昨天我們討論了各式各樣的 application 可以如何用 app of apps 的架構一鍵納管,今天我們要來討論有點像是 app of apps 的反例,也就是同樣的 application 要如何同時部署在多個 cluster 中。
在一開始,我們團隊是完全依賴 Terraform Helm provider 來安裝各種基礎設施 Helm chart(後面我們會稱這些基礎設施 Helm chart 為 infra charts),然後再用 ArgoCD 部署應用程式。但隨著專案成長,這種方式逐漸暴露出痛點 —— 特別是 CRD 安裝順序錯亂 與 Provisioner workaround。這篇文章就來聊聊我們遇到的狀況,為什麼最後選擇了 Helm Manager 這個架構來解決。
(這篇文章的內容基本上是從我今年在 KCD 的演講抄過來的,有興趣的朋友也可以去看看原始簡報)
2025/09/20 更新:今年演講的影片也上線囉!🔗 連結在此
我們的 Kubernetes 基礎環境可以分成三層:

在這個架構下,Terraform 負責建立 AWS 資源以及 Infra charts;ArgoCD 則用來同步應用程式。
Terraform Helm provider 的最大問題,就是 無法正確識別 CRD 類型。
舉個例子,當我們同時要安裝一個 Controller 與它所需的 CRD(CustomResourceDefinition)時,即便在 Terraform 裡面加上 depends_on,Terraform 仍會一次把 CRD manifest 丟給 API Server。但問題是此時 Controller 還沒起來,API Server 就會報錯:
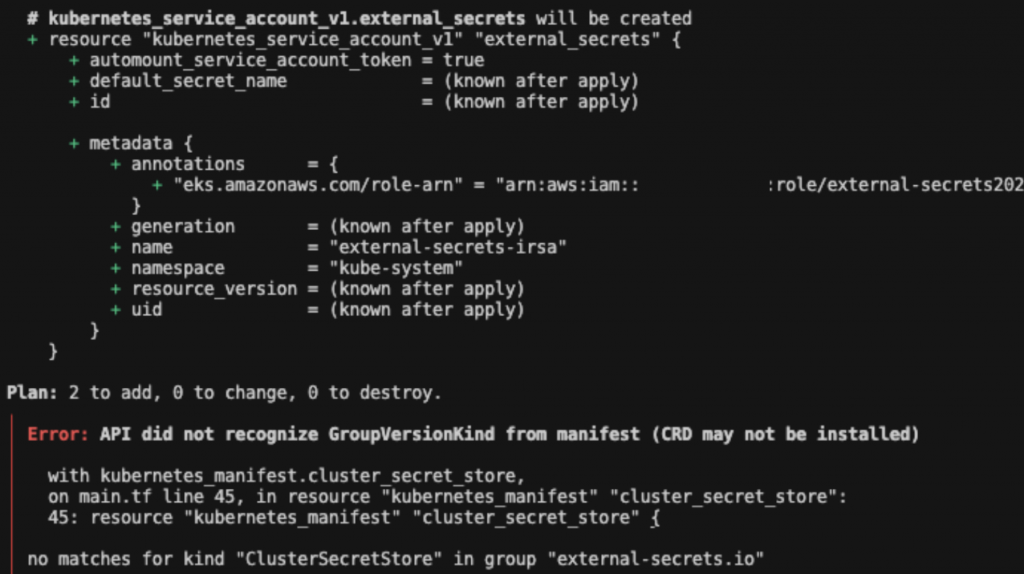
這意味著 Terraform 沒辦法處理 Helm chart 內部的安裝順序,導致 Controller 還沒就緒 → CRD 無法識別 → apply 失敗。
