本篇將實際建立 CloudWatch Metric、Alarm、以及 CloudTrail 操作紀錄。
在上一篇 「Day28 維運之章 - CloudWatch、CloudTrail」 中,我們了解了這兩個服務的定位與差異:
本篇將帶你實際操作:
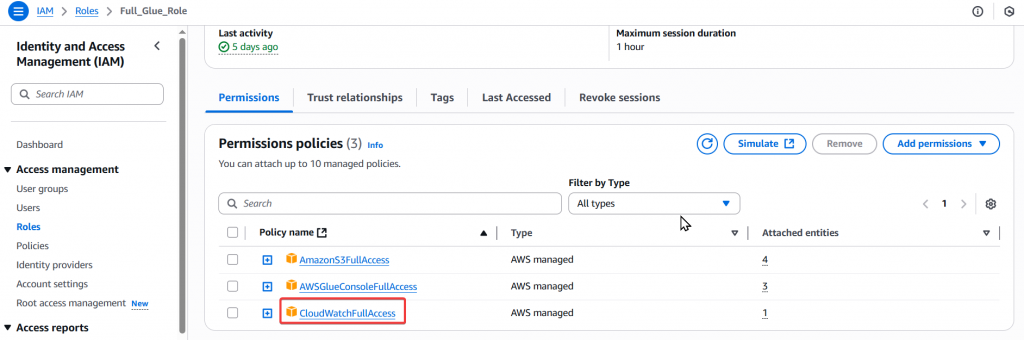
Step1:透過使用者 Joe 為 Full_Glue_Role Role 添加 CloudWatchFullAccess Policy
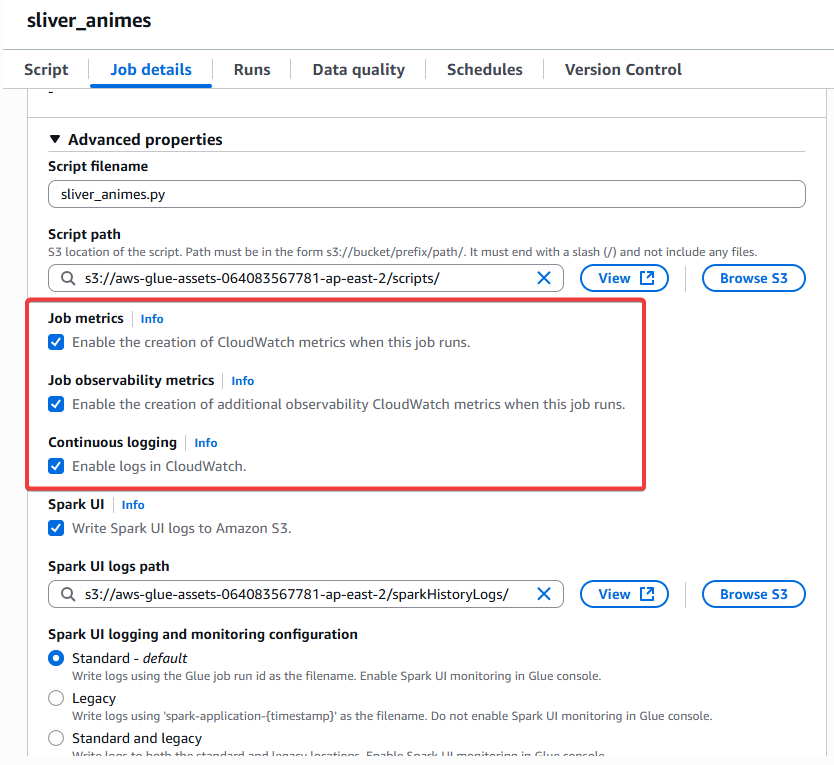
Step2:確保 Glue Job sliver_animes 有開啟相關的功能
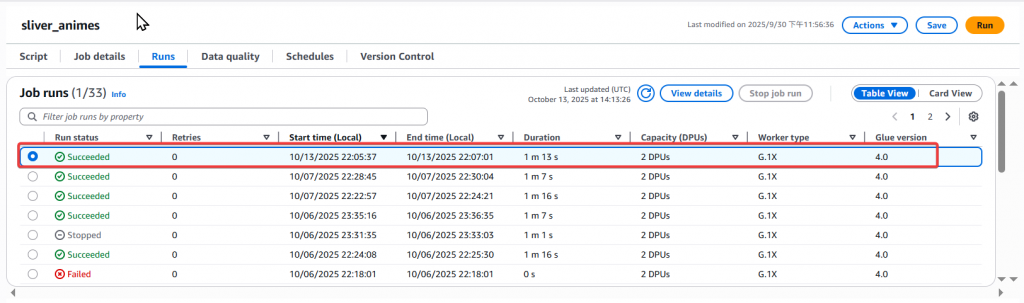
Step3:重跑 Glue Job sliver_animes
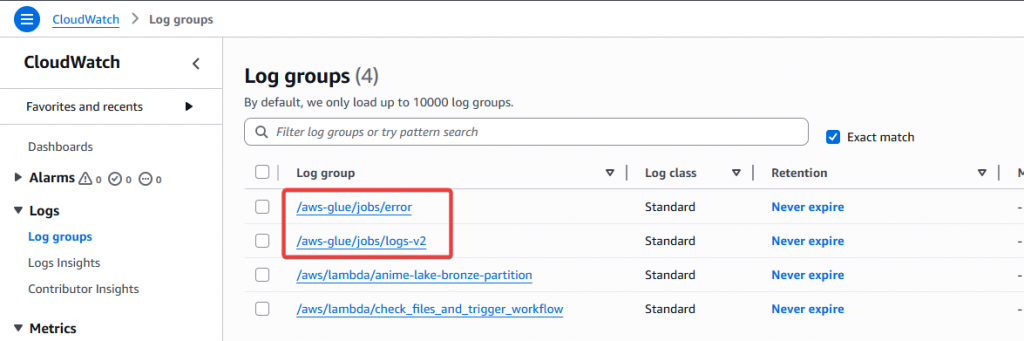
Step4:再次進入 CloudWatch 查看 Log groups,可以發現多出了兩個 Glue 相關的 Group
Step5:查看 /aws-glue/jobs/logs-v2 內容
logs-v2 Group 內還可以再看到多個 Log stream 以及 Last event time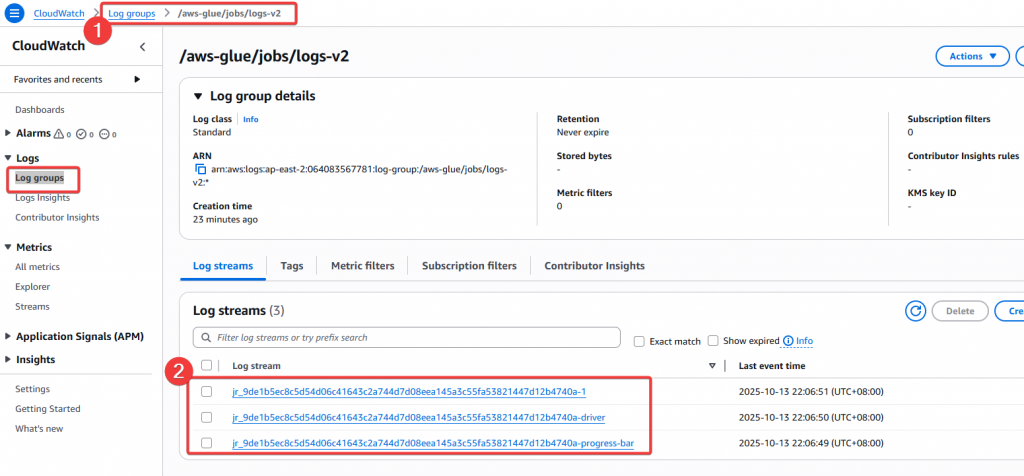
進入 Log stream:jr_9de1b5ec8c5d54d06c41643c2a744d7d08eea145a3c55fa53821447d12b4740a-1
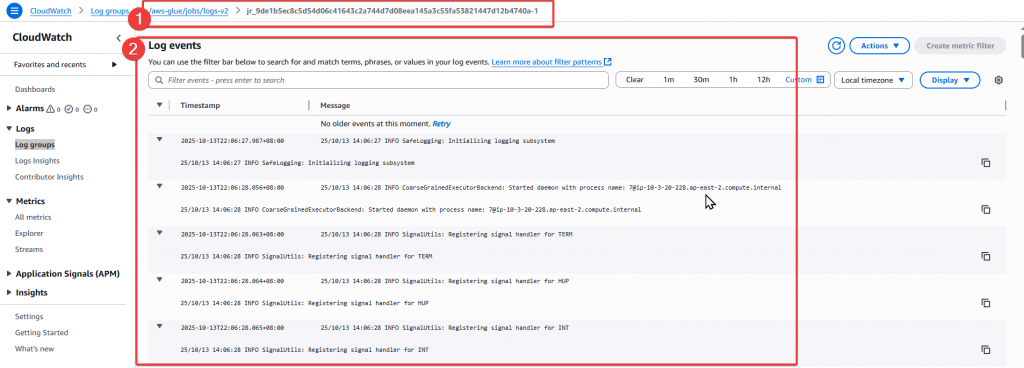
透過新增 Policy 給 Role 之後,我們可以正常的蒐集到 Glue 的相關執行 log,其他 AWS 服務也可以透過將 服務執行狀況的 log 紀錄載入到 CloudWatch 來做查驗。
