在昨天的 Day 28,我們成功地用 Grafana 將 Prometheus 中冰冷的指標,變成了看得懂的儀表板。我們終於能夠「看見」系統的健康狀況了。
但一個更重要的問題隨之而來:難道我們要 24 小時不眠不休地盯著儀表板嗎?
當然不是!一個成熟的監控系統,應該具備主動告警的能力。當問題發生時,系統應該要主動來通知我們,而不是等我們自己去看。
今天,我們就要來學習 Grafana 內建的、功能強大的統一告警平台 (Grafana Alerting),並設定我們的第一條告警規則。
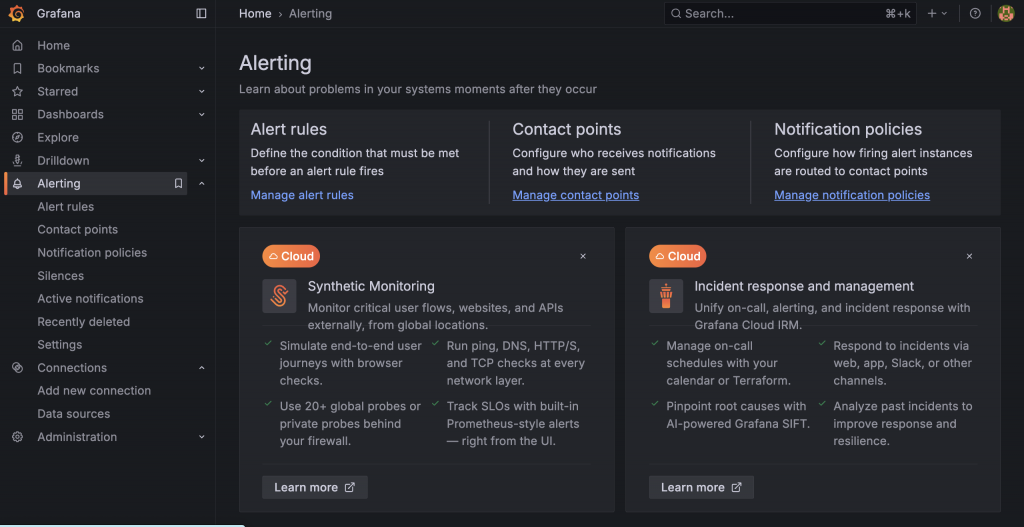
在現代的 Grafana (v8.0+) 版本中,Grafana 不再只是一個單純的視覺化工具,它已經內建了一套完整的告警解決方案,其中就包含了一個功能完整的 Alertmanager。
這意味著,整個告警流程都可以在 Grafana 內部一站式完成,包含:
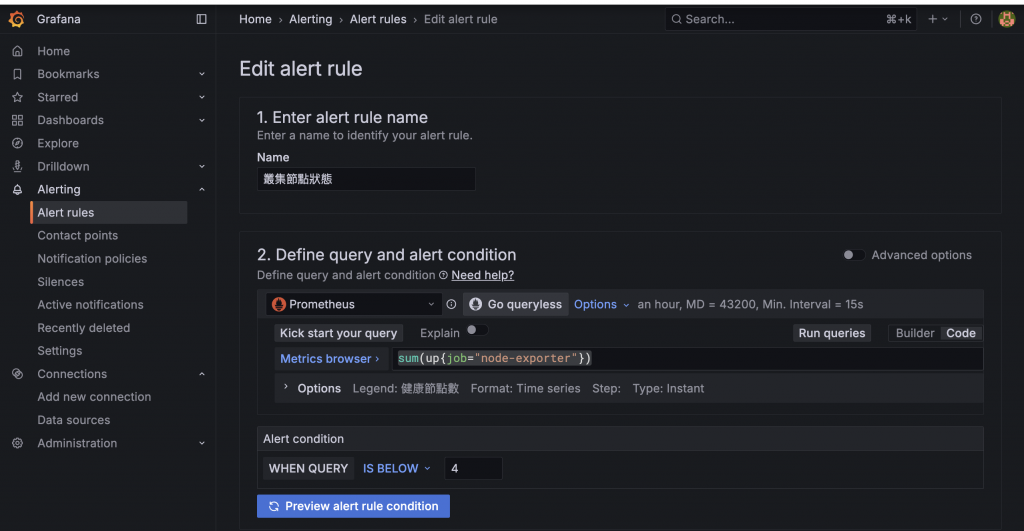
第一步要先定義告警規則,決定了「什麼時候」該發出警報。Query 的地方要輸入一段 PromQL 來抓取我們想監控的指標,這邊以 node-exporter 為例。
