
昨天我們透過 Namespace 可以避免資源名稱衝突,讓開發、測試、生產環境各自獨立運作。我們也實際操作了如何建立 Namespace,並學會用聲明式方式在 YAML 檔中直接指定 Namespace。
不過在文章最後我提到了一個更深層的問題:Namespace 雖然提供了邏輯隔離,但如何控制每個 Namespace 實際能使用多少資源? 今天我們要看看 ResourceQuota 和 LimitRange,看看如何為不同的 Namespace 設定資源配額和限制。
在了解這兩個工具之前,要先知道 Kubernetes 的一個重要特性:預設情況下,如果沒有特別指定,Pod 是不會限制 CPU 和 Memory 資源的,可以完全占滿 Node 的所有資源。
它們的關係可以想像成宿舍的管理方式:ResourceQuota 就像是限制整層樓總共能用多少水電,而 LimitRange 則是限制每個房間的使用上下限。
ResourceQuota 就是總量的概念,他管的是整個 Namespace 能用多少資源總量,比如說這個 Namespace 總共只能跑 4 個 Pod,或者所有容器加起來最多只能要求 500m 的 CPU。
LimitRange 則是針對「單一容器」做限制,確保沒有人建立超大或超小的容器,也會自動幫沒有設定資源的 Pod 分配預設值。
‼️ LimitRange 限制的對象是 Container,而不是 Pod 或其他資源!
