訓練結束後,程式碼會自動產生並儲存三張重要的分析圖表,這些圖表是我們診斷模型表現的關鍵。
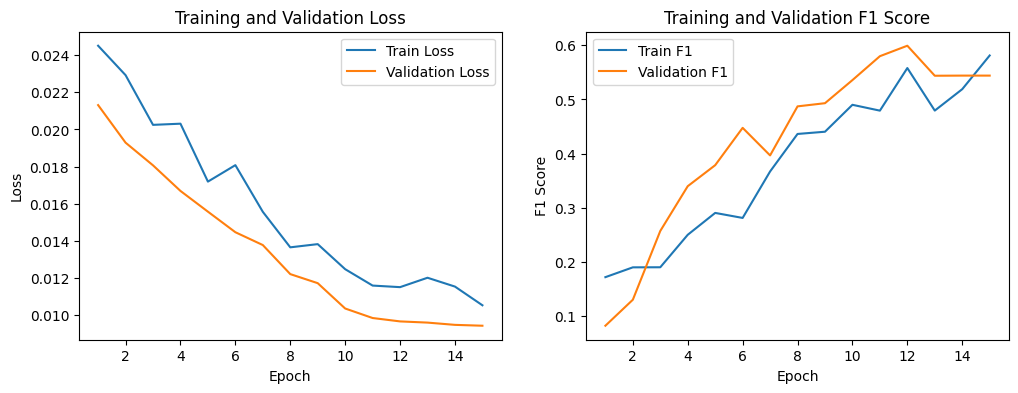
從這張圖中,我們可以看到訓練和驗證損失(Loss)隨著訓練輪數的增加而持續下降,這表示模型正在有效地學習。同時,訓練和驗證的 F1-Score 曲線也在穩定上升,這是一個好的開始。儘管驗證 F1-Score 在後期有輕微波動,但整體趨勢顯示模型性能穩步提升,沒有出現明顯的過度擬合(overfitting)現象。
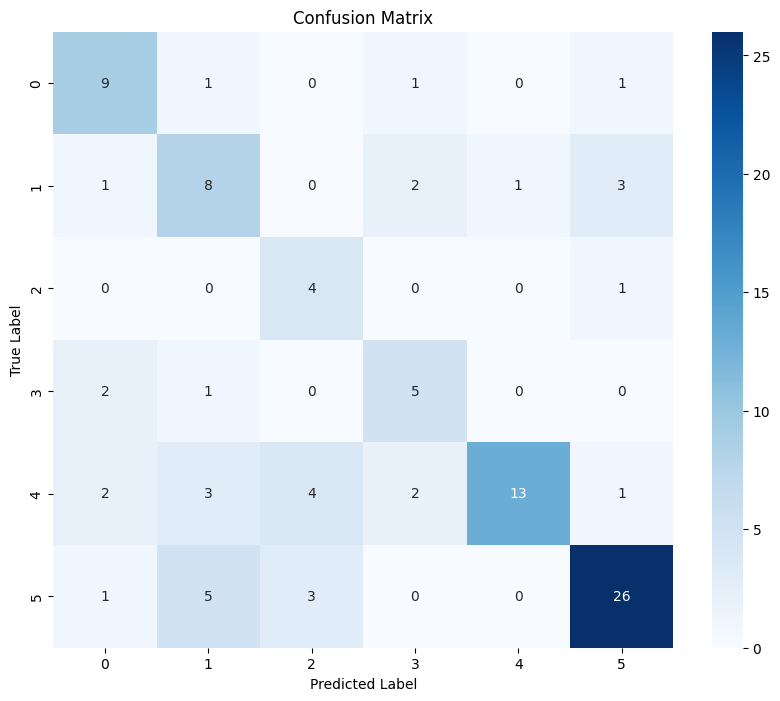
混淆矩陣直觀地展示了模型在各個類別上的預測表現。對角線上的數字代表模型預測正確的樣本數。
例如,在類別 5上,模型正確預測了** 26 **個樣本,表現非常出色。
然而,我們也看到一些混淆情況,例如類別 4 有 3 個樣本被錯誤地預測為類別 1,這代表模型在區分這兩個類別時可能存在困難。
分類報告提供了更詳細的量化指標:
5(售後服務與會員權益)的 F1-Score 達到了 0.78,表現最為優異。2 的 F1-Score 僅有 0.50,且 support 只有 5 個樣本,說明該類別的樣本數太少,可能是導致表現不佳的主要原因。1 的 F1-Score 0.48 和 precision 0.44 也相對較低,表明模型在預測這個類別時不夠精確。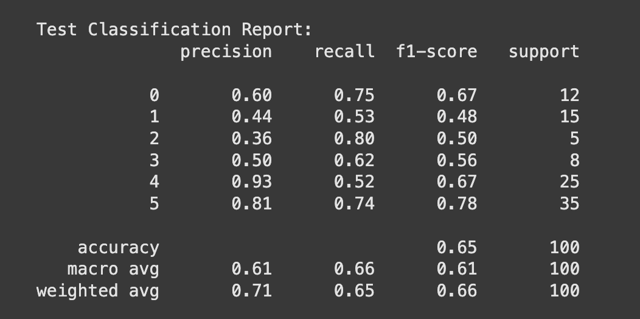
在人工智慧模型開發中,僅僅訓練一個模型是不夠的。模型的最終性能往往取決於一系列精巧的優化策略和超參數(Hyperparameters)的選擇。本文將根據所提供的程式碼,深入解析如何通過 超參數調校 和 進階優化技術,進一步提升基於 BERT 的文本分類模型效果。
從上述分析模型訓練結果後,我們可以使用程式碼中所設定的超參數進行調整,例如調整學習率、Dropout rate,或是權重調整。
超參數是那些在訓練過程開始前就設定好的參數,它們對模型的學習和最終性能有著決定性的影響。程式碼中的 main 函數定義了幾個關鍵超參數,並對它們進行了優化。
批量大小 (BATCH_SIZE):批次大小決定了每次訓練迭代中使用的樣本數量。程式碼將其設為 32,這是為了平衡訓練速度和記憶體佔用。對於大型預訓練模型如 BERT,過大的批量可能導致記憶體不足(OOM),而過小的批量則會使訓練過程不穩定。
學習率 (LEARNING_RATE):學習率決定了模型在每一步訓練中更新權重的幅度。程式碼將其設定為 2e−5,這是一個在微調(fine-tuning)大型預訓練模型時常用的較小值。過高的學習率可能導致模型不收斂,而過低則會使訓練變得緩慢。
