哈囉,大家好!歡迎來到我們系列文的第二階段!
在 Day 7,我們成功地用 Docker Compose,在單一主機上跑OTA 專案。這對於本機開發來說,是一個非常方便的方法。
但一個問題出現了:「為什麼公司不直接用一台強大的 VM,然後跑 Docker Compose 把服務弄上線呢?」
今天會提到單一主機架構的問題,然後在多主機環境下手動部署的痛苦,再到理解為什麼要使用 Kubernetes 。
在技術上,沒錯,你完全可以在同一台 VM 上,用 docker-compose 把前端、後端、資料庫通通跑起來。開發階段甚至測試環境,這樣做很方便。但一旦進到生產環境,這種「All-in-one」的架構馬上就會出現問題。
1. 單點故障:一台掛了,全都掛了
想像一下:你的應用全部靠一台 VM 撐著。如果這台機器硬碟壞了、系統更新失敗,或者只是網路抽風,那後果就是資料庫、後端、前端一次全掛。整個服務直接黑畫面,沒有備胎,復原還得靠人力。這就是所謂單點故障 (Single Point of Failure)。
2. 資源搶奪:大家住在同一間小套房
再想像另一個場景:資料庫在瘋狂跑查詢,拼命吃 CPU 和硬碟 I/O。結果後端服務被拖慢,API 反應開始卡,前端用戶等得不耐煩。這就是 資源競爭 (Resource Contention),不同性質的服務硬塞在同一台機器上,互相搶有限的資源,最後誰都不好過。
3. 無法好好擴展:升級只能「往上加」
一開始服務流量小,單機沒什麼問題。但隨著使用者變多,後端 API 變成瓶頸,該怎麼辦?在單機模式下,你能做的只有升級硬體(更多 CPU、更多 RAM),這叫做垂直擴展 (Vertical Scaling)。但問題是,硬體總有上限,錢也不是無限的。更聰明的做法應該水平擴展 (Horizontal Scaling),只針對後端加更多副本,分攤流量。但單機架構一開始就把路堵死了。
所以,為了避免這三大坑(可靠性、資源隔離、擴展性),我們就不得不從「單機跑全部」的做法,走向「多台機器分工」。但問題來了,docker-compose 本來就是設計給單機用的工具,一旦要跨多台主機,它就派不上用場了。這時候,我們只好走上那條很折磨人的路:到處 SSH 登入伺服器,再一台一台用 docker run 把服務拉起來。
來想像一下這個場景:
假設公司幫你準備了三台 VM,要把服務分開跑:
10.0.1.11:資料庫 (MariaDB)10.0.1.12:後端 (Golang API)10.0.1.13:前端 (Vue App)光是這樣規劃,看起來還挺整齊對吧?但實際操作起來就很崩潰了。
你要一台一台地登入,手動輸入指令,把容器跑起來,還要記得設定正確的 IP,確保前端能連後端、後端能連資料庫。只要哪裡寫錯一個 IP 或密碼,服務就掛了。每次更新或重啟都要重複同樣的步驟,工作量爆炸,而且極度脆弱。

Kubernetes 出現,就是要解決這個問題的。它直接在所有 VM(Nodes)之上,加了一個「平台層」。所以對工程師來說,我們不用再煩惱:「我的後端到底要跑在 10.0.1.12 還是 10.0.1.13?」
我們只要告訴 K8s:「我需要 3 個後端服務在運行」——然後它就會自動幫我們決定要在哪些機器跑,還能確保如果某個服務掛了,它會自己再拉一個新的起來。這就是 宣告式 (Declarative) 的力量:我們定義「我要什麼」,而不是「怎麼做」。至於怎麼分配、怎麼修復、怎麼保證狀態一致,全交給 Kubernetes。
那麼,這個神奇的「平台層」內部,到底長什麼樣子?
