恭喜你!經過前幾次努力在資料預處理、模型訓練和超參數調校之後,我們已經成功建立了一個 BERT 中文文本分類模型。下一步就是將它部署出去,讓其他人能夠輕鬆使用。而 Hugging Face Hub 提供了最簡單、最有效的方式來分享和託管你的模型。
本篇文章將會逐步說明如何將你的模型部署到 Hugging Face Hub,並說明每個步驟的意義。
在部署之前,你必須先讓你的程式能夠與 Hugging Face Hub 進行連線。
安裝必要的函式庫:你需要安裝 huggingface_hub。如果尚未安裝,請執行以下命令:pip install huggingface_hub。
登入你的帳號:程式碼中的第一步就是登入。login() 函數需要你的 Hugging Face 權杖(token),這個權杖相當於你的登入密碼,用於驗證你的身份並授予上傳權限。
from huggingface_hub import HfApi, login
# 使用你的 Hugging Face Token 進行登入
login(token="YOUR_HUGGING_FACE_TOKEN")
注意: 為了安全起見,請將你的權杖視為敏感資訊,不要公開在程式碼中。
在 Hugging Face Hub 上,每個模型都儲存在一個「倉庫」(repository)中,就像是 GitHub 上的程式碼倉庫一樣。
設定倉庫名稱:程式碼中定義了 repo_name 和 your_username 來組合出一個唯一的倉庫 ID (repo_id),格式為 <你的用戶名>/<倉庫名稱>。這確保你的模型有專屬的空間。
確認模型路徑:output_dir 變數指向你的訓練模型儲存的本地目錄。程式碼中的 assert 語句會檢查這個目錄是否存在,以及其中是否包含模型權重文件(如 pytorch_model.bin 或 model.safetensors),這是模型上傳的必要條件。
一個好的模型應該要配備清晰的說明文件,讓使用者了解它的功能、用途和限制。
README.md 文件。這個文件使用了特殊的 YAML 標頭 (---) 來設定模型的語言、授權、標籤等元資料。這些標籤將會顯示在 Hugging Face 網頁上,幫助使用者更快地找到你的模型。這是部署的最後一步,程式碼將執行核心的部署操作。
api.create_repo() 函數會在你的帳戶下創建一個新的倉庫。如果倉庫已經存在,exist_ok=True 參數會避免程式報錯,讓你可以直接上傳。程式碼也設計了錯誤處理機制,如果創建失敗,會嘗試一個替代的倉庫名稱。api.upload_folder() 函數會將你的本地模型目錄 output_dir 中的所有文件,包括模型權重、tokenizer 設定和 README.md,一次性全部上傳到指定的倉庫。# 核心上傳程式碼
api.upload_folder(
folder_path=output_dir,
repo_id=repo_id,
repo_type="model",
)
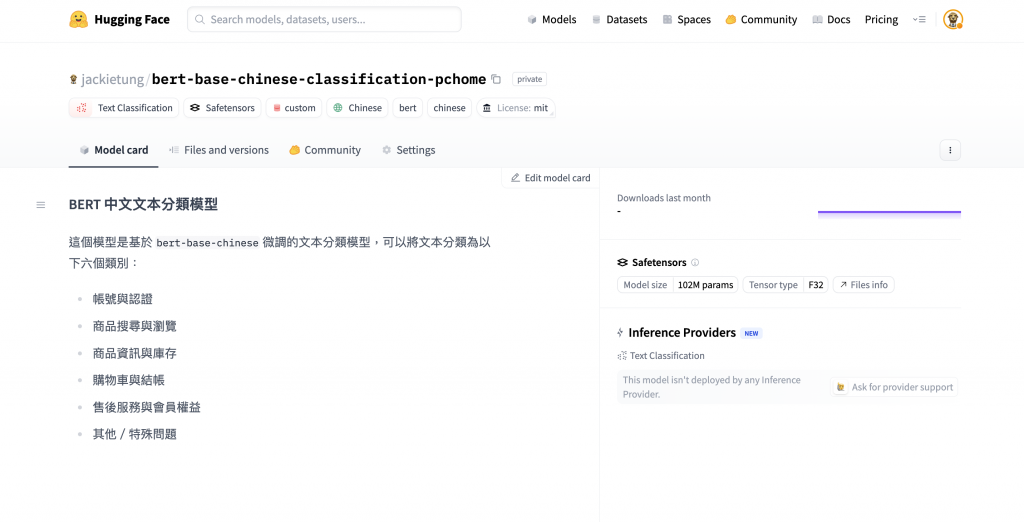
上傳成功後,你就可以在你的 Hugging Face 個人主頁上找到這個新的模型。網頁上會顯示你所設定的標籤和說明文件,使用者可以直接在線上試用你的模型,或是透過程式碼輕鬆載入並使用它。
透過這些步驟,我們將模型從本地部署到雲端,更是將你的研究成果貢獻到一個全球化的 AI 社群中,讓你的模型發揮更大的價值。
from transformers import AutoModelForSequenceClassification, AutoTokenizer, pipeline
# 直接使用模型和分詞器
model_name = "jackietung/bert-base-chinese-classification-pchome"
model = AutoModelForSequenceClassification.from_pretrained(model_name)
tokenizer = AutoTokenizer.from_pretrained(model_name)
# 測試文本
test_texts = [
"這個 App 的登入系統太複雜了,每次都要重新輸入密碼,能不能增加指紋登入功能?",
"App 的搜尋功能太爛了,輸入關鍵字後常常顯示不相關的結果,希望能改進搜尋演算法。",
"最新上架的商品圖片解析度太低,而且商品描述不夠詳細,很難做出購買決定。",
"結帳流程太繁瑣,為什麼要填寫這麼多資料?而且付款完成後沒有明確的訂單確認頁面。",
"客服回應速度太慢,我的問題提交三天了還沒有人回覆,這樣的服務品質令人失望。",
"App 最近更新後經常閃退,而且耗電量增加了很多,希望開發團隊能盡快修復這些問題。"
]
# 使用 pipeline 進行預測
for text in test_texts:
print(f"文本: {text}")
print(f"預測結果: {result}")
print("-" * 30)



 iThome鐵人賽
iThome鐵人賽