這邊的設計是基於 Linux 的 cgroup 機制,把 CPU 時間分成很多小片段來分配,但是CPU 限制跟記憶體的行為完全不同。
CPU 在 Kubernetes 裡用 m 當單位,代表千分之一核心。所以 1000m = 1 個完整的 CPU 核心,500m 就是半個核心。如果你想要兩個完整核心,可以寫 2 或 2.0。
記憶體的部分就比較直觀了,用的是我們熟悉的容量單位:Mi(Mebibyte)、Gi(Gibibyte)等等。100Mi 就是 100 Mebibyte 的記憶體,1Gi 就是 1 Gibibyte。要注意的是這裡用的是二進制單位(1024 為基底),跟我們平常講的 MB、GB(1000 為基底)稍微不一樣。
在設定資源時會看到 requests 和 limits 兩種設定。Request 就像是跟 Kubernetes 說「我至少需要這些資源才能正常運作」,Limit 則是「我最多只能用到這些資源,超過就不行了」。
CPU Request 是 Kubernetes 調度器在決定要把 Pod 放到哪個 Node 時的參考依據。假設你的 Pod 要求 200m CPU,調度器就會找一個至少還有 200m 可用 CPU 的 Node 來放你的 Pod。
CPU Limit 則是硬性限制,當你的程式真的需要更多 CPU 時,系統會「節流」你的程式,讓它跑得比較慢,但不會把它殺掉。就像限速一樣,你的車不會爆炸,只是被迫開慢一點。
Memory Request 一樣是調度時的參考,確保 Node 有足夠記憶體給你的 Pod。
