光靠「單一模態」,常常不足以判斷一個人的真實情緒。
在情感偵測中,光靠「單一模態」往往會失真:表情可能在笑,聲音卻流露出怒意。這也是為什麼需要「多模態學習(Multimodal Learning)」——讓 AI 同時結合臉部表情與語音特徵,更接近人類的判斷方式。
大家應該都有過這樣的體驗:
看一個人臉上的表情,覺得他在笑,但聽聲音卻發現語氣中帶著生氣?
光靠「單一模態」常常不足以判斷一個人的真實情緒。
這就是為什麼我們需要 多模態學習(Multimodal Learning)。
它能同時整合 視覺、聽覺、文字 等多種訊號,讓 AI 更聰明、更接近人類的感知能力。
在這篇文章,我們聚焦在一個經典且實用的策略:Late Fusion(後期融合),並探討它如何應用在情感偵測。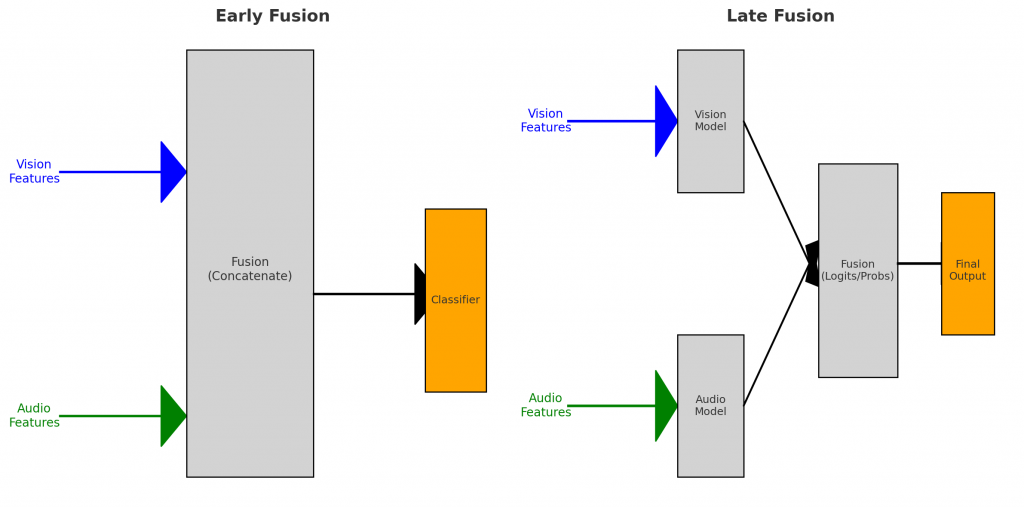
圖示:Early Fusion vs Late Fusion 在多模態情感偵測中的對照。Early Fusion 早期把特徵合併,Late Fusion 則保留各模態獨立,最後在決策層融合。
一、什麼是 Late Fusion?
Late Fusion 的核心概念:
每個模態先各自訓練好模型,最後再把輸出的結果(例如 logits 或機率分布)融合在一起,做最終判斷。
例如在表情分析中,視覺模型判斷他在笑,聲音模型卻判斷有怒意,Late Fusion能把兩邊的訊息權衡,輸出一個更可靠的情緒分類結果。
👉 你可以想像:
視覺模型:看臉 → 輸出「開心 80%」
聲音模型:聽聲音 → 輸出「生氣 70%」
融合層(Fusion Head):綜合兩邊的分數 → 得出最合理的情緒結論
流程大概長這樣:
Image → Vision Encoder → logits_v ┐
├─ Fusion → Final Output
Audio → Audio Encoder → logits_a ┘
二、和 Early Fusion 有什麼不同?