# 計算 job 為 "node-exporter" 的健康目標總數
sum(up{job="node-exporter"})
第二步設定 Alert condition 也就是設定觸發條件。假設我們的叢集有 4 個 Node,那麼健康的節點總數就應該是 4。設定當 Query IS BELOW 4 時,觸發告警。
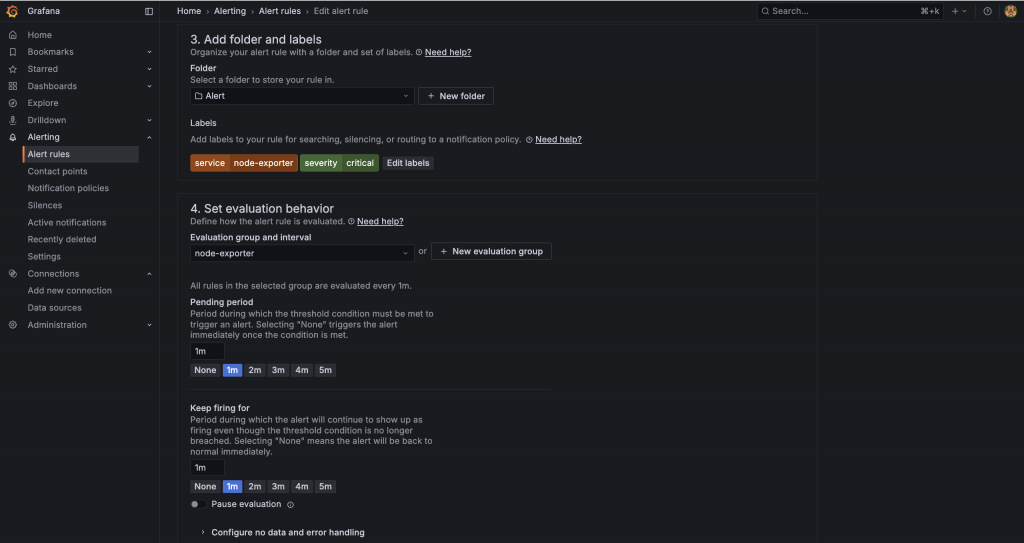
這一步決定了告警的「靈敏度」與「身份」。
severity: critical
service: node-exporter
1m)會來評估一次這個群組的所有規則。5m,代表只有當告警條件連續滿足 5 分鐘後,告警才會真正地進入 Firing(發送中)狀態。這可以避免因為短暫的網路波動或服務重啟,而收到大量的「假警報」。2m 時,即使告警條件已恢復正常,告警狀態仍會強制保持在 Firing 至少 2 分鐘,避免在短時間內收到來回的告警/恢復通知。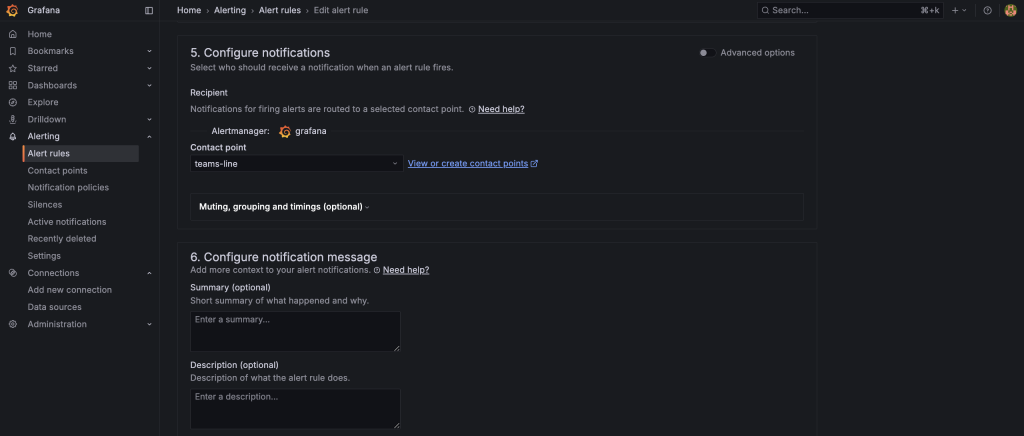