訓練輪數 (NUM_EPOCHS):訓練輪數表示模型將完整地遍歷訓練資料集的次數。程式碼將其增加到 15 輪,以確保模型有足夠的學習機會。但為了避免過度擬合,搭配了早停 (Early Stopping) 策略,這是一個非常重要的實踐。
序列最大長度 (MAX_LENGTH):序列長度限制了輸入文本的長度。程式碼將其設定為 128,這是一個折衷的選擇,既能覆蓋大多數文本,又能節省計算資源。
除了基本的超參數,程式碼還採用了多種先進技術來優化模型:
BertForSequenceClassification 的 hidden_dropout_prob 和 attention_probs_dropout_prob 都增加到 0.3。Dropout 是一種有效的正規化技術,它在訓練期間隨機地「關閉」神經元,迫使模型不依賴於任何單一神經元,從而減少過度擬合。AdamW 優化器中,程式碼將 weight_decay 設置為 0.1。權重衰減等同於 L2 正規化,它在損失函數中加入一項懲罰,以限制模型權重的大小。這有助於防止權重變得過大,從而使模型更平滑,降低過度擬合的風險。get_scheduler 中增加了預熱步數(num_warmup_steps),這意味著學習率在訓練初期會從一個非常小的值逐漸增加到設定的學習率。這個技巧對於大型預訓練模型尤其重要,它能讓模型在訓練初期更穩定地收斂,避免因大的更新步長而導致不穩定。gc.collect() 和 torch.cuda.empty_cache() 來主動釋放記憶體。這對於在 GPU 上訓練大型模型至關重要,可以有效避免記憶體溢出錯誤,並提高資源利用率。根據模型結果分析,本模型在訓練歷史曲線上顯示了穩定的學習歷程,損失持續下降且 F1-Score 穩步提升,表明模型沒有出現過度擬合。然而,測試集分類報告和混淆矩陣揭示了模型在少數樣本類別(如類別 2 和 1)上的表現較差,這可能是因為樣本數量過少,導致模型難以有效學習這些類別的特徵。
當訓練損失(Train Loss)和驗證損失(Validation Loss)兩者曲線走勢出現兩個不同方向,通常會看到訓練損失持續下降,而驗證損失卻在某個時間點開始上升,通常是發生模型過度擬合。
為了應對這些挑戰,我們介紹超參數調校和進階優化技術的重要性。程式碼中主要採用了一系列優化策略,包括:
我們大概可以了解一個成功的深度學習模型需要資料處理、超參數調校和訓練優化等多方面策略的結合。這些技術共同作用,能夠有效地提升模型效能,特別是在處理類別不平衡或少量樣本的挑戰性任務。
儘管我們的模型在某些類別上表現還有進步空間,但整體表現尚可接受,但仍會遇到一些有少樣本的分類,無法提高模型的準確度。透過對這些結果的分析,我們可以為未來的模型優化工作提供具體的方向。


 iThome鐵人賽
iThome鐵人賽