在上篇 DAY1 知識之章-啟程 中,我們聊到本系列文章的整體規劃。
本篇將介紹此系列會使用到的資料集,讓我們一起來看看資料的來源與資料結構。
MyAnimeList 是一個英文語系的「動畫與漫畫社交編目網站(social cataloging application)」,結合資料庫與社交功能,讓使用者能搜尋、追蹤、評分與分享動畫與漫畫資訊。
資料庫規模與使用規模:
本篇我們要分析的資料為動漫資料集,來源為 Kaggle 資料集提供者 Ramazan Turan 所提供的 User Animelist Dataset。
本次目標的資料檔案有兩個,分別為:
本次資料集共有 1,774,522 使用者評價,且動漫數量也有 20,237 筆,資料量已足夠讓我們來做數據分析。
資料集統計:
資料介紹:
animeID:動漫 IDtitle:動漫名稱alternative_title:替代動漫名稱type:類型year:發行年score:評分episodes:集數mal_url:MyAnimeList URLsequel:有無續集image_url:動漫圖片 URLgenres:風格genres_detailed:風格細節userID:使用者 IDanimeID:動漫 IDrating:評分點選 Kaggle 此 User Animelist Dataset 頁面右上角的 「Download」按鈕。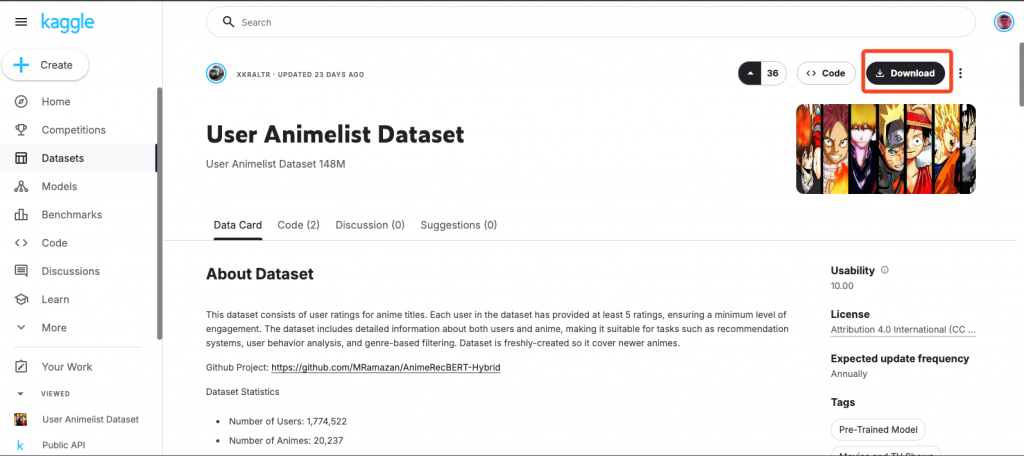