Memory Limit 就比較殘酷了,如果你的程式真的吃超過這個限制,系統會直接把它 OOM Kill(Out of Memory Kill),Pod 就掛了。這是因為記憶體不像 CPU 可以「慢慢分配」,記憶體就是有就有、沒有就沒有。
我以下的實作都在 ithome 這個 namespace 實作,因此我們先建立 namespace。
kubectl create namespace ithome
先來看看 ResourceQuota 的 YAML 結構,這邊我們直接在 yaml 檔裡面指定 namespace:
apiVersion: v1
kind: ResourceQuota
metadata:
name: compute-resources
namespace: ithome
spec:
hard:
pods: "4"
requests.cpu: "500m"
requests.memory: 100Mi
limits.cpu: "700m"
limits.memory: 500Mi
這樣就把 ResourceQuota 建立起來了。
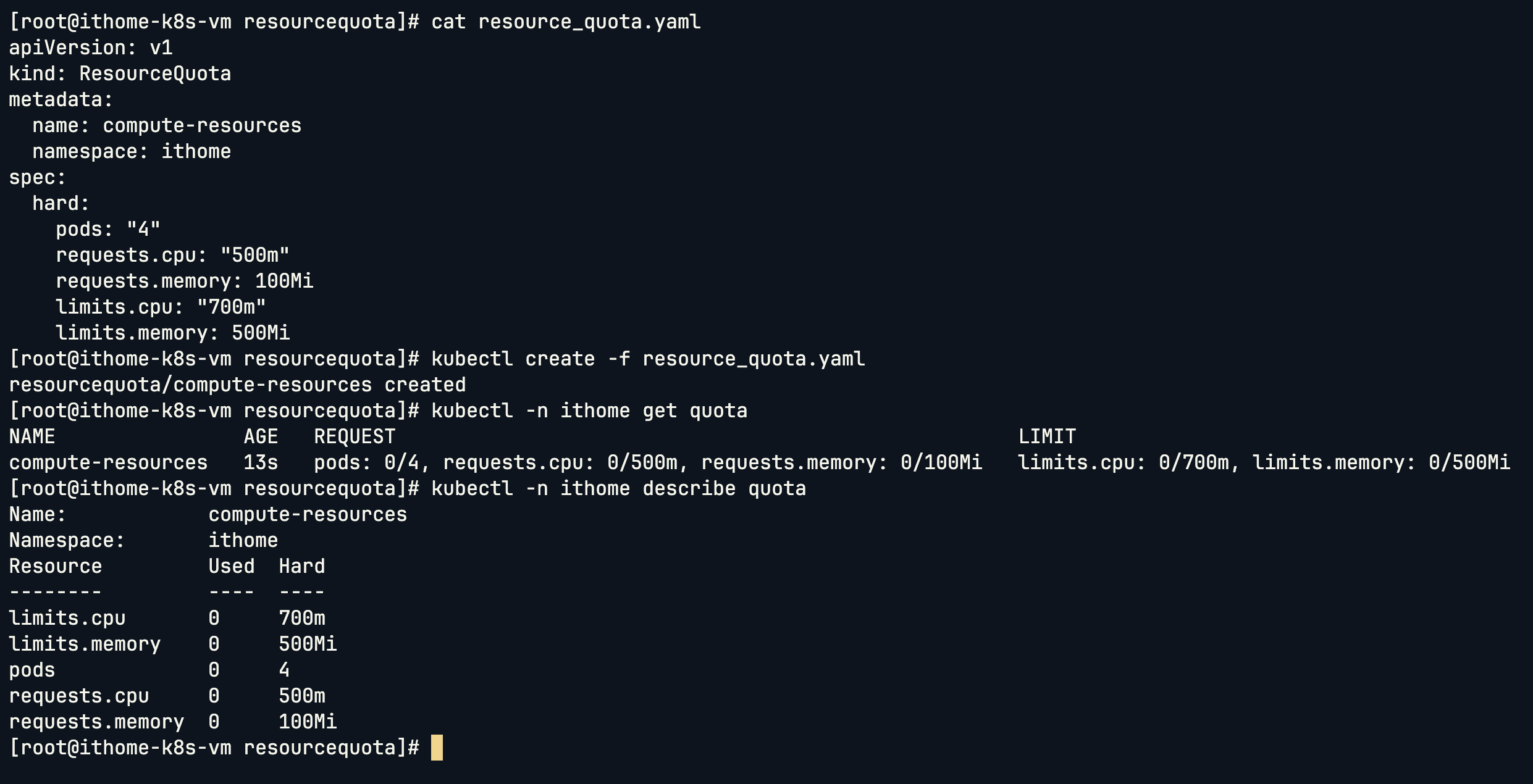
接著我們測試看看當 Pod 超過配額限制時會發生什麼:
apiVersion: v1
kind: Pod
metadata:
creationTimestamp: null
labels:
run: nginx
name: nginx
namespace: ithome