Step1:進入 CloudWatch Metrics 頁面確認所有的 Metrics 內容,並點選 Glue 的 Metrics
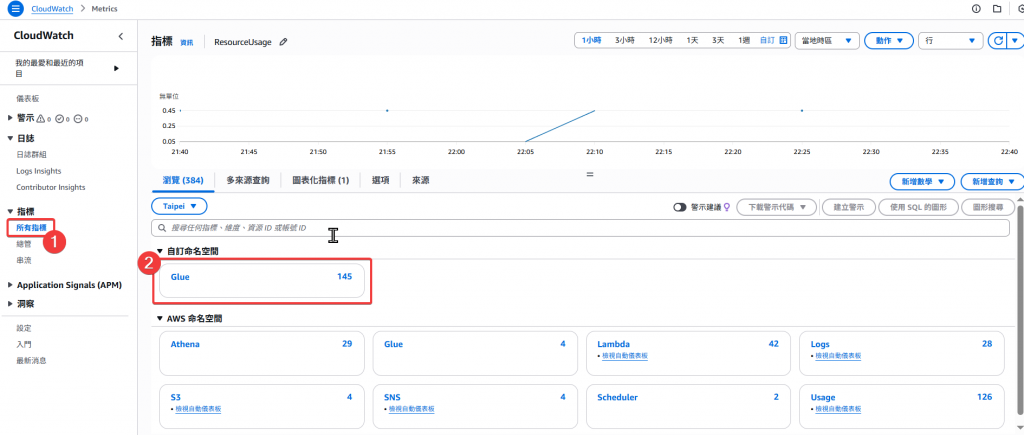
Step2:確認 Glue 取得的相關 Metrics
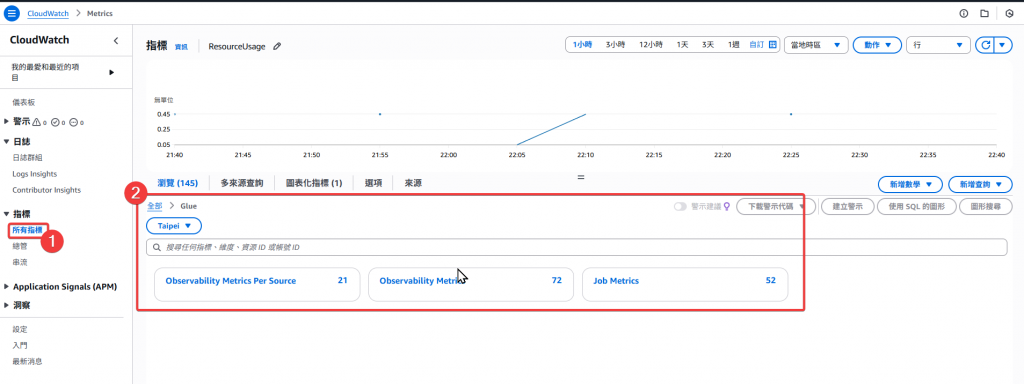
Step3:透過勾選 Metrics 提供上方簡易的指標可視化線圖呈現資料,並且可以在下方看到相關的欄位
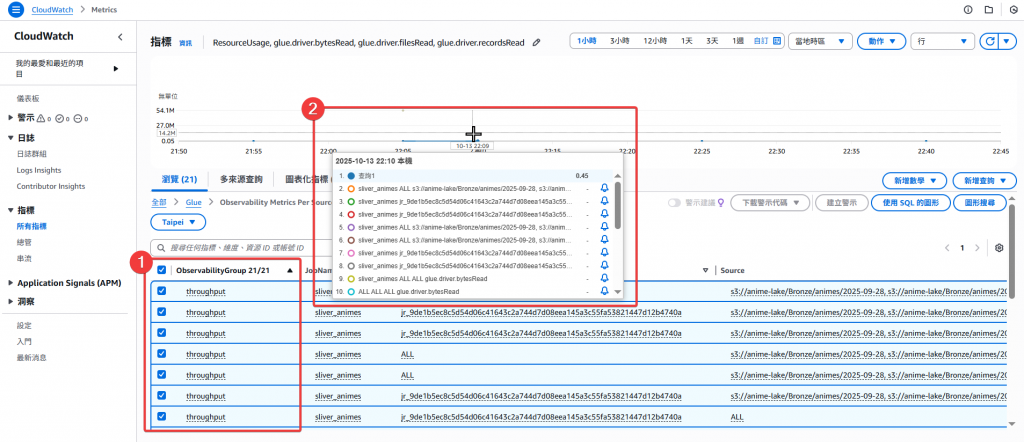
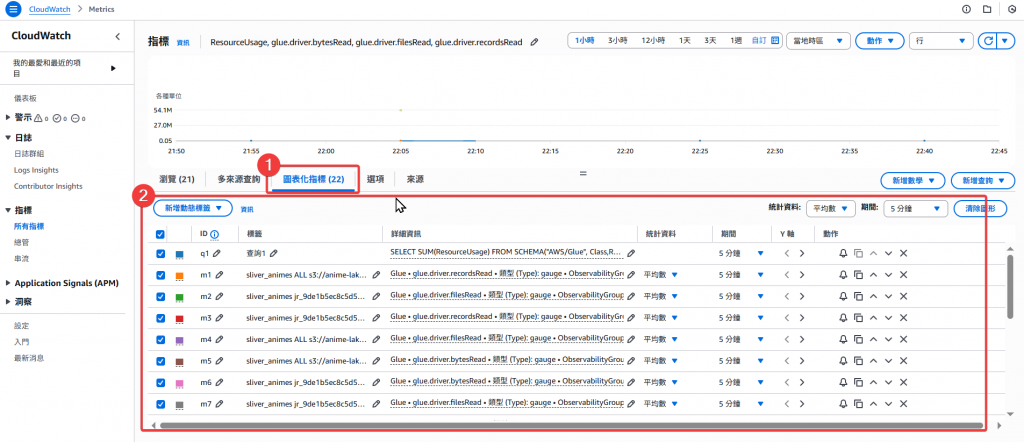
Step4: 點選「圖表化指標」頁籤,可以更清楚的看到相關欄位資訊
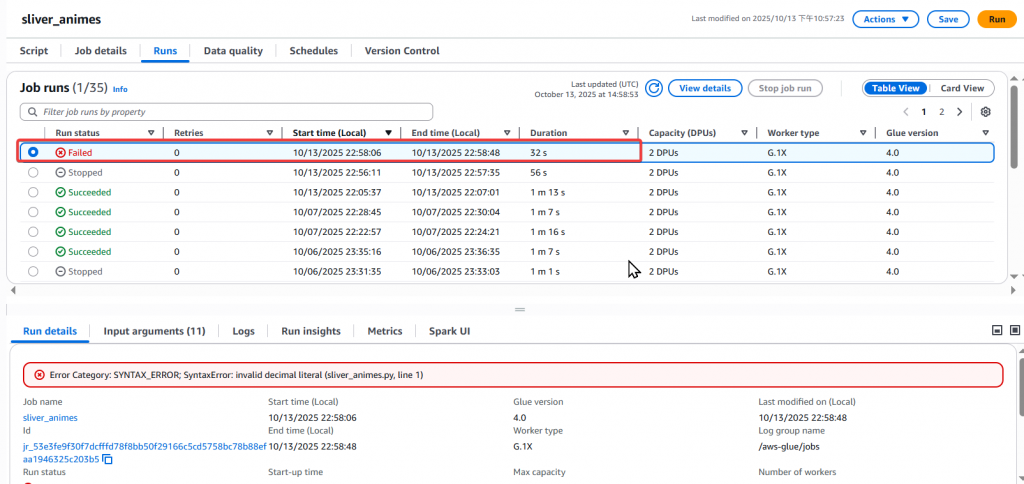
Step5:接著我們隨便調整 Glue Job sliver_animes 使其失敗
Step6:找到 Glue Job 失敗的 Metrics
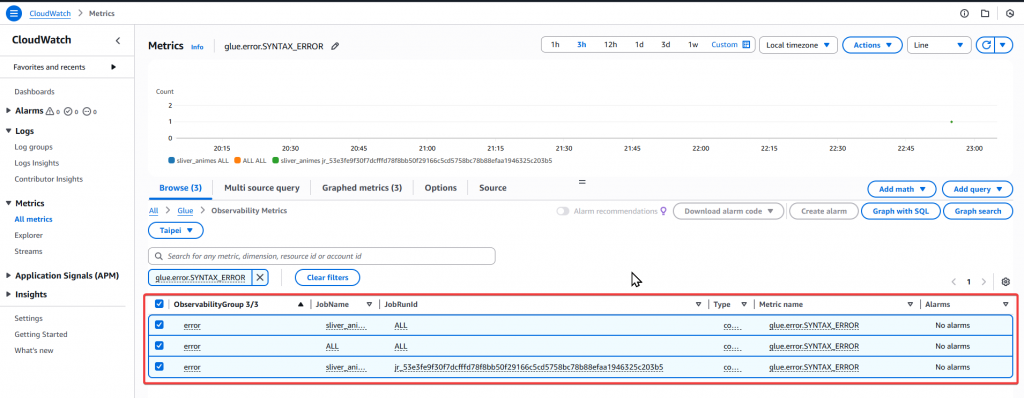
以上即完成了產生 Glue Job 失敗 Metrics 的步驟,接下來我們再解釋一下相關 Metrics 的內容。
在新版 AWS Glue (v4 / v5) 中,官方已經將原本的 JobRunsFailed、JobRunsSucceeded 指標改為以「Error Category(錯誤類別)」 為核心的觀測性指標 (Observability Metrics)。
這些指標會自動上傳到 CloudWatch → Metrics → Glue → Observability Metrics,
幫助我們即時監控 Glue Job 的成功、錯誤與資源使用狀況。