進行到這一步,UI 會要求我們選擇一個 Contact point (聯絡點)。但我們還沒有建立任何聯絡點。所以,讓我們先跳轉一下,來設定我們的通知管道。
Contact Point 就是告警通知的最終目的地。它可以是一個 Email 地址、一個 Slack 頻道,或者是一個 Webhook URL。
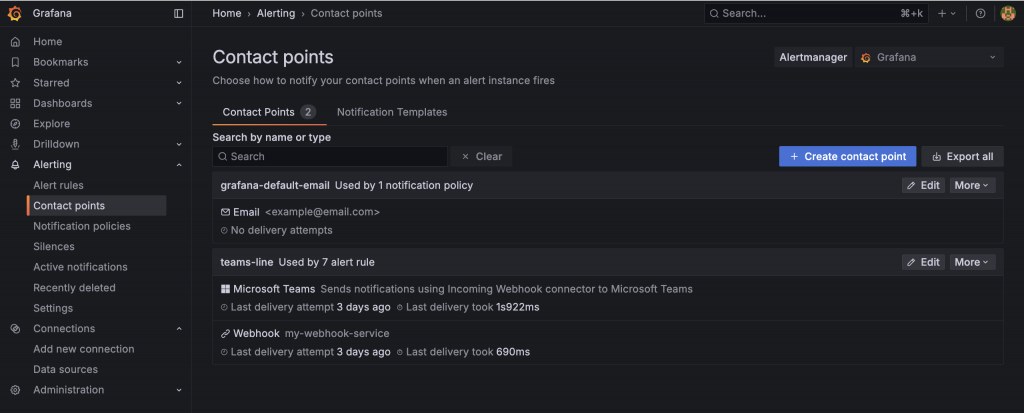
前往 Contact Points 頁面:在 Alerting 頁面,點擊 Contact points 標籤。
新增聯絡點:點擊 Create contact point。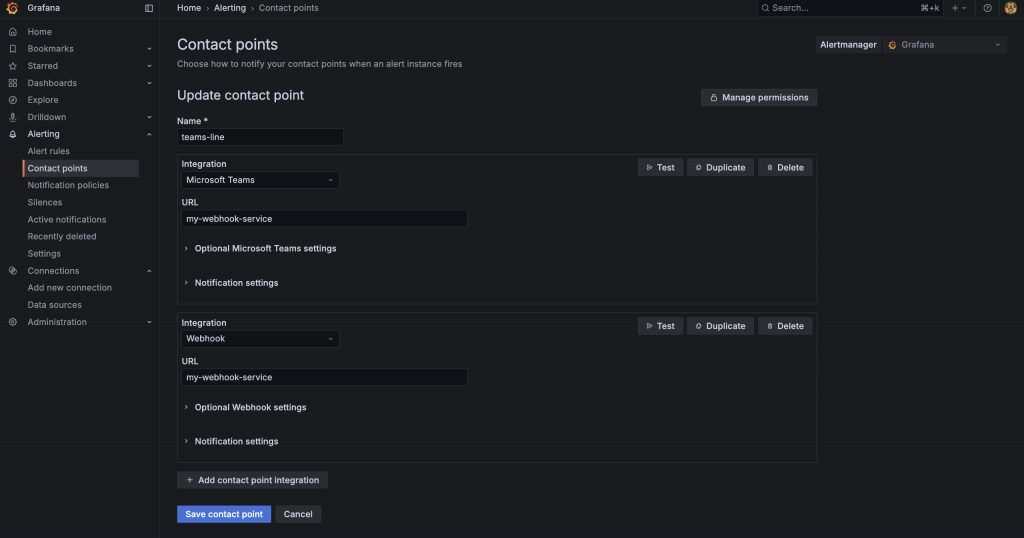
選擇類型:在 Integration 區塊,會看到 Grafana 支援非常多種類型。如果想串接 Line 的話,Line Notify 在今年 3月已經停止提供服務,所以會需要用到 Webhook 去做串接。
Teams 的話則是有直接支援,在 Integration 選擇 Microsoft Teams。然後明天的文章會在統一講解 這些 URL 怎麼取得。