spec:
containers:
- image: nginx
name: nginx
resources:
limits:
cpu: "600m"
memory: 800Mi
requests:
cpu: "100m"
memory: 100Mi
dnsPolicy: ClusterFirst
restartPolicy: Never
status: {}
可以看到這個 Pod 把 limits 的 memory 設到了 800Mi,但是 Quota 只有 500Mi,因此被擋下來不給建立:
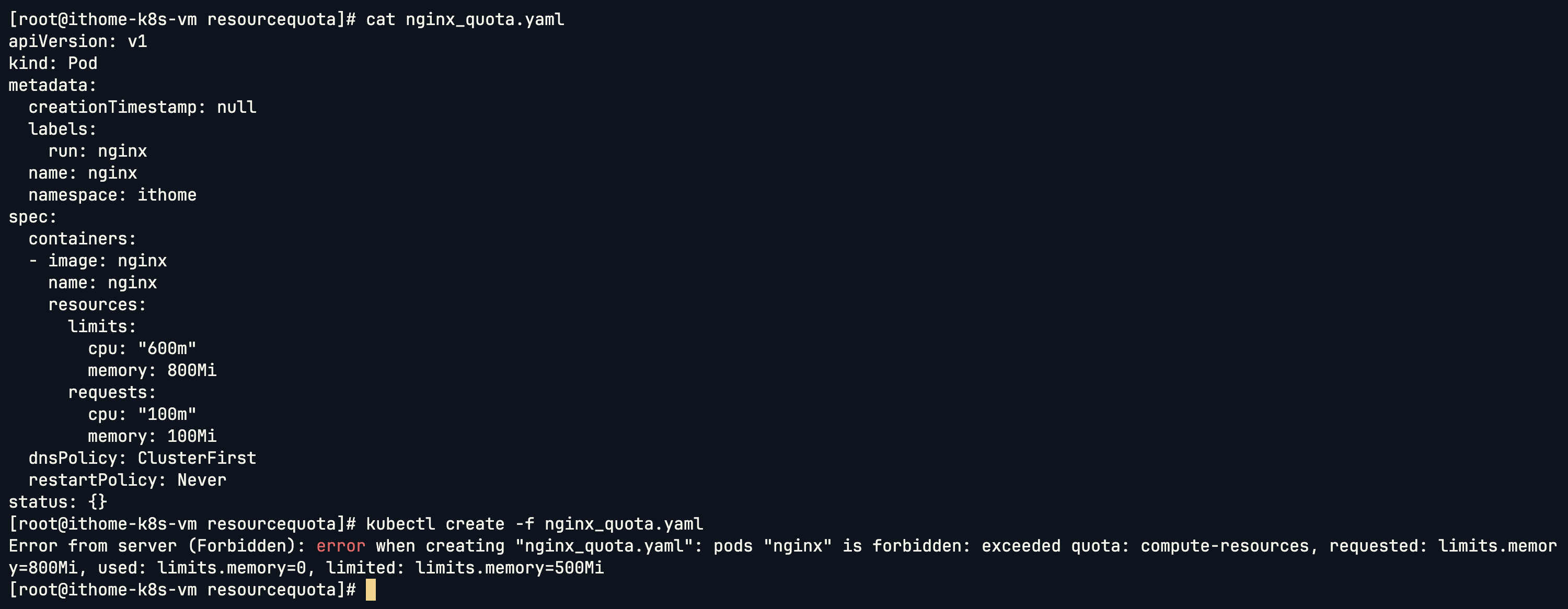
接下來我寫一個腳本來測試建立多個 Pod:
#!/bin/bash
nginx_pod=$1
cat <<EOF | kubectl create -f -
apiVersion: v1
kind: Pod
metadata:
creationTimestamp: null
labels:
run: ${nginx_pod}
name: ${nginx_pod}
namespace: ithome
spec:
containers:
- image: nginx
name: ${nginx_pod}
imagePullPolicy: IfNotPresent
resources:
limits:
cpu: "100m"
memory: 20Mi
requests:
cpu: "100m"
memory: 20Mi