接著點選「Download dataset as zip」下載 ZIP 檔案。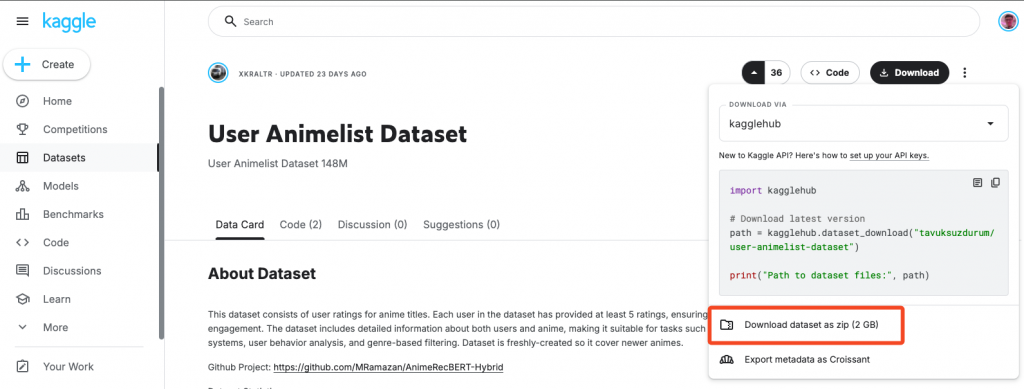
最後選擇你想存放檔案的路徑即可點選「儲存」做下載。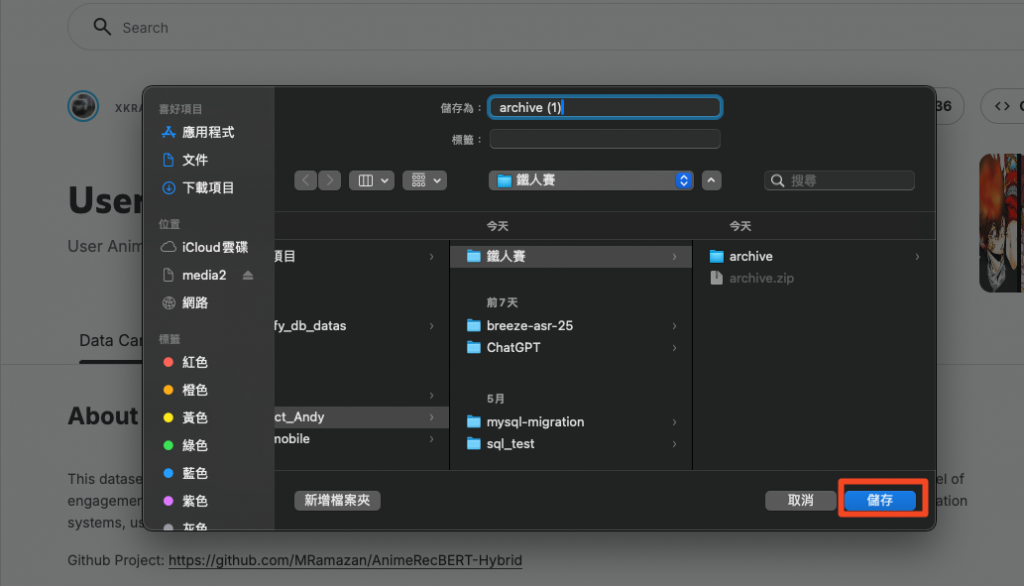
將「archive.zip」檔案解壓縮後,確認是否有我們需要的資料:
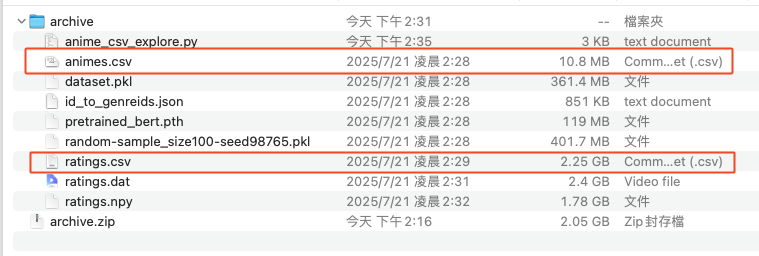
要怎麼於 Local 先快速的確認資料呢?
接著透過 Python 來做一個資料的統計檢視:
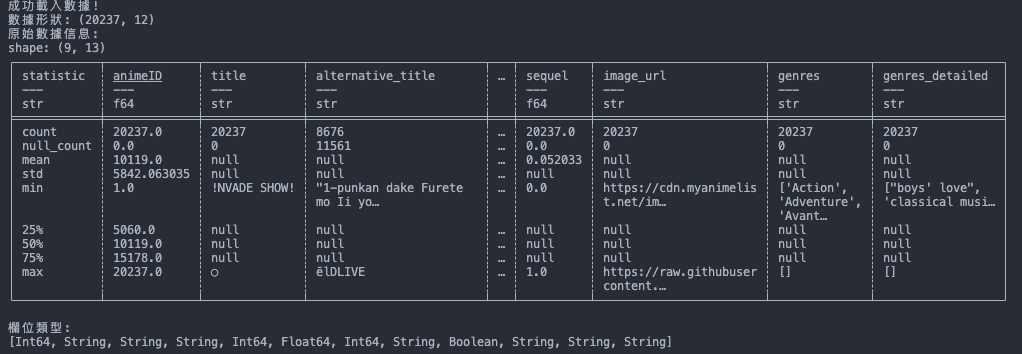
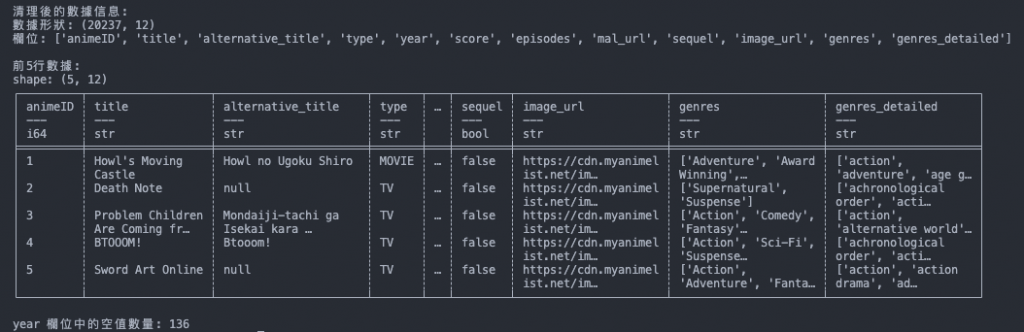
此程式我們先做個參考就好,因為後續我們將於 「淬鍊之章」 使用 Glue 的 PySpark 來處理資料。
程式碼:
import polars as pl
def load_anime_data(file_path):
"""
Load anime data from a CSV file into a Polars DataFrame.