🔹 Early Fusion(早期融合)
在 特徵層 就把影像和聲音合併,丟進同一個模型。
模型直接學習跨模態的整體表示。
缺點:需要對齊時間軸與維度,且模態之間容易「互相干擾」。
🔹 Late Fusion(後期融合)
各模態獨立運作,最後在 決策層 才融合。
優點:模組化高、彈性好,視覺或聲音模型壞掉也能獨立替換。
舉例來說:
Early Fusion = 兩個人從頭到尾一起寫作業(合作緊密但容易吵架)
Late Fusion = 兩個人各自完成,再討論出最後答案(更彈性)
Early Fusion
把 視覺特徵 (Vision Features) 和 音訊特徵 (Audio Features) 在一開始就融合 (Concatenate)。
融合後的整合特徵丟進 單一分類器 (Classifier) 做判斷。
特點:模型直接學「跨模態的整體表示」,但需要對齊時間軸與維度。
Late Fusion
視覺與音訊各自先經過自己的模型 (Vision Model / Audio Model),分別產生各自的預測 (logits/probs)。
再把這些輸出融合 (例如平均、加權、投票)。
最後交給一個 融合層/最終分類器 (Final Output)。
**特點:保留各模態獨立性,融合時更彈性,常用於多來源決策。
三、實作範例:Vision + Audio
我們用 PyTorch 寫一個簡單的 Late Fusion demo。
1. 定義 Encoder
import torch
import torch.nn as nn
class VisionEncoder(nn.Module):
def __init__(self, in_dim=512, hidden=256, num_classes=7):
super().__init__()
self.mlp = nn.Sequential(
nn.Linear(in_dim, hidden),
nn.ReLU(),
nn.Linear(hidden, num_classes)
)
def forward(self, x):
return self.mlp(x)
class AudioEncoder(nn.Module):
def __init__(self, in_dim=128, hidden=128, num_classes=7):
super().__init__()
self.mlp = nn.Sequential(
nn.Linear(in_dim, hidden),
nn.ReLU(),
nn.Linear(hidden, num_classes)
)
def forward(self, x):
return self.mlp(x)
2. Late Fusion
class LateFusion(nn.Module):
def __init__(self, num_classes=7):
super().__init__()
self.vision = VisionEncoder()
self.audio = AudioEncoder()
# 最後再融合
self.fusion_head = nn.Linear(num_classes*2, num_classes)
def forward(self, vision_feats, audio_feats):
logits_v = self.vision(vision_feats)
logits_a = self.audio(audio_feats)
fused = torch.cat([logits_v, logits_a], dim=-1)
return self.fusion_head(fused)
3. 測試
vision_feats = torch.randn(4, 512) # batch=4, 視覺特徵
audio_feats = torch.randn(4, 128) # batch=4, 聲音特徵
model = LateFusion(num_classes=7)
output = model(vision_feats, audio_feats)
print(output.shape) # torch.Size([4, 7])
四、Late Fusion 的好處
模組化:影像模型與聲音模型互不干擾,方便替換或升級。
彈性:可以根據場景選擇不同的融合方式(加權平均、投票、concatenation)。
穩定性:若某一個模態缺失(例:只有聲音),也能單獨運作。
五、延伸應用
多模態情緒辨識:臉部表情 + 聲音語調。
醫療:MRI 影像 + 病患聲音描述。
自駕車:攝影機影像 + 雷達數據。
結語
Late Fusion 就像一場「多模態小組合作」
大家各自把專業做到最好,最後再融合出更完整的答案。
這種方法雖然簡單,但實際應用廣泛,尤其在 表情分析、情緒偵測、醫療輔助 等領域都有很大價值。
如果你是剛接觸多模態學習的新手,Late Fusion 會是最好的起點 。
在 AI 情感偵測的應用裡,Late Fusion 就像一場多模態的討論會——影像、聲音各自表達意見,再由系統融合出最接近真實的答案。它雖然簡單,但在表情分析、情緒偵測、醫療照護等場景,卻能帶來非常實用的價值。
 abc11032203
abc11032203