為了繞過 CRD 的問題,我們一度使用 Terraform 的 local-exec provisioner,在 Controller 安裝完成後再手動 apply CRD。
雖然暫時能用,但問題更多:
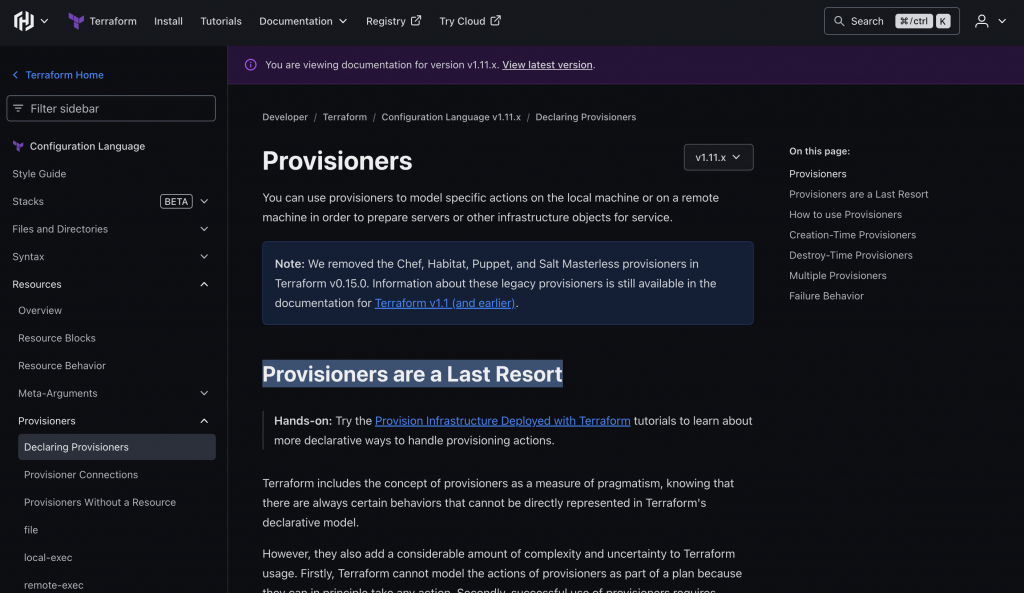
Terraform 官方文件甚至直接寫著:Provisioners are a last resort,盡量避免使用。
註:在 KCD 分享時,Terraform 版本還更新到 1.11.x 而已,然而現在再去看 provisioner 文件時,官方已經把「Provisioners are a Last Resort」這個段落給移除 (since 1.12.x 就被移除了),並且我發現他們新增了
on_failure這個 arguement,看起來試圖要解決 provisioner failed 之後不會 rollback 的問題。不過我們還是認為,將 helm chart 共同使用 ArgoCD 來進行納管依舊是利大於弊的選擇,畢竟他可以做到跨多個 cluster 的管理,並且統一用圖形化介面管理、及 GitOps 驅動變更,這幾點都是我們繼續選用 Helm Manager 的原因。
此外,如同我們在前兩天都有提到的,我們的架構會有一個 central cluster 部署 argocd,並且由這個 central cluster 與 gitlab 進行連線,再經過這個 argocd 將設定檔更新到 project cluster 中,去產生對應的資源
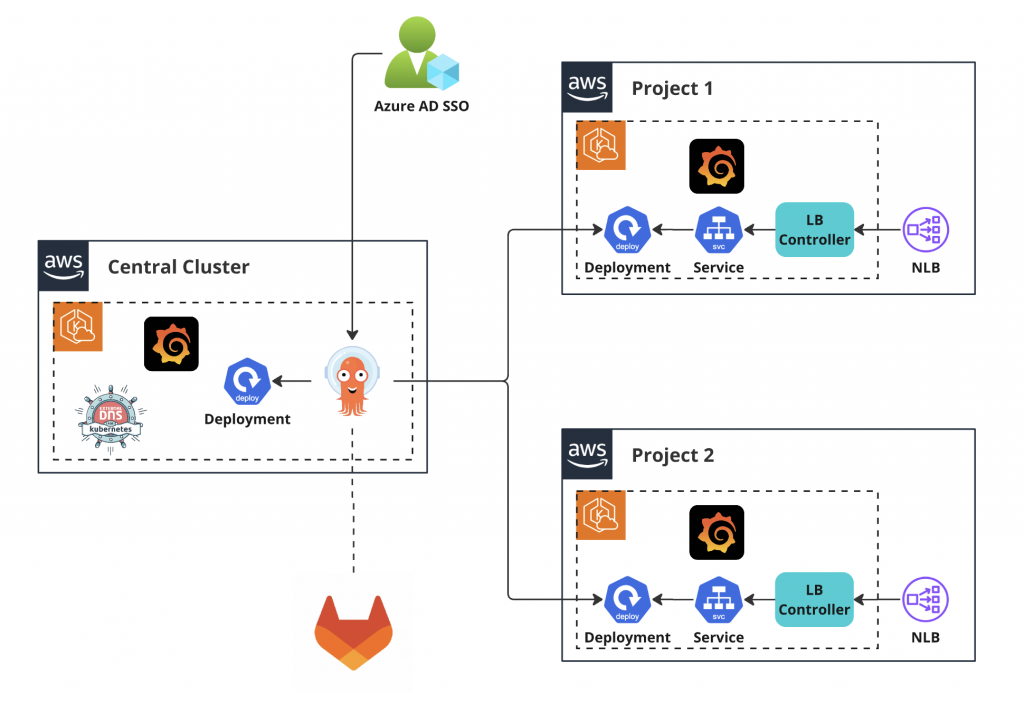
不過這樣做有個痛點是,因為我們的基礎架構大致相同,也就是說我們在 project 1 和 project 2 中所採用的 infra charts 內容也會一樣,多開一個新案就要另外再複製一份相同的設定檔出來,若是在需要批次大量修改某項設定時,也會造成管理上的成本增加,浪費許多不必要的人力在管理這些設定檔上。因此我們也希望能夠找到一個可以統一修改相似設定的架構,來避免這項重工的問題。