dnsPolicy: ClusterFirst
restartPolicy: Never
status: {}
EOF
可以看到我們一直建立 Pod,最後達到 Quota 的 4 個 Pod 限制之後就不能再建立了:
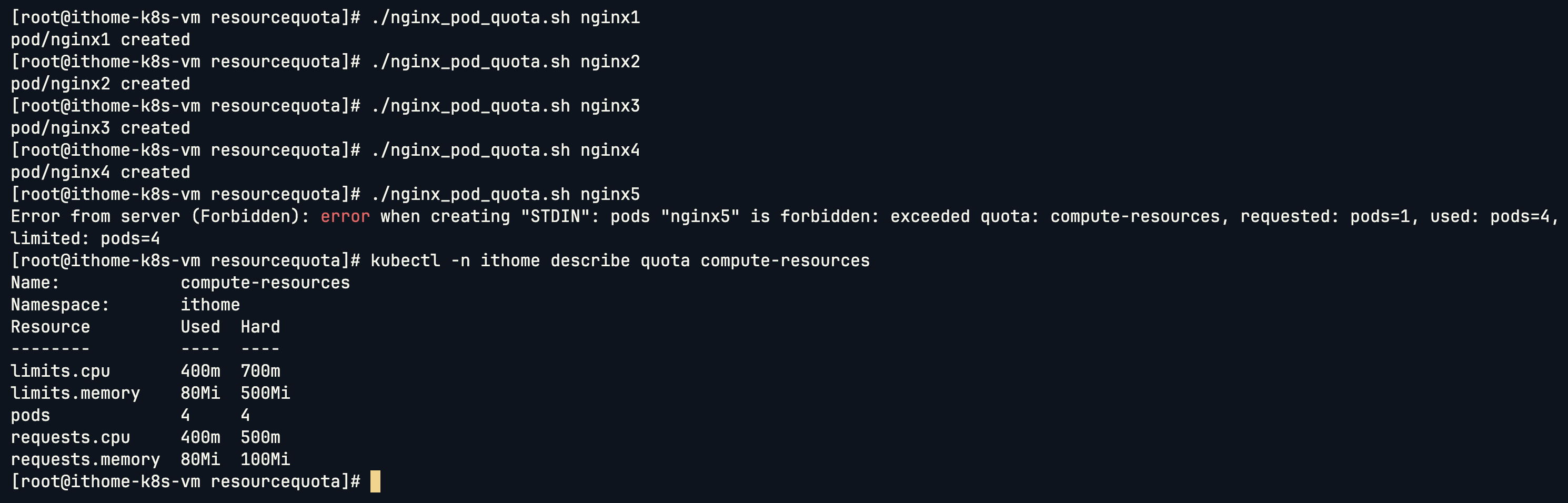
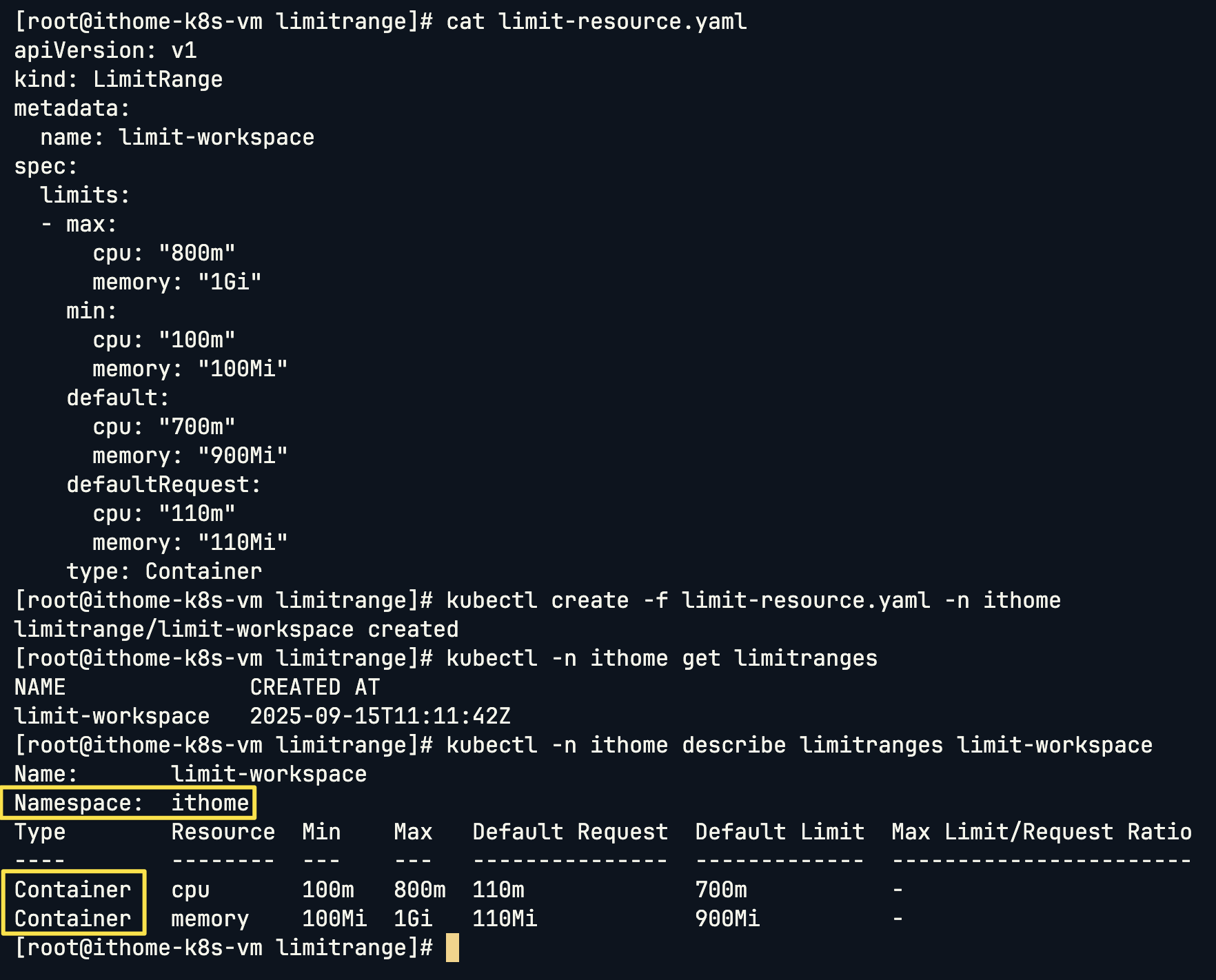
接下來看看 LimitRange 的 YAML 結構,一樣直接指定 ithome namespace:
apiVersion: v1
kind: LimitRange
metadata:
name: limit-workspace
namespace: ithome
spec:
limits:
- max:
cpu: "800m"
memory: "1Gi"
min:
cpu: "100m"
memory: "100Mi"
default:
cpu: "700m"
memory: "900Mi"
defaultRequest:
cpu: "110m"
memory: "110Mi"
type: Container
這邊可以看到有一個欄位是 default,對應到實際生成的結果是 Default Limit。這算是 Kubernetes 的小 bug,明明另一個有寫 Request,但讓人搞不懂為何另一個就只寫 default。🤣🤣
並且可以看到 LimitRange 他是針對 Container 進行資源的限制!!