Glue 會針對每個 Job 建立多種錯誤與成功指標,常見如下:
| 類別 | 指標名稱 | 說明 |
|---|---|---|
| 成功 | glue.succeed.ALL |
Job 成功完成的總次數 |
| 語法錯誤 | glue.error.SYNTAX_ERROR |
Python 或 Spark 程式碼語法錯誤(如缺冒號、括號不符) |
| 使用者錯誤 | glue.error.USER_ERROR |
例如 S3 路徑錯誤、Schema 不符、IAM 權限不足 |
| 資源錯誤 | glue.error.RESOURCE_ERROR |
記憶體不足或 Executor 無法分配 |
| 系統錯誤 | glue.error.INTERNAL_ERROR |
AWS Glue 系統層級錯誤 |
| 逾時錯誤 | glue.error.TIMEOUT_ERROR |
Job 執行時間超過限制被中止 |
| 所有錯誤總和 | glue.error.ALL |
聚合所有錯誤類型 |
| 重試任務 | glue.retry.ALL |
Glue 自動重試次數統計 |
| JobName | JobRunId |
|---|---|
silver_animes / ALL |
聚合該 Job 所有執行的語法錯誤總數 |
ALL / ALL |
統計帳號內所有 Glue Job 的語法錯誤總和 |
silver_animes / jr_XXXX |
單次 Job 執行的語法錯誤次數 |
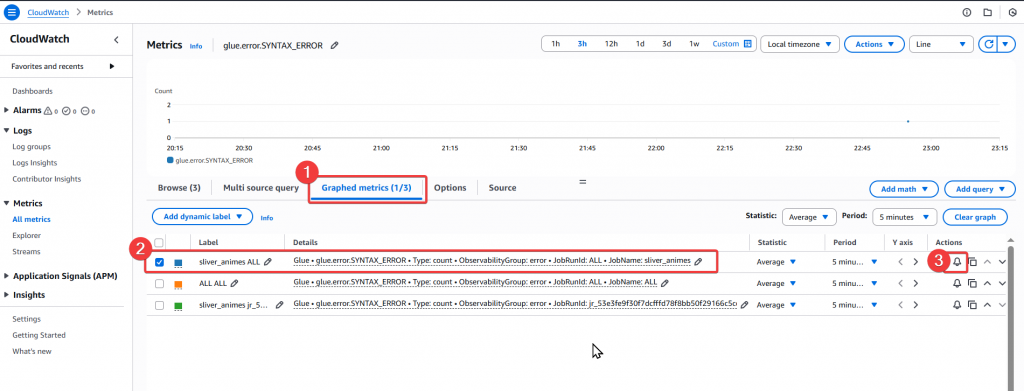
Step1:先至 Graphed metrics 頁籤,找到該 Metric,接著點選該筆 Metric 右邊的小鈴鐺
glue.error.SYNTAX_ERROR
silver_animes