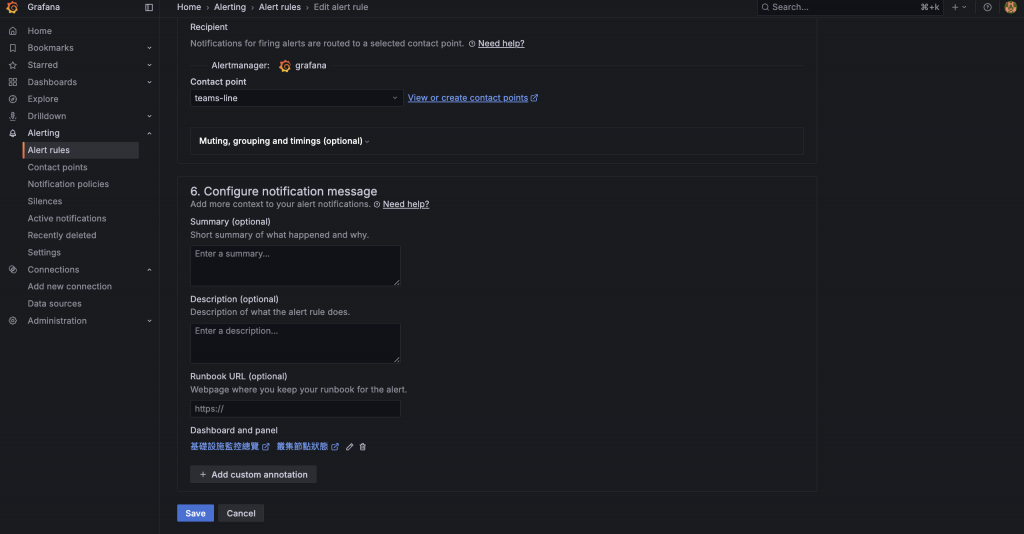
現在,回到我們的告警規則頁面,可以在 Contact point 的下拉選單中,選擇剛剛建立的社群作為這條規則的預設通知對象了,之後就能在 Teams 或 Line 收到告警通知。
最後,在 Configure notification message 區塊,我們可以客製化我們的告警訊息:
服務 {{ $labels.service }} 可能已離線!
偵測到 {{ $labels.service }} 在過去 5 分鐘內的請求速率 (RPS) 低於 0.1。
小知識:{{ $labels.<label_name> }} 是一種模板語法,它可以在發送通知時,動態地將我們在步驟 3 設定的標籤值,嵌入到我們的訊息中,讓告警內容更具體。
完成所有設定後,點擊 Save,我們的第一條告警規則就正式上線了!
在明天的文章中,我們就要來完成這最後、也最酷的一步:親手設定 Teams 和 Line,取得真實的 Webhook URL,並展示如何將 Grafana 的告警訊息,即時地推送到 LINE 中! 明天見!


 iThome鐵人賽
iThome鐵人賽