首先是 ArgoCD 有支援 Multi-cluster 的管理辦法,他可以同時管理多個 k8s cluster,將同一份基本設定同步至多個不同的 cluster 中,再根據我們 generators 裡面的各項特殊設定(細節可以參考文件),在各個環境長出對應應有的 manifest,這主要是解決了我們在痛點三所提及的多叢集管理議題。
此外,回到痛點一與痛點二,使用 argocd 在部署 helm chart 上面,就不會遇到「因為 CRD controller 尚未部署成功,就無法宣告 CRD 的問題」,這是因為在部署 infra chart 時,我們已經將 helm chart 和 CRD 包裝成一層新的 helm chart,而 argocd 在部署 CRD 時會先幫我們處理好 CRD controller 的安裝後,再進行 CRD 的安裝,因此不會遇到像 terraform 部署時一樣的問題。
說到這邊可能會有人想問,那為什麼不直接將 helm chart + CRD 包裝成新的 helm chart,使用 terraform 部署就好?但這樣做的話,就也沒辦法解決我們痛點三所提到的問題,也就是在多個環境中重複使用同一個設定檔的方式,使用 ApplicationSet 的架構剛好可以解決方才所提及的所有痛點

實際使用下來,我覺得有幾個很關鍵的優勢:
這對於有多專案、多環境的團隊來說,真的是救星。
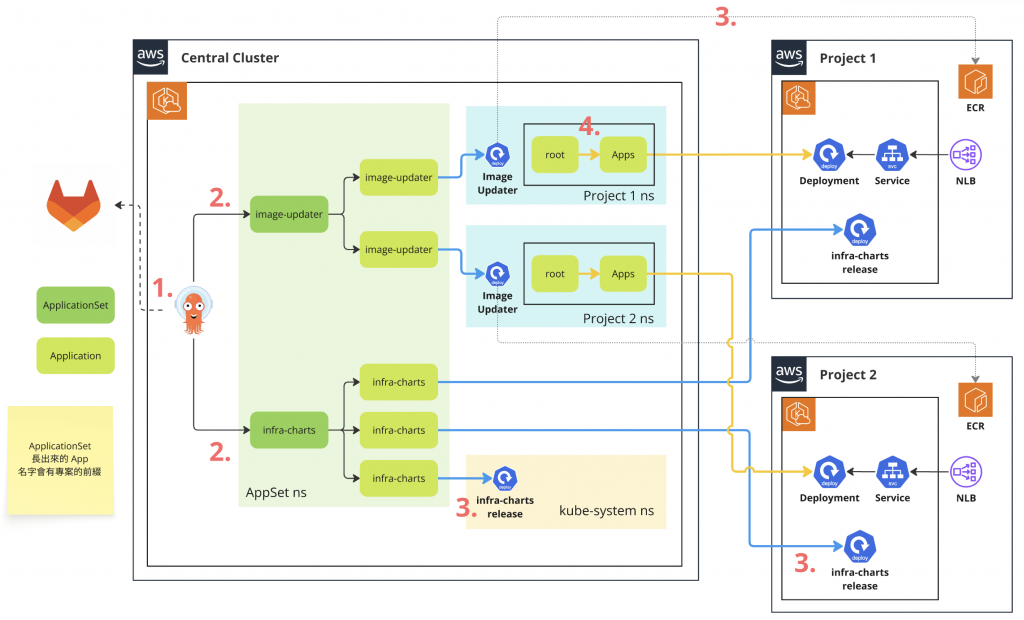
我們在實作上,主要維護了兩個核心 ApplicationSet:
這樣的設計帶來的好處是:
以前要加一個新專案,得先建 cluster,然後再手動一個個安裝 infra charts。
現在只要把新 cluster 加到 ApplicationSet 清單裡,infra-charts 就會自動同步過去,省下超多時間。這也意味著 onboarding 新專案快很多,幾乎是一鍵完成。

這張圖的看法是,每個直欄是一種部署方式。左邊跟中間是 Before Helm Manager,右邊的部署方式是使用 Helm Manager 之後