ALL
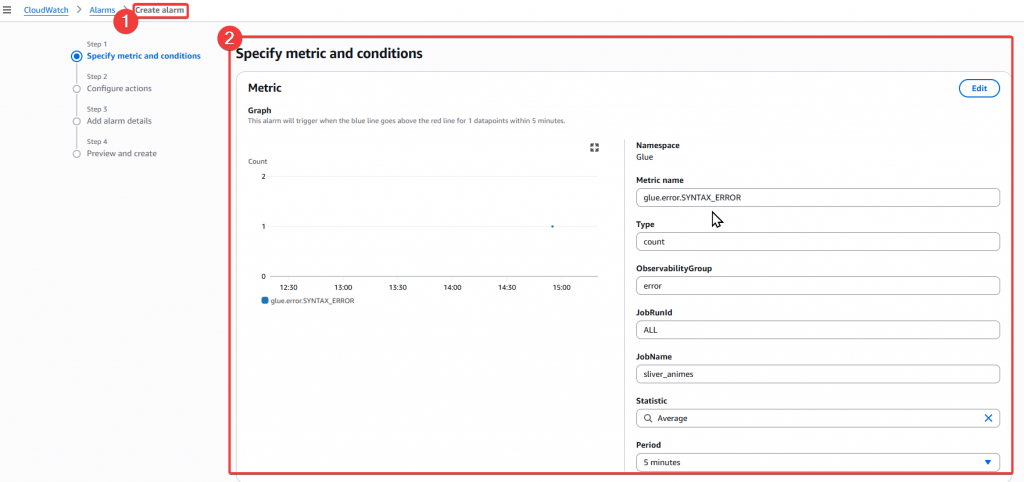
Step2:點選鈴鐺後,會跳轉至 Create Alarm 的頁面
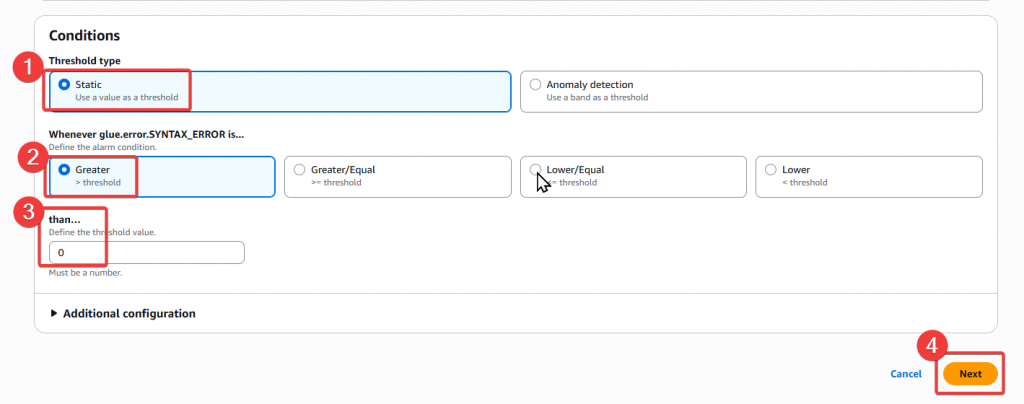
Step3:接著我們要設定 Alarm 的條件
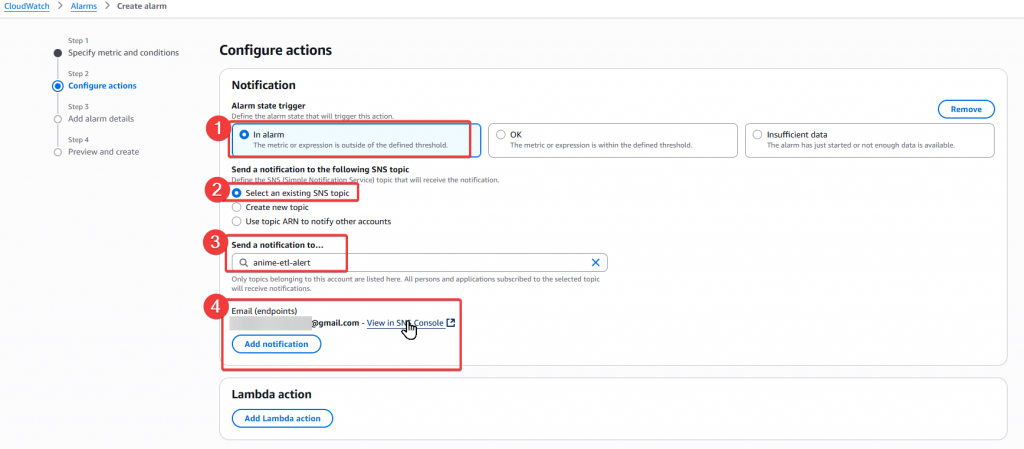
Step4:再來要選擇傳輸的 SNS Topic,我們可以先選擇之前建立的 anime-etl-alert 即可點選下一步
若有需要調整,可再自行建立別的 SNS Topic。
Step5:接下來要為這個 Alarm 命名,我們先命名為 glue_fail_alarm,接著按下一步
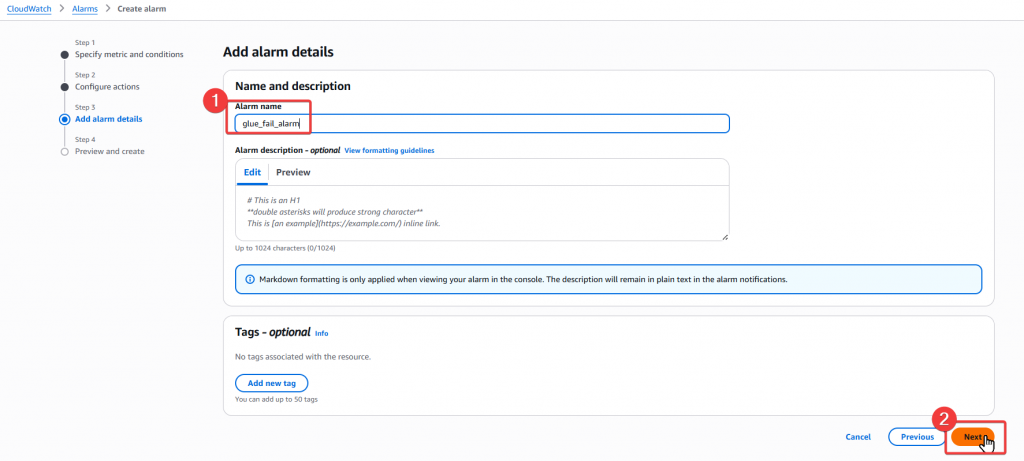
Step6:最後要來確認剛剛選擇的內容是否正確,若確認後沒問題,即可點選 Create Alarm 完成建置作業
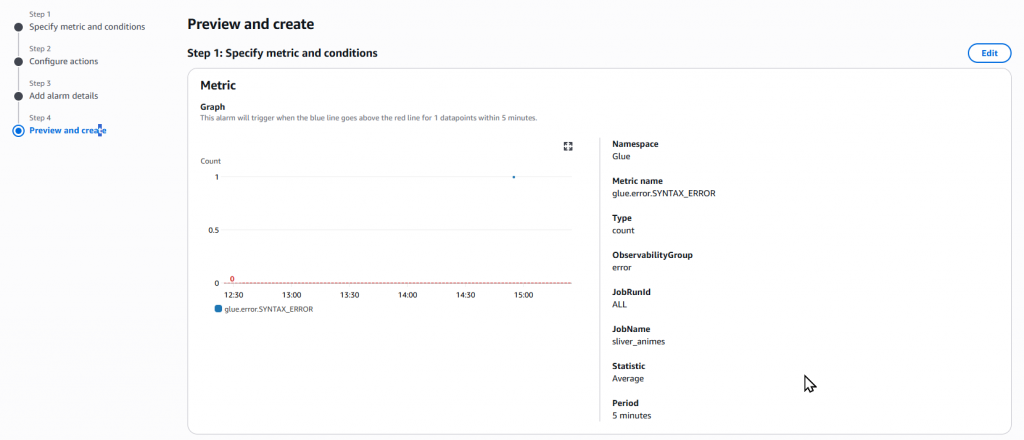
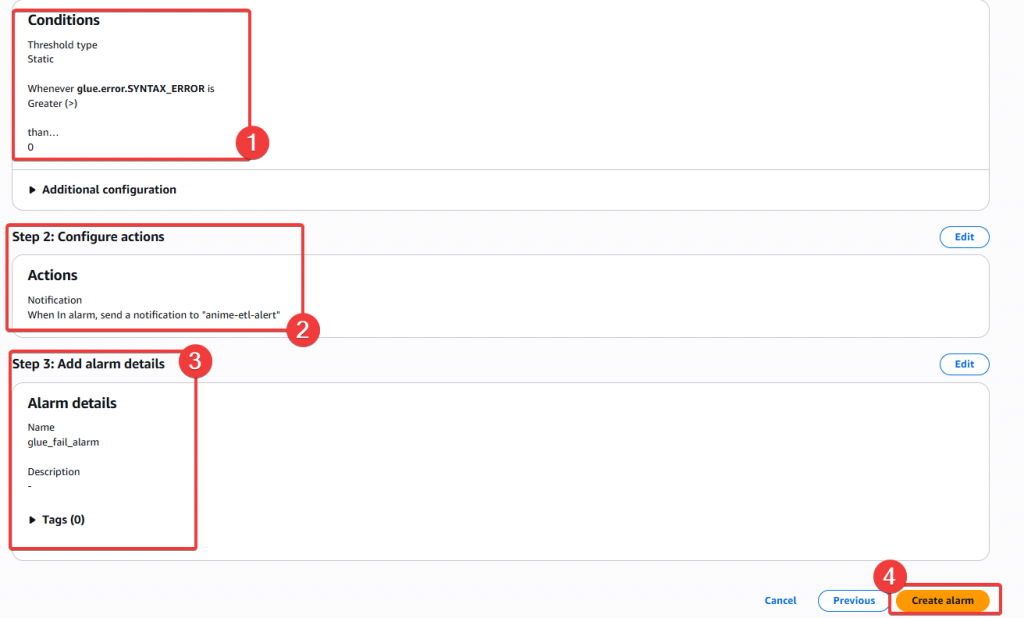
Step7:跳轉頁面後,確認是否有正常建立 Alarm 和啟用

Step8:驗證 Email 信箱是否有正常收到 Alarm 通知
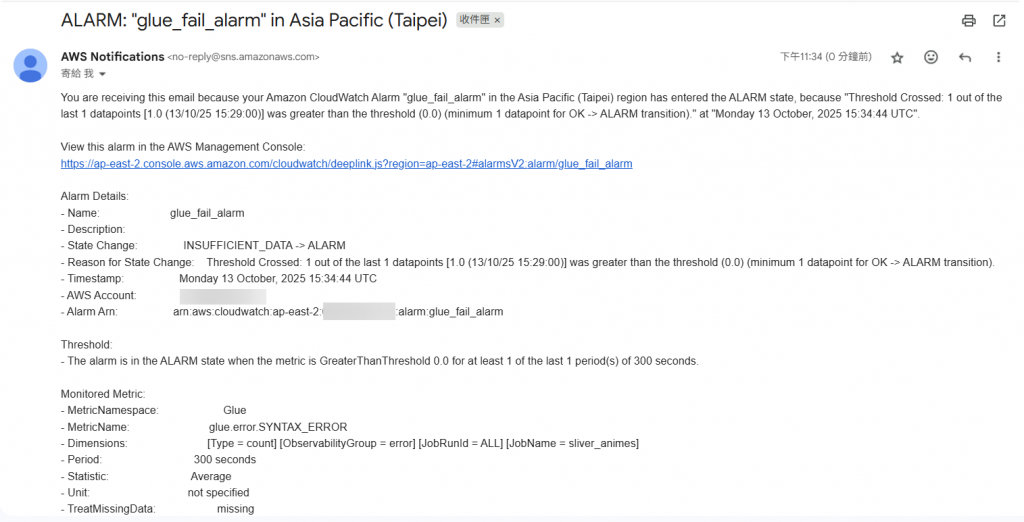
以上即完成 Metrics Alarm 的建置,可以再透過不同的指標,搭配設定不同的 alarm,來滿足使用場景的警示通知機制。
| 類型 | 說明 | 範例 |
|---|---|---|
| Management Events | 資源層級操作(建立、刪除、修改設定) | 建立 Glue Job、修改 IAM Role |
| Data Events | 物件層級操作(例如 S3 檔案上傳 / 下載) | 上傳、刪除 S3 檔案 |
