在之前的文章中,我們已經完成了模型的訓練。現在,我們需要評估模型的效能,確保它能準確地完成任務。評估一個分類模型通常會用到以下四個核心指標:精確率 (Precision)、召回率 (Recall)、F1 分數 (F1-Score) 以及 準確率 (Accuracy)。
這些指標的計算都基於一個重要的工具:混淆矩陣 (Confusion Matrix)。混淆矩陣能夠清楚地呈現模型分類結果的四種情況:
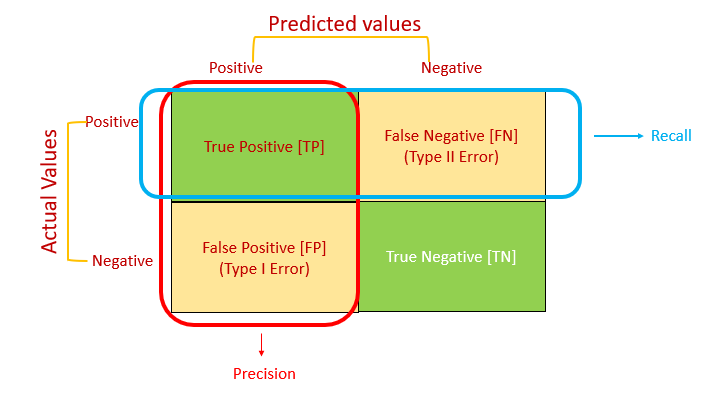
Confusion Matrix [Image by Indhumathy Chelliah]
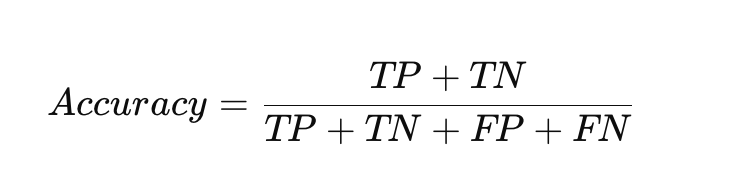
準確率是最直觀的指標,代表所有預測正確的樣本佔總樣本數的比例。
什麼時候用?
當你的資料集非常平衡,也就是不同類別的樣本數量差不多時,準確率是一個很好的參考指標。
然而,如果資料不平衡,準確率可能會產生誤導。例如,在一個有 99% 負面評論的資料集中,一個總是預測「負面」的模型,其準確率也能高達 99%,但這個模型其實毫無價值。
精確率代表在所有被模型預測為正面的樣本中,有多少是真正正確的。它衡量的是模型「不誤報」的能力。
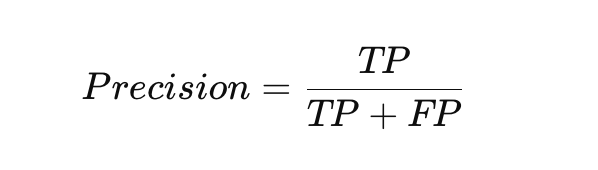
什麼時候用?
當誤判 (FP) 的成本很高時,精確率特別重要。
例如,在一個垃圾郵件分類器中,我們希望被標記為垃圾郵件的信件都是真正的垃圾郵件,以免誤刪重要郵件。
召回率代表在所有真實為正面的樣本中,有多少被模型成功預測出來。它衡量的是模型「不漏判」的能力。
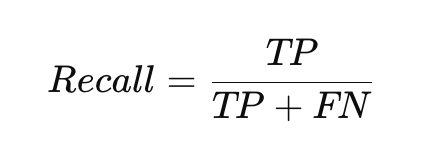
什麼時候用?
當漏判 (FN) 的成本很高時,召回率特別重要。
例如,在一個疾病診斷模型中,我們寧願多一點誤報,也不希望漏掉任何一個真正的病患。
F1 分數是精確率和召回率的調和平均數,它綜合考量了這兩個指標,提供一個更全面的單一評估分數。
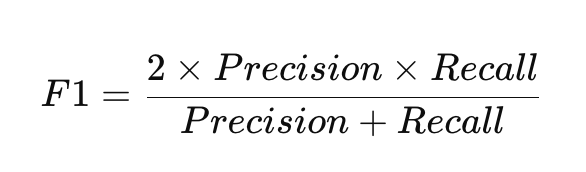
什麼時候用?
F1 分數特別適合在資料不平衡的狀況下,或當你希望同時兼顧精確率和召回率時使用。
它能避免只看單一指標所造成的偏見。
在實際應用中,我們不能只看單一指標。通常需要根據專案目標,來決定精確率或召回率哪一個更重要,並透過 F1 分數來進行綜合評估。
在情感分析中,同時擁有高的精確率和召回率,代表模型既能準確地判斷情感,也不會錯過任何重要的評論。


 iThome鐵人賽
iThome鐵人賽