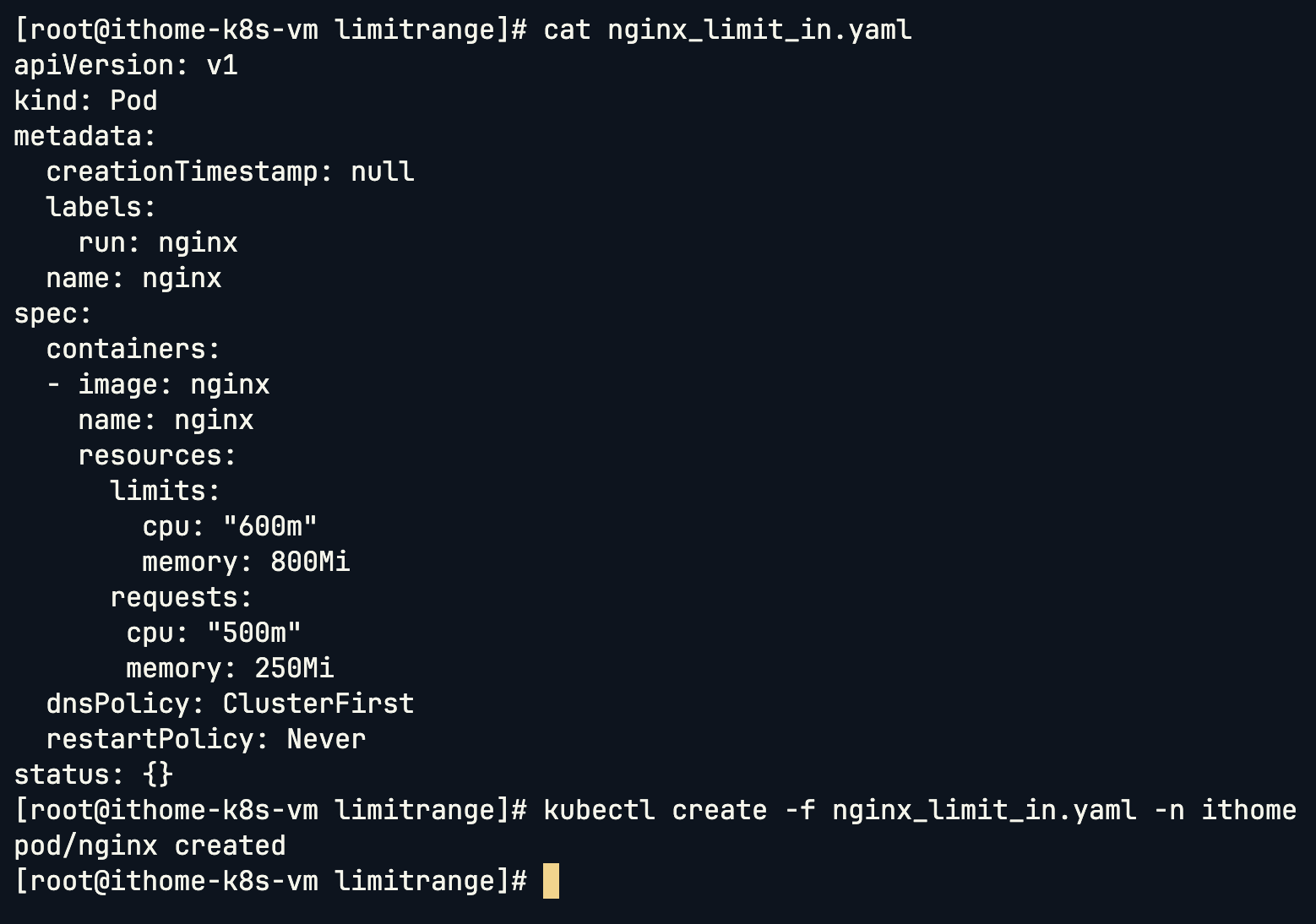
接下來建立一個符合限制的 Pod:
apiVersion: v1
kind: Pod
metadata:
creationTimestamp: null
labels:
run: nginx
name: nginx
spec:
containers:
- image: nginx
name: nginx
resources:
limits:
cpu: "600m"
memory: 800Mi
requests:
cpu: "500m"
memory: 250Mi
dnsPolicy: ClusterFirst
restartPolicy: Never
status: {}
可以看到因為這個 Pod 的 CPU 在我們限制的 100~800m,然後 Memory 也在我們限制的 100Mi~1Gi,因此這個 Pod 成功被建立:
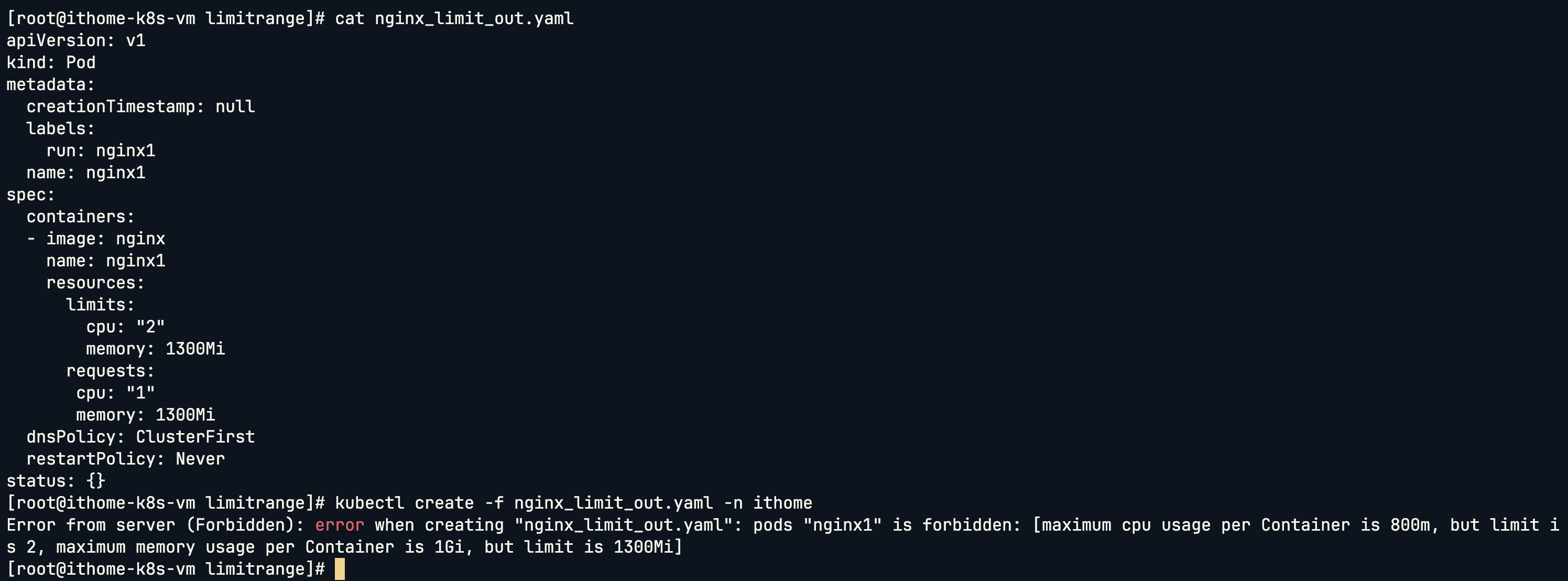