| Insights Events | 偵測異常行為 | 突然大量刪除 Bucket、IAM 登入異常 |
本次實作我們要來建置 S3 Bucket 的 Trail。
Step1:首先我們先透過使用者 Joe 進入 CloudTrail Dashboard 頁面
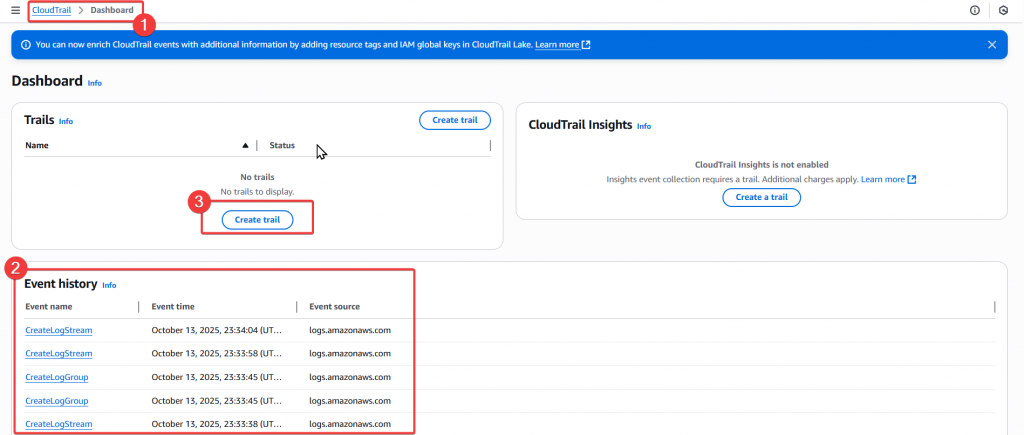
Step2:設定相關內容
s3-anime-lake-trail
anime-lake Buckets3-anime-lake-kms
CloudTrail_s3_anime_lake
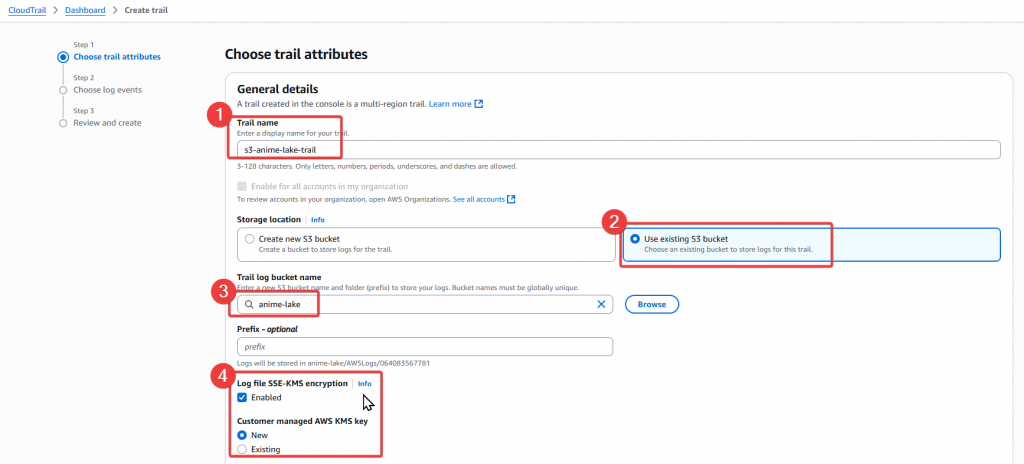
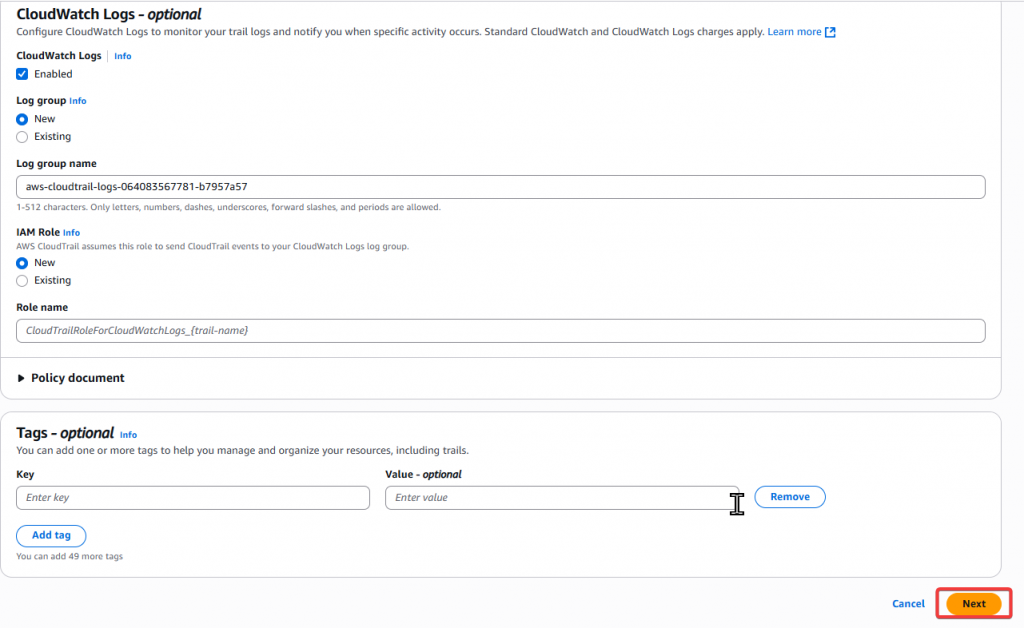
Step3:Event 設定
簡易介紹:
| 事件類型 | 說明 | 常見用途 | 建議 |
|---|---|---|---|
| ✅ Management events | 控制層操作(建立 / 修改 / 刪除資源) | 誰建立了 S3 Bucket?誰修改了 Glue Job? | 必開 |
| ✅ Data events | 資料層操作(對物件的操作) | 誰上傳或刪除了 S3 檔案? | 必開 |
| 🧠 Insights events | 自動偵測異常行為 | 登入異常、API 暴增、異常刪除行為 | 建議開啟 |
| 🌐 Network activity events | 監控 VPC Endpoint 內的資源操作 | 追蹤內網流量(Private VPC / S3 Gateway Endpoint) | 視情況開啟 |
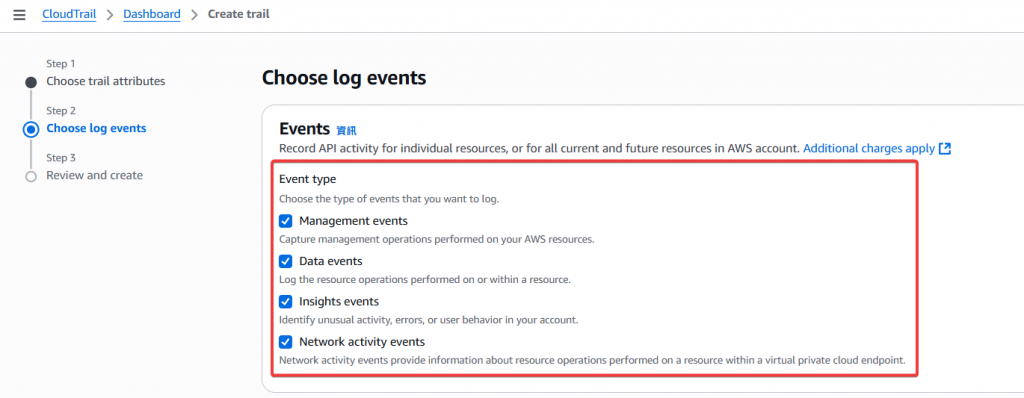