在使用 terraform 部署,且不使用 provisioner 的狀況下,我們在部署完 EKS cluster 之後,會需要分兩次進行 terraform apply 的指令。第一次是進行 CRD controller 的部署,第二次則是進行 CRD 本人的部署。
而如果採用 provisioner 的話,則會遇到 local-exec 與 terraform 慣例衝突、且沒辦法 rollback 狀態等等的問題。
但如果採用 argocd 進行 helm manager 架構的部署的話,在我們 apply 完 EKS 之後,就可以直接將 cluster 註冊在 argocd 上納管,並且利用 argocd 一次部署 該 cluster 所需要的所有 infra chart,且這個情境下只需要修改該 cluster 中的特定 values 即可。
回頭看,我們一開始遇到的痛點其實很典型:CRD 安裝順序搞不定、Provisioner workaround 帶來一堆不可控的風險,再加上多叢集維護時重複設定的成本,長期下來真的很消耗心力。
導入 Helm Manager 搭配 ApplicationSet 之後,整個狀況改善非常多。我們把部署流程完全轉向宣告式、GitOps 驅動,不僅讓 apply 的次數減少了一半以上,跨專案、跨環境的部署一致性也大幅提升。對團隊來說,這意味著少掉了很多額外的維護工,能更放心把精力放在應用本身。
如果你也打算在專案裡實踐類似的做法,有幾個小建議可以參考:共用的 values 可以集中在 ValuesObject;staging 和 production 要明確分支策略;另外,ApplicationSet 和 Application 放在不同 namespace 會更乾淨好管理。這些小細節累積起來,能讓整條 GitOps pipeline 更穩定,也更容易長期維護。
接下來,我們會開始使用 Helm Manager 這個架構來部署 cluster 中所需要用到的 infra charts。明天就會拿這個架構來部署 Karpenter 囉!

