Hi大家好,
這是我參加 iT 邦幫忙鐵人賽的第 1 次挑戰,這次的主題聚焦在結合 Python 爬蟲、RAG(檢索增強生成)與 AI,打造一套 PTT 文章智慧問答系統。在過程中,我會依照每天進度上傳程式碼到 GitHub ,方便大家參考學習。也歡迎留言或來信討論,我的信箱是 gerryearth@gmail.com。
在做文件檢索或知識管理時,我們常常會面臨一個問題:要如何切割文章,才能在保持語意完整的同時,又讓檢索結果足夠精準?
不同的切割策略會帶來截然不同的效果,有時候切得太細,雖然檢索精準,但上下文容易斷裂,切得太長,又可能把不相關的內容一起帶進來。
為了找到更適合的平衡點,我特別拿大家熟悉的 PTT 文章 做了一些統計與實驗,試著從字數分布的角度來分析,看看應該如何決定 chunk 的長度與重疊率。
接下來,我會先整理不同切割方式的優缺點,再分享 PTT 文章的實際觀察數據,最後給出實驗比較與建議。
昨天我們討論過在做文本檢索或知識檢索時,「如何切割文章」其實會影響最終的檢索效果。
根據實驗,我們大致可以將切割方式整理成以下三種類型:
| 切割長度 | 優點 | 缺點 | 適用情境 |
|---|---|---|---|
| 短 Chunk (100~200 tokens) | 檢索精準、減少不相關資訊 | 缺乏上下文、回答可能片段化、向量數量龐大、成本較高 | FAQ、單句查詢、簡短技術文件 |
| 中 Chunk (300~500 tokens) | 保留語意完整,精準與成本平衡 | 偶爾仍會切斷語境,但影響不大 | 新聞文章、部落格、知識文件(建議預設) |
| 長 Chunk (600~1000 tokens) | 保持完整上下文,降低切斷風險 | 檢索時可能引入過多無關資訊、模糊化 | 長篇論文、故事、需要完整語境的文本 |
從表格可以看出,不同的切割方式各有取捨,因此在應用上需要依照「資料型態」與「使用場景」來調整。
為什麼會有以上的結論呢?
其實最好的方式就是 針對資料來源做觀察與驗證。以 PTT 的文章為例,我先做了統計,來看看文章字數的分布情況。
先用 SQL 查詢文章平均字數:
SELECT AVG(CHAR_LENGTH(content)) AS avg_content_length
FROM my_database.article_article;
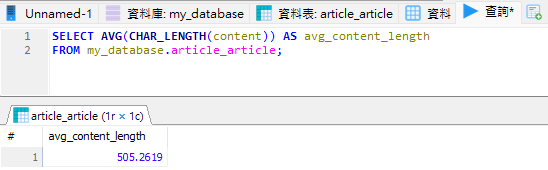
結果顯示 平均字數約為 505 個字。這意味著大部分 PTT 的文章其實不算長,許多文章篇幅甚至相當精簡。
接著,我進一步將文章按照長度劃分區間來觀察整體分布:
SELECT
length_range,
CONCAT(ROUND(COUNT(*) * 100.0 / total.total_count, 1), '%') AS percentage
FROM (
SELECT
CASE
-- 1. 0~999 每100字
WHEN CHAR_LENGTH(content) < 1000 THEN
CONCAT(FLOOR(CHAR_LENGTH(content) / 100) * 100, '-',
FLOOR(CHAR_LENGTH(content) / 100) * 100 + 99)
-- 2. 1000~5000 每500字
WHEN CHAR_LENGTH(content) BETWEEN 1000 AND 5000 THEN
CONCAT(FLOOR((CHAR_LENGTH(content) - 1000) / 500) * 500 + 1000, '-',
FLOOR((CHAR_LENGTH(content) - 1000) / 500) * 500 + 1499)
-- 3. >5000
ELSE '>5000'
END AS length_range
FROM my_database.article_article
) AS ranges
CROSS JOIN (
SELECT COUNT(*) AS total_count
FROM my_database.article_article
) AS total
GROUP BY length_range, total.total_count
ORDER BY
CASE
WHEN length_range = '>5000' THEN 9999999
ELSE CAST(SUBSTRING_INDEX(length_range, '-', 1) AS UNSIGNED)
END;
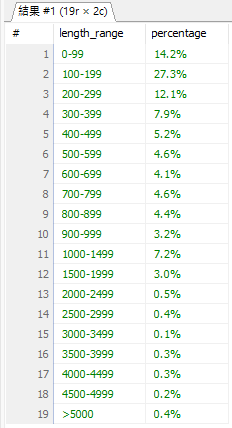
統計結果發現:
這樣的分布,會直接影響我們在設計 chunk 切割策略時的考量。
稍微觀察 PTT 文章後會發現,大多數內容以新聞分享、時事討論或心得交流為主。這些文章通常以直白、快速的表達方式呈現,目的在於「傳遞訊息」或「引發討論」,而不是像作文或小說那樣,需要鋪陳複雜的起承轉合,或透過冗長的段落來營造氛圍。
因此,PTT 的文章大多結構簡單、資訊密度高,而且讀者往往只關心重點內容。也正因如此,在進行文本切割時,並不需要像處理長篇論文或文學作品那樣,將文章細分成許多段落來保留上下文;反而應該以較適中的 chunk 大小,讓檢索能兼顧效率與精準度。
那麼,我們應該要如何切割文章呢?
為了更直觀地理解切割策略的差異,我針對三種設定進行實驗:
| chunk_size | chunk_overlap | 平均段數 |
|---|---|---|
| 100 | 20 | 7.5 |
| 300 | 60 | 2.6 |
| 500 | 100 | 1.8 |
可以看到:
綜合以上數據與實驗結果,可以得到以下觀察:
換句話說,切割策略沒有「萬用公式」,而是要 根據資料特性與應用情境動態調整。
明天 【Day 23】語意檢索與關鍵字檢索 - 深入認識檢索方式 會從理論的角度,深入解析這兩種檢索方式,並探討它們的核心差異與適用情境。