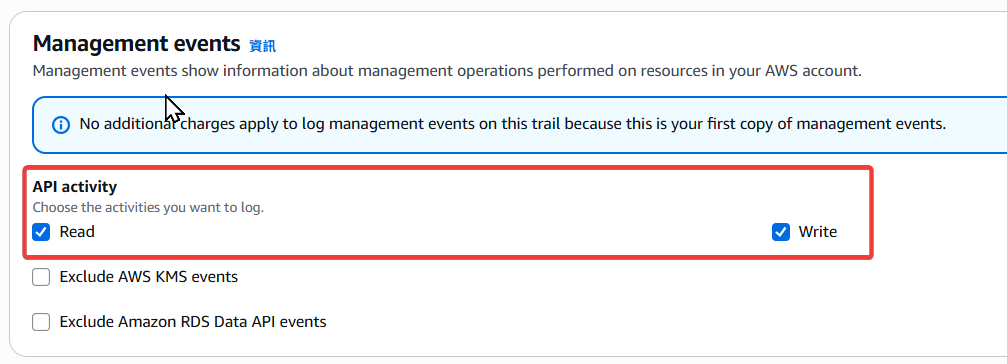
Step4:Management events 設定,選擇 read、write 權限
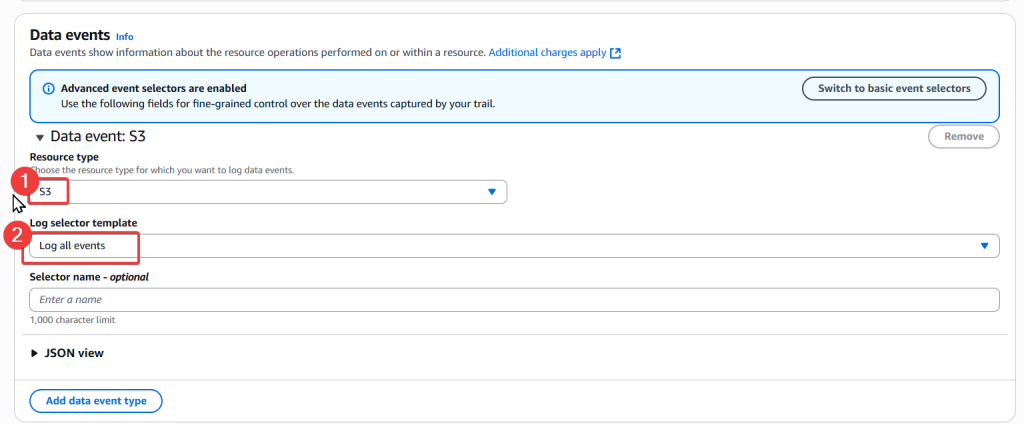
Step5:Data events 設定
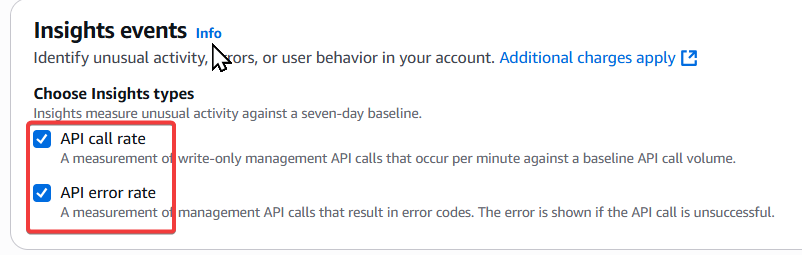
Step6:選擇 Insights 類型
| 類型 | 說明 | 常見應用 | 建議 |
|---|---|---|---|
| API call rate | 偵測「API 呼叫頻率」異常。例如:突然出現大量的 PutObject、DeleteObject、StartJobRun |
監控是否有異常操作暴增 | ✅ 建議開啟 |
| API error rate | 偵測「API 錯誤比例」異常。例如:大量出現 AccessDenied、ThrottlingException |
偵測權限錯誤或程式失敗暴增 | ✅ 建議開啟 |
⚠️ 注意:要啟用 Insights events,至少需勾選其中一項。
若兩者都未選,系統會顯示紅字:「Select at least one Insights type to enable Insights events」。
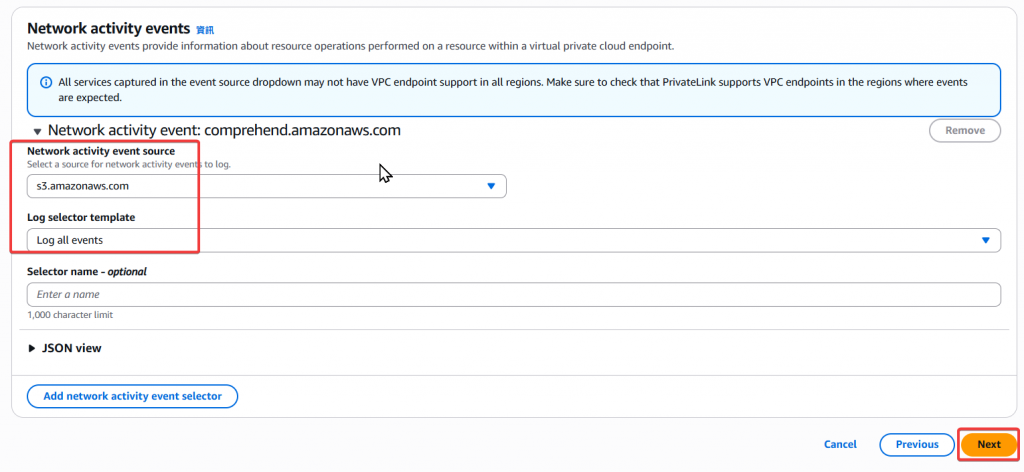
Step7:Network activity events 設定
Step8:確認設定的內容有無錯誤,若無誤就直接點選 Create trail
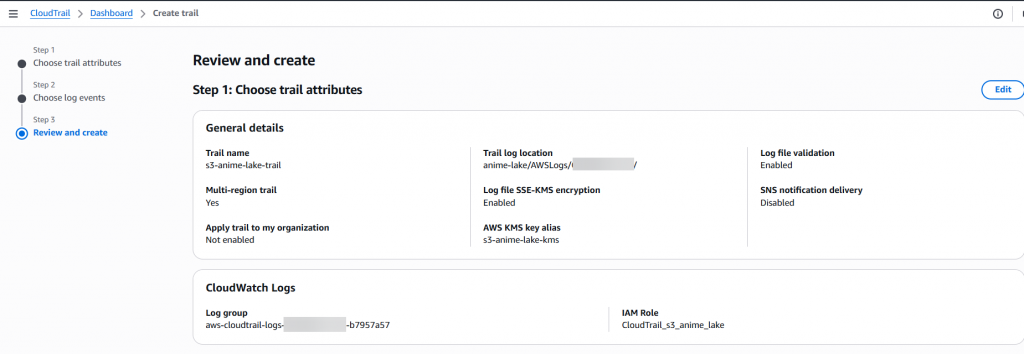
Step9:待頁面跳轉後,即可看到剛剛建立好的 s3-anime-lake-trail
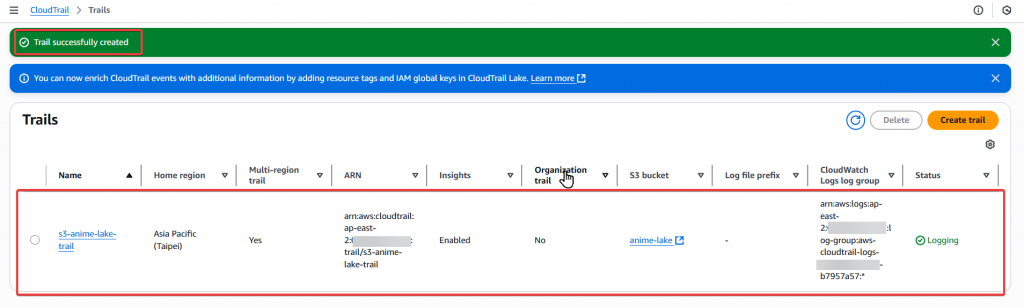