Args:
file_path (str): Path to the CSV file containing anime data.
Returns:
polars.DataFrame: DataFrame containing the anime data.
"""
try:
# 方法1: 將 "?" 添加到 null_values 列表中
df = pl.read_csv(
file_path,
null_values=["?", "N/A", "NULL", "null", ""], # 將問號視為空值
infer_schema_length=10000 # 增加推斷模式的行數
)
return df
except Exception as e:
print(f"Error loading data with method 1: {e}")
# 方法2: 如果方法1失敗,嘗試忽略錯誤
try:
df = pl.read_csv(
file_path,
null_values=["?", "N/A", "NULL", "null", ""],
ignore_errors=True,
infer_schema_length=10000
)
return df
except Exception as e2:
print(f"Error loading data with method 2: {e2}")
# 方法3: 強制將所有欄位讀取為字符串,後續再轉換
try:
df = pl.read_csv(
file_path,
dtypes=pl.Utf8 # 將所有欄位讀取為字符串
)
# 後續可以手動轉換特定欄位的類型
return df
except Exception as e3:
print(f"Error loading data with method 3: {e3}")
return None
def clean_and_convert_data(df):
"""
清理和轉換數據類型
"""
if df is None:
return None
try:
# 顯示原始數據信息
print("原始數據信息:")
print(df.describe())
print("\n欄位類型:")
print(df.dtypes)
# 如果 year 欄位存在且為字符串類型,嘗試轉換
if 'year' in df.columns and df['year'].dtype == pl.Utf8:
df = df.with_columns([
# 將 "?" 替換為 None,然後轉換為整數
pl.col('year').str.replace(r'^\?$', None).cast(pl.Int64, strict=False).alias('year')
])
print("\n清理後的數據信息:")
print(f"數據形狀: {df.shape}")
print(f"欄位: {df.columns}")
return df
except Exception as e:
print(f"清理數據時發生錯誤: {e}")
return df
if __name__ == "__main__":
file_path = "animes.csv"
# 載入數據
anime_df = load_anime_data(file_path)
if anime_df is not None:
print("成功載入數據!")
print(f"數據形狀: {anime_df.shape}")
# 清理和轉換數據
cleaned_df = clean_and_convert_data(anime_df)
# 顯示前幾行數據
print("\n前5行數據:")
print(cleaned_df.head())
# 檢查是否有空值
if 'year' in cleaned_df.columns:
null_count = cleaned_df['year'].null_count()
print(f"\nyear 欄位中的空值數量: {null_count}")
else:
print("無法載入數據,請檢查文件路徑和文件格式。")
本篇我們介紹了本系列將使用的動漫資料集,同步理解了資料的源頭和資料結構。
接著發現資料集內有些髒資料,需要再進行資料清洗,此部分讓我們放到後面的章節再來詳細介紹如何針對贓資料做資料的清洗!
下篇我們的主題為「DAY3 知識之章 - Data Lake,Warehouse and Lakehouse」,將簡單介紹以下三種資料架構的差異:
[1] 維基百科-MyAnimeList
[2] MyAnimeList
[3] Kaggle 資料集


 iThome鐵人賽
iThome鐵人賽