接下來我們測試超過限制的情況,建立一個資源需求過大的 Pod:
apiVersion: v1
kind: Pod
metadata:
creationTimestamp: null
labels:
run: nginx1
name: nginx1
spec:
containers:
- image: nginx
name: nginx1
resources:
limits:
cpu: "2"
memory: 1300Mi
requests:
cpu: "1"
memory: 1300Mi
dnsPolicy: ClusterFirst
restartPolicy: Never
status: {}
下圖可以看到因為不管是 CPU 還是 Memory 都超過我們所設定的 Limit,因此沒辦法被建立:
最後我們測試不設定任何 CPU 和 Memory 限制的情況:
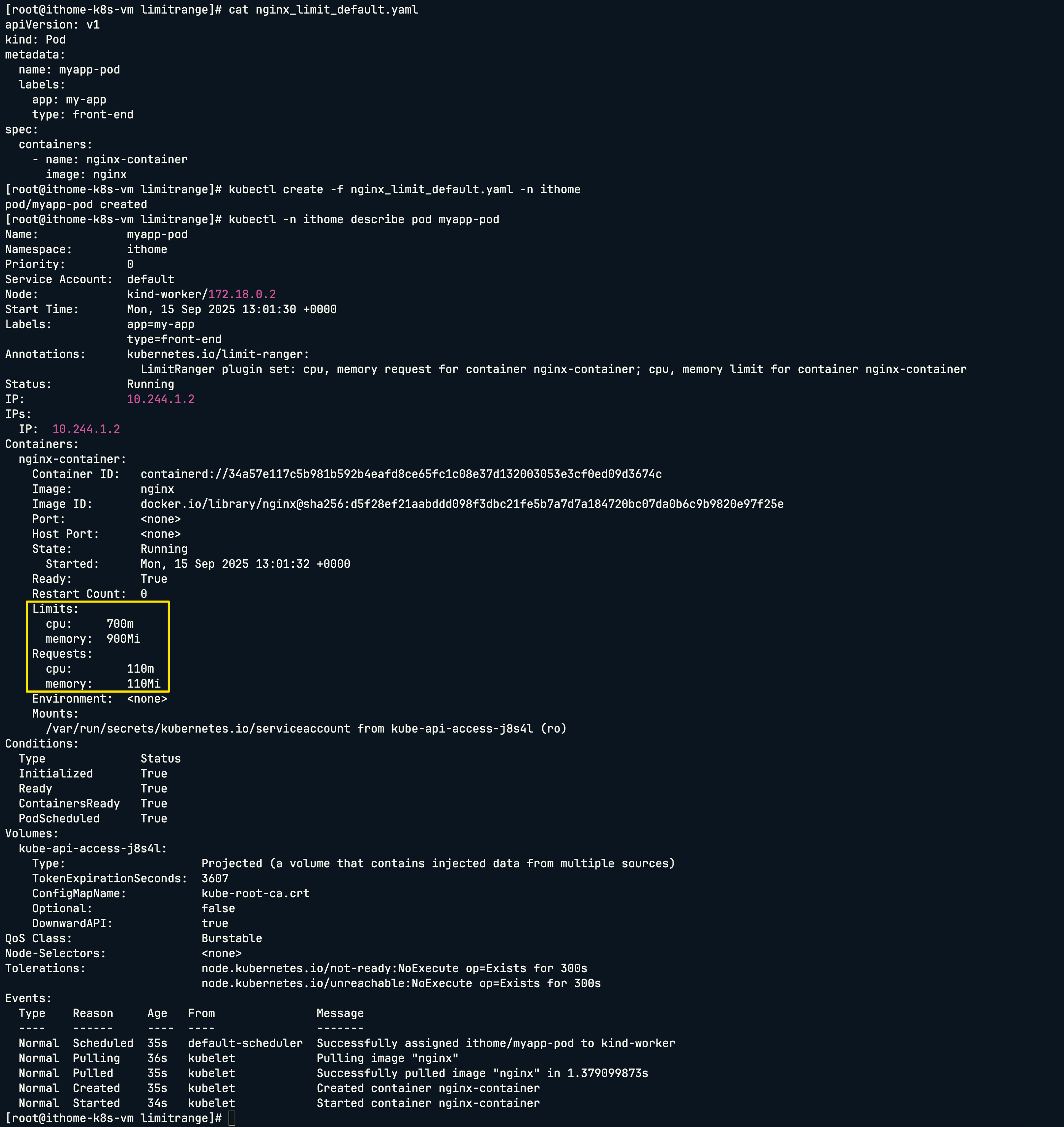
可以看到 Pod 自動帶入我們在 LimitRange 中設定的預設值。
今天我們看了 Kubernetes 的兩個重要資源管理工具:
ResourceQuota 讓我們可以控制整個 Namespace 的資源總量,避免某個團隊或專案把整個叢集的資源吃光。就像公司的預算管制一樣,每個部門都有自己的額度。
LimitRange 則是針對個別容器做限制,確保不會有人建立過大或過小的容器,同時也會自動幫沒有設定資源限制的 Pod 分配合理的預設值。
這兩個工具搭配使用,就能建立一套完整的資源管理機制。在實際的生產環境中,合理的資源配額設定不但能避免資源濫用,也能讓團隊更有效率地使用叢集資源。這些概念在一開始可能看起來有點抽象,但只要動手試試,其實發現它們很好理解。
到目前為止我們已經看了很多重要的資源物件了,不過光是這樣還不夠,應用程式通常需要一些設定檔和敏感資料才能正常運作。比如資料庫連線字串、API Keys、應用程式的設定參數等等。明天我們要來看看 ConfigMap 和 Secret,看看 Kubernetes 如何幫我們儲存這些參數!