Step10:接著回到 Dashboard 我們可以看到剛剛建置的 s3-anime-lake-trail,以及下方有一些預覽的 Event 狀況
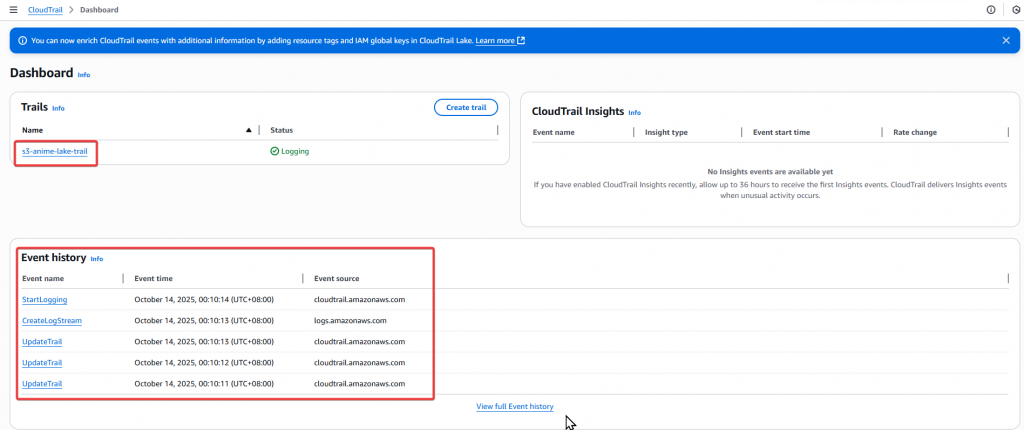
Step11:再來我們至 S3 Bucket 確認有正常建置儲存 CloudTrail 的 Folder
.json.gz 檔案,即代表 CloudTrail 已成功開始寫入 Log。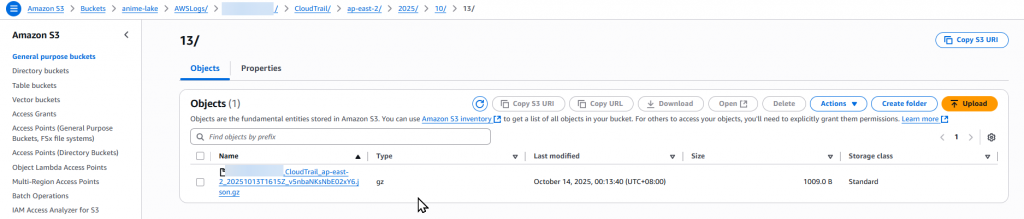
Step12:然後我們在 Event history 驗證事件紀錄
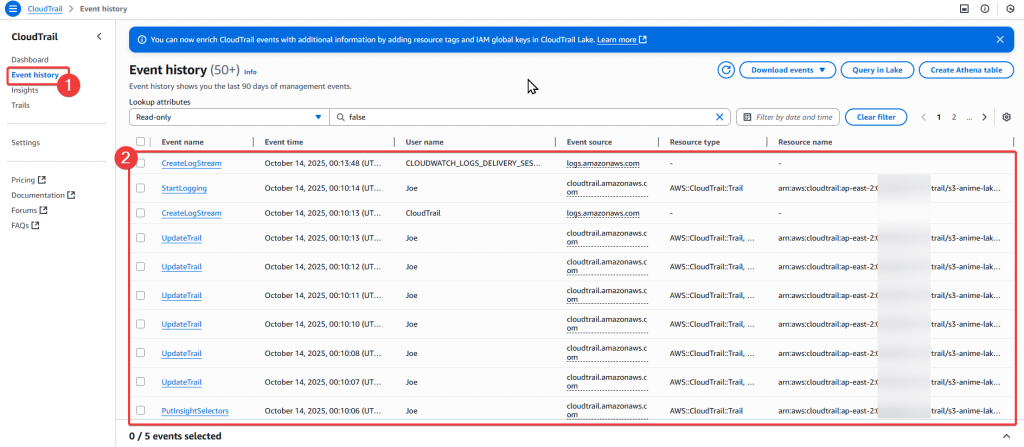
這些紀錄代表 Trail 的設定、啟動、串接 Log Stream 全部正常。
Step13:接著我們實際上傳一個 CSV 檔案到監控的 S3 Bucket 上,來看看會有什麼紀錄追蹤
Andy 做的操作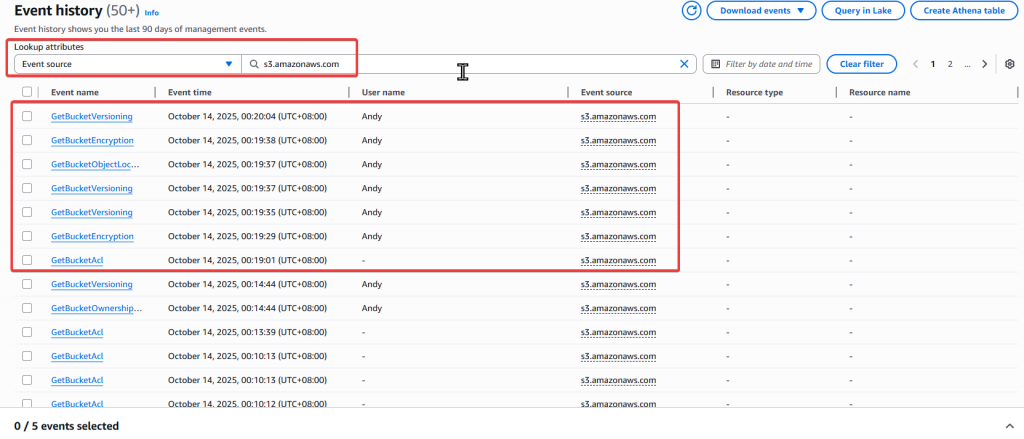
Step14:接我們打開 GetBucketAcl 來看看裡面的內容
GetBucketAcl 相關的 Detail 資訊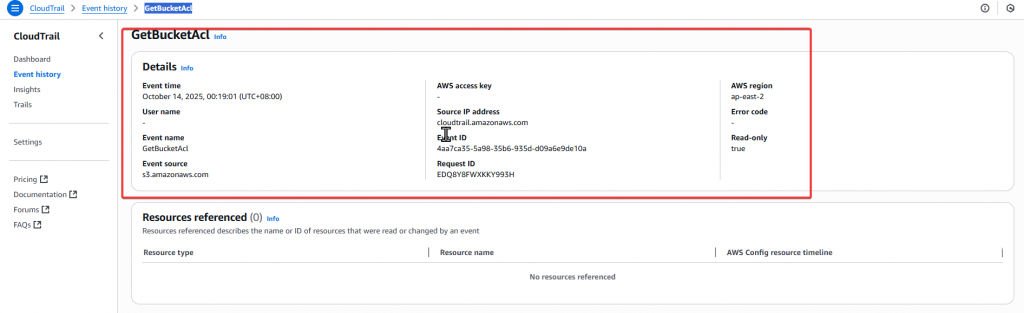
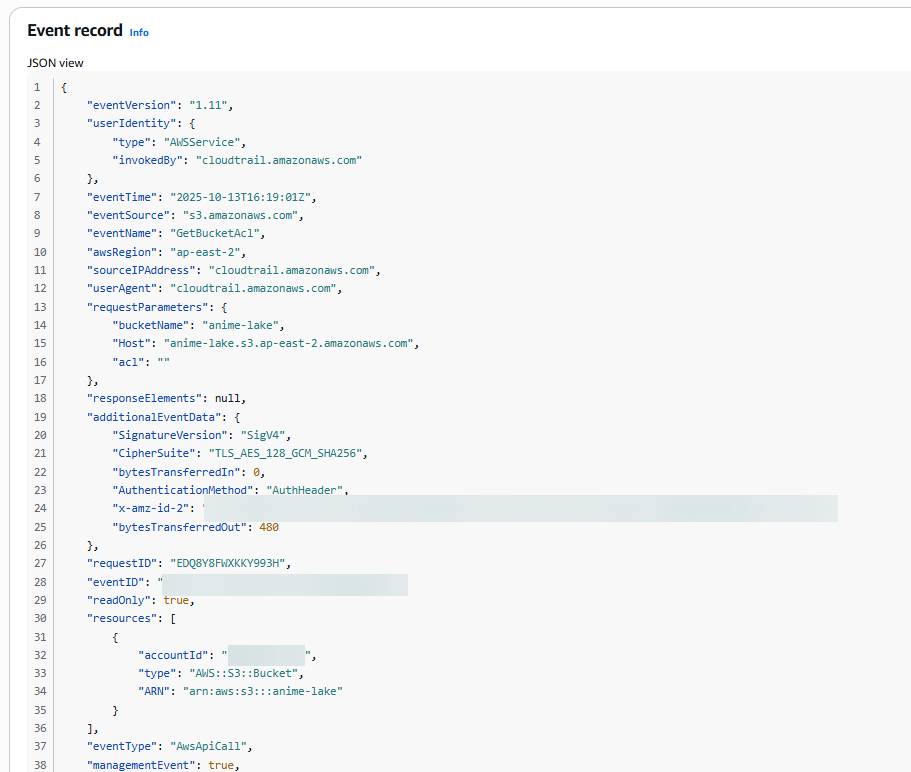
以上即為 CloudTrail 相關的設定流程,可以根據所需的場景,來選擇適當的 Event 做追蹤,同時也有費用的問題,也請納入考量。
透過本篇的實作,我們已經完成了 Data Lakehouse 的監控基礎建設。
| 面向 | 工具 | 監控項目 | 說明 |
|---|---|---|---|
| 系統運作 | CloudWatch | Glue Job 狀態、Lambda Log、警示通知 (SNS) | 快速掌握工作失敗與資源使用情況 |
