:01)
interval_schedule = Cron("1 6 * * *", timezone="UTC")
# 使用 flow.serve 註冊 flow 並套用 schedule
arxiv_pipeline.serve(
schedule=interval_schedule,
parameters={"date_from": date_from, "date_to": date_to, "max_results": 20},
)
角色:流程編排者 / 魔法陣
概念:
date_from、date_to)特性:
範例:
@flow(name="arxiv-pipeline-flow")
def arxiv_pipeline(date_from, date_to, max_results=10):
papers = fetch_papers_task(date_from, date_to, max_results)
pdf_results = process_pdfs_task(papers)
qdrant_index_task(papers, pdf_results.get("parsed_papers", {}))
generate_report_task({"papers_fetched": len(papers)})
Flow 就像完整的魔法陣,把單一咒語(Task)串起來施法。
角色:最小單位 / 魔法咒語
概念:
特性:
範例:
from prefect import task
@task(retries=3, retry_delay_seconds=10)
def fetch_papers_task(date_from, date_to, max_results):
# 呼叫 arXiv API,抓取論文資料
...
return papers
Task 就像一個咒語,專門完成單一任務。技術上,Task 是可執行的最小單位
角色:監控者 / 魔法觀測塔
概念:
功能:
可視化:
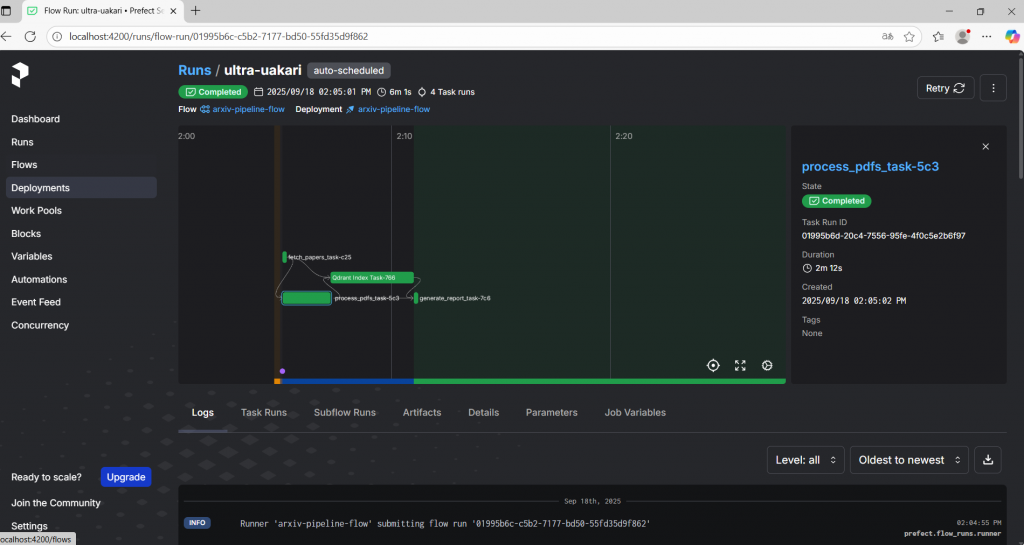
Flow Run: arxiv_pipeline - 2025-09-18 (魔法陣)
├─ Task: fetch_papers_task ✅ (咒語1)
├─ Task: process_pdfs_task ✅ (咒語2)
├─ Task: qdrant_index_task ✅ (咒語3)
└─ Task: generate_report_task ✅ (咒語4)
那實務上,我們通常會準備一個腳本來等待 Orion 啟動,並完成 Flow 的部署:
deploy_flows.sh
#!/bin/bash
set -e
# 等待 Orion 啟動
echo "Waiting for Orion API..."
until curl -s http://orion:4200/api/health | grep "true"; do
echo -n "."
sleep 2
done
echo "Orion is ready ✅"
# 印 Prefect 版本
prefect version
# 建立 Work Pool / Queue(容錯)
prefect work-pool create default --type process || true
prefect work-queue create ingest-queue --pool default || true
# 部署 flow
echo "Deploying flows..."
python /app/prefect_entrypoint.py
Orion 就像魔法學院的觀測塔,你可以即時監控魔法施法過程,查看每個 Task 是否成功、是否有錯誤、執行時間等。
[Developer]
│ 寫 Flow / Task
▼
[Flow] ----------------→ 定義 Task 執行順序
│
▼
[Task] ----------------→ 實際執行邏輯(抓資料、解析 PDF、索引)
│
▼
[Orion] ----------------→ 記錄每次 Flow Run 與 Task 執行狀態、日誌、結果
以下是實戰中的完整版本,包含紀錄處理結果與錯誤統計。
import asyncio
from datetime import datetime, timedelta
from prefect import flow
from logger import AppLogger
from tasks.fetch_papers import fetch_papers_task
from tasks.generate_report import generate_report_task
from tasks.process_pdfs import process_pdfs_task
from tasks.qdrant_index import qdrant_index_task
logger = AppLogger(__name__).get_logger()
@flow(name="arxiv-pipeline-flow")
def arxiv_pipeline(
date_from: str, date_to: str, max_results: int = 10, store_to_db: bool = True
):
results = {
"papers_fetched": 0,
"pdfs_downloaded": 0,
"pdfs_parsed": 0,
"papers_stored": 0,
"papers_indexed": 0,
"errors": [],
"processing_time": 0,
}
logger.info("results")
start_time = datetime.now()
# Step 1: Fetch paper metadata from arXiv
papers = asyncio.run(fetch_papers_task(date_from, date_to, max_results))
logger.info("fetch_papers_task")
results["papers_fetched"] = len(papers)
# Step 2: Process PDFs if requested
pdf_results = {}
if papers:
pdf_results = asyncio.run(process_pdfs_task(papers, store_to_db=True))
results["pdfs_downloaded"] = pdf_results["downloaded"]
results["pdfs_parsed"] = pdf_results["parsed"]
results["errors"].extend(pdf_results["errors"])
results["papers_stored"] = pdf_results["papers_stored"]
logger.info(f"Stored {pdf_results['papers_stored']} papers in DB")
# Step 3: Qdrant Index
indexed_count, _ = qdrant_index_task(papers, pdf_results.get("parsed_papers", {}))
results["papers_indexed"] = indexed_count
logger.info(f"Qdrant Index {indexed_count}")
# Calculate total processing time
processing_time = (datetime.now() - start_time).total_seconds()
results["processing_time"] = processing_time
result_summary = {
"papers_fetched": len(papers),
"pdfs_downloaded": results.get("pdfs_downloaded", 0),
"pdfs_parsed": results.get("pdfs_parsed", 0),
"papers_indexed": results.get("papers_indexed", 0),
"papers_stored": results.get("papers_stored", 0),
"errors": pdf_results.get("errors", []),
}
# 呼叫日報告 task
report = generate_report_task(result_summary)
logger.info(f"\n{report}")


 iThome鐵人賽
iThome鐵人賽