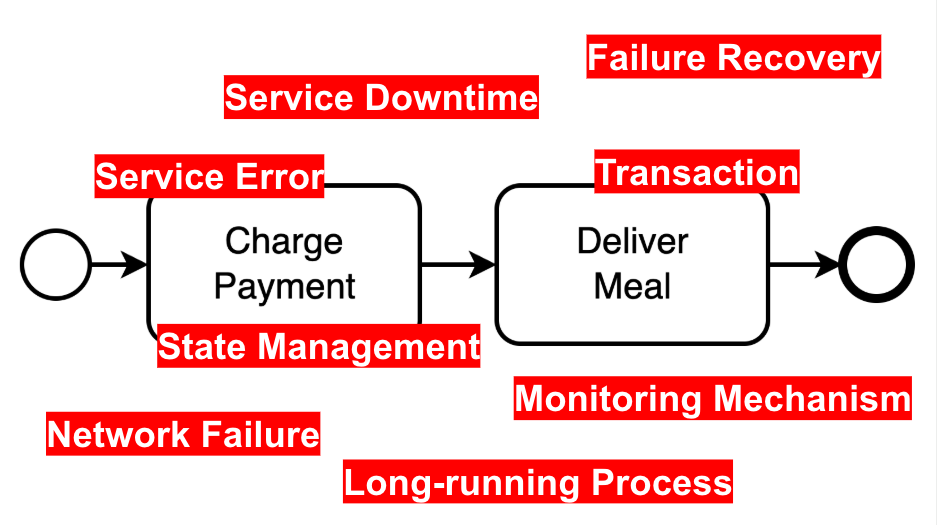
我在實作微服務流程(例如付款→送餐的兩步驟)時,總是反覆碰到相同類型的問題,歸納如下:
現實挑戰
必備能力與配套
複雜度成長
光看這些我自己都 PTSD 了,即使流程簡單到只有兩個步驟,這些重複出現的痛點,促使我想去研究還有什麼可以讓事情變得簡單!
回到最初,為什麼要用到分散式架構呢?一般來說需要用到的情境有以下這些:
每個專案或產品的需求不一定相同,最好先釐清一下目標為何?不同的答案,就會帶出不同的設計與取捨。
以下先介紹三種常見的處理手法 Basic Retry, Job Scheduling, Event Driven Architecture!
排程最讓我挫折的是用來串接流程,不僅在 cron 的設定上傷透腦筋,觸發不即時且有一定的資源浪費;流程程式碼上下文斷裂更令人抓狂。
EDA 最常提倡的是『解耦』,這讓工程師趨之若鶩,殊不知它僅僅是做到時間解耦罷了,又引入了我稱之為文件耦合或者知識耦合的管理問題;並且因為建立了 Message Queue 的基礎設施而增加維運的複雜度,但相關的冪等性及順序性等問題都沒減少!可實際上 EDA 的使用情境其實相對狹窄(如前述)。
前面提到的各種處理方式雖然各有其適用情境,但往往也容易被誤用。
相比之下,我認為流程引擎的應用範圍更廣,能提供更完整的解決方案。雖然一開始的學習曲線偏高,但長期維護成本會趨於穩定,開發者的心智負擔也不會隨著系統複雜度而急速上升。更重要的是,流程引擎在多數分散式需求上都能對應處理。
因此,下一篇我們就來討論流程引擎吧!
版主這篇文章真是實務經驗的結晶,讀完後讓人心有戚戚焉!您歸納的微服務痛點,從連線瞬斷到分散式交易的挑戰,句句都直戳工程師心坎。特別是您對 Job Scheduling 和 EDA 的『隱性編排』與『文件耦合』的精闢分析,讓我對這兩種架構的適用情境有了更深刻的理解。好奇版主在不斷探索後,是否有找到什麼能真正讓微服務長流程變『簡單』的魔法呢?期待您的後續分享!
也歡迎版主有空參考我的系列文「南桃AI重生記」:
https://ithelp.ithome.com.tw/users/20046160/ironman/8311
後續有更多觀念介紹喔!


 iThome鐵人賽
iThome鐵人賽