在 Kubernetes 的世界裡,一個運作中的環境被稱作 叢集 (Cluster)。
它是由兩種類型的節點 (Nodes) 所組成:
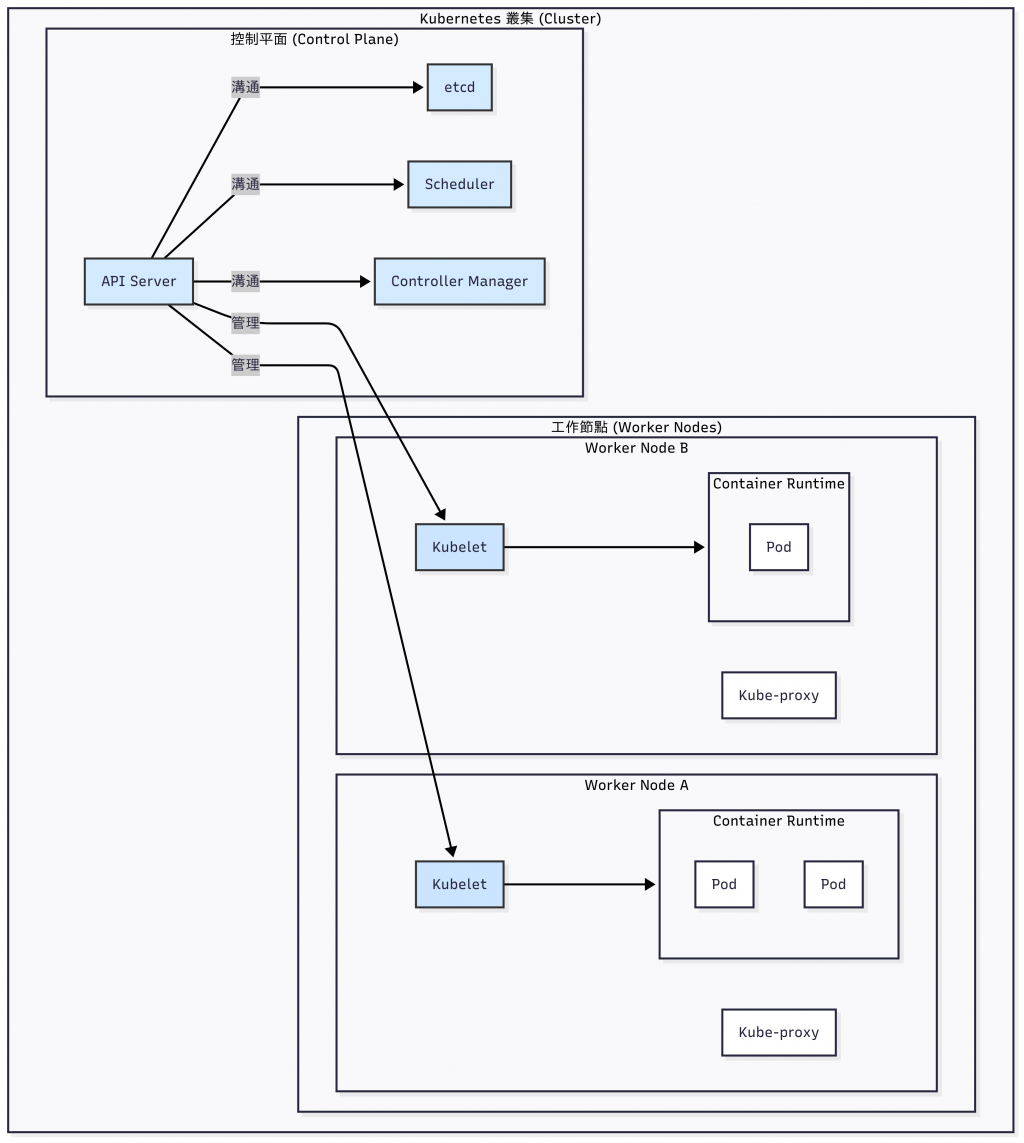
可以把它想成叢集的大腦,所有的全域決策都由這裡發號施令:
kubectl 下指令,還是其他元件之間的溝通,都必須透過它。這些節點就是真正幹活的地方,負責執行我們的應用程式:
containerd 或 CRI-O。今天我們從一個看似簡單的問題開始:「為什麼不能只用一台 VM?」結果發現,生產環境對可靠性、資源隔離和擴展性的要求,其實比想像中還要嚴格很多。
Kubernetes 的厲害之處在於,它提供了一層抽象層,把我們從「管理底層伺服器」的繁瑣工作中解放出來。換句話說,我們不再需要煩惱底層細節,而能專注在「告訴系統我希望應用程式長什麼樣子」。
有了這個體會,相信你也會對接下來探索 K8s 的各種複雜元件更有興趣。明天,我們就要開始動手,用 kubectl 在叢集中部署最小的應用單位——Pod 和 Deployment!明天見!


 iThome鐵人賽
iThome鐵人賽