在進入 RAG(Retrieval-Augmented Generation,檢索增強生成)的世界前,讓我們先思考一個核心問題:為什麼大型語言模型(LLM)有時會「自信滿滿地答錯」?這種現象,我們稱之為**「幻覺(hallucination)」**。它的根本原因在於,LLM 的知識主要來自於訓練時的資料,缺乏即時更新或存取特定領域資訊的能力。
RAG 的誕生,正是為了解決這個限制。它巧妙地結合了資訊檢索與生成式 AI 的優點,讓生成模型在回答問題前,能先從外部知識庫中檢索相關資料,再據此給出更準確的回應。本篇文章將帶你深入了解 RAG 的兩個核心靈魂——Retriever 與 Generator,以及它們如何協同合作,打造一個高效的問答系統。
眾所周知,LLM 的知識是靜態的,無法即時更新,這使得它在處理需要最新或特定知識的任務時顯得力不從心。RAG 透過一個聰明的架構來解決這個問題:當使用者提問時,系統會先檢索你的專屬文件庫,找出所有相關的內容,然後再將這些內容作為上下文,提供給 LLM 來生成回答。
簡單來說,RAG 讓 LLM 從一個「只靠記憶」的學生,變成一個「懂得找參考資料」的學術專家,這不僅能確保答案的準確性,更能有效降低「幻覺」的發生。
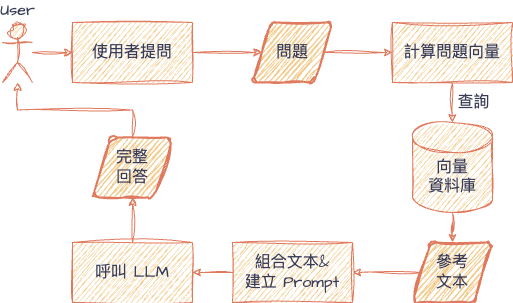
要打造一個強大的 RAG 系統,我們需要兩大核心組件完美配合:
Retriever 的任務,就像是 RAG 系統中的**「獵人」。它根據使用者的問題,從龐大的知識庫中快速找出最相關的內容片段**。
Generator 則是 RAG 系統中的**「大廚」,通常由一個大型語言模型(LLM)擔任,如 GPT-4、LLaMA、Claude 等。它的任務是「烹調」**Retriever 找到的素材。
RAG 系統的運作流程,就是這兩個核心組件的接力賽:
即使是如此強大的 RAG,在實作上仍有許多挑戰:
為了解決這些問題,開發者會採用精準的 Prompt 設計、加入 Chain of Thought(CoT)推理,或是使用更先進的 RAG 架構來持續優化系統。
RAG 系統的效能,取決於 Retriever 找到的資料品質,以及 Generator 融合資訊與生成答案的能力。理解這兩個核心組件的角色與運作方式,是掌握 RAG 技術的關鍵。
RAG 系統的效能,取決於 Retriever 找到的資料品質,以及 Generator 融合資訊與生成答案的能力。然而,這一切的前提是,我們的原始資料必須是可讀、可被有效檢索的。對於掃描文件、圖片或是複雜版面的 PDF,若沒有先將其轉換成清晰、可供機器處理的文字,再強大的 Retriever 與 Generator 也無濟於事。這也正是我們在 Day01 提到的 OCR 的價值所在。
在下一篇文章中,我們將深入探討 OCR 的基本概念,並介紹在 Python 中常用的 OCR 套件,為我們後續的實作打下堅實的基礎。