| 安全稽核 | CloudTrail | S3 上傳 / 刪除、Role 操作、IAM 活動 | 追蹤誰在何時對資源做了什麼 |
| 異常偵測 | CloudTrail Insights | API 呼叫異常、錯誤率上升 | 自動偵測異常行為,強化安全防護 |
| 資料合規 | S3 Data Events | PutObject / DeleteObject | 完整記錄資料層級操作行為 |
🔹 建議做法:
✅ 啟用 CloudWatch Log Group,集中 Glue、Lambda 的運作紀錄。
✅ 為 Glue Job 設定 CloudWatch Alarm(失敗次數 > 0 時發送 SNS 通知)。
✅ 在 CloudTrail 中啟用 S3 Data Events,確保物件層級行為可追蹤。
✅ 搭配 Athena 或 QuickSight 對 CloudTrail Log 進行可視化分析。
✅ 為重要 Trail 設定 S3 Log 儲存桶加密與存取控管。
最終,我們的 Data Lakehouse 不僅能自動化運行,也能自我監控與稽核,成功建置 穩定、透明、可追溯 的雲端數據平台運作環境。
經過前面 29 天的修行,我們從零搭建出符合我們所需的 Data Lakehouse 架構。
在 最後一篇,我們將進行總結:
明天讓我們一起完成這趟「動漫宅的 30 天 AWS Lakehouse 修行日誌」的最後章節!
[1] Amazon CloudWatch Documentation
[2] AWS CloudTrail Documentation
[3] Monitoring AWS Glue
[4] Logging data events for Amazon S3 with AWS CloudTrail


 iThome鐵人賽
iThome鐵人賽