接下來我們要進到資料庫與後端開發階段,目標是先讓前端能打API到後端儲存資料到資料庫。
記得我們的畫面長這樣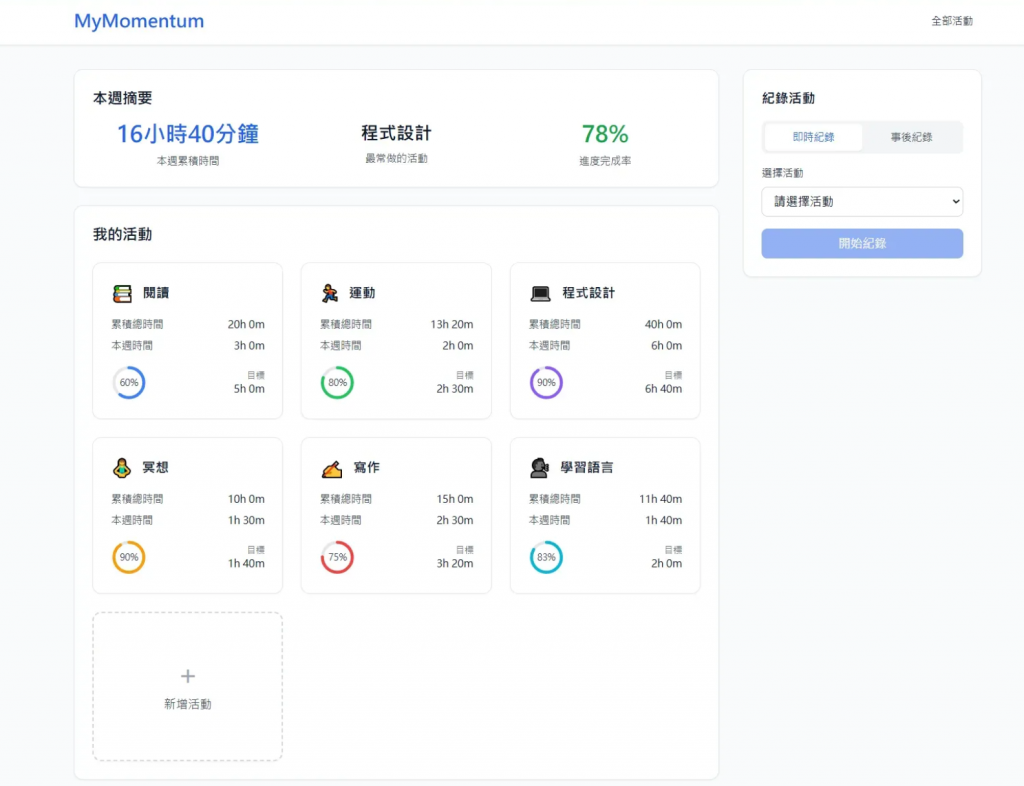
從畫面出發整理出一些跟資料表有關的重點:
因為現在內容還不是很多,先以上面這些重點為基礎去設計資料表結構,後續還會需要users表來記錄使用者,不過目前先這樣。
打算設計兩張資料表:
activity_records:紀錄每次使用者進行的活動內容(例如:今天晚上冥想 20 分鐘)activities:儲存使用者自定義的活動清單(例如:閱讀、運動、冥想)設計欄位過程關注幾項原則:
簡單、穩定、易於查詢,資料能夠用來產出圖表。
activities — 活動定義表| 欄位名稱 | 型別 | 必填 | 說明 |
|---|---|---|---|
| id | UUID | ✅ | 主鍵,使用 gen_random_uuid() 產生 |
| user_id | BIGINT | ✅ | 對應 users.id,代表此活動屬於哪個使用者 |
| name | VARCHAR | ✅ | 活動名稱,例如「閱讀」、「運動」 |
| target_time | INTEGER | ✅ | 每週目標時間(單位:分鐘) |
| color | VARCHAR | ❌ | 活動顯示顏色(UI 用) |
| icon | VARCHAR | ❌ | 活動顯示圖示(UI 用) |
| created_at | TIMESTAMPTZ | ✅ | 活動建立時間,預設 now |
| updated_at | TIMESTAMPTZ | ✅ | 活動更新時間,預設now |
每名使用者都可以自訂自己的活動清單,例如小明會建立「散步」、「煮飯」或「閱讀」等活動。
(其實user_id 不用到bigint那麼大,但自己的專案,假裝一下真的需要這麼大)
activity_records — 活動紀錄表| 欄位名稱 | 型別 | 必填 | 說明 |
|---|---|---|---|
id |
UUID | ✅ | 主鍵,使用 gen_random_uuid() 產生 |
user_id |
BIGINT | ✅ | 對應 users.id,代表紀錄屬於哪個使用者 |
activity_id |
UUID | ✅ | 對應 activities.id,紀錄屬於哪個活動 |
executed_at |
TIMESTAMPTZ | ✅ | 活動實際發生時間,精確到秒 |
duration |
INTEGER | ❌ | 活動持續時間(單位:秒),LIVE 紀錄進行中時可為 NULL |
created_at |
TIMESTAMPTZ | ✅ | 系統寫入此筆紀錄的時間,預設 now |
source |
ENUM('LIVE','MANUAL') | ✅ | 紀錄方式:即時(LIVE)或手動(MANUAL) |
| updated_at | TIMESTAMPTZ | ✅ | 系統更新此筆紀錄的時間,預設 now |
整個系統的核心資料表,每當使用者完成一項活動,系統就要新增一筆紀錄。包含:
完成了 但是好像哪裡怪怪的。
直覺地去想,activities 這張表會有一個”總累積時間"欄位,但如果真的這樣設計會有問題
activity_records 每次有新增/修改/刪除,這個總累積時間就必須更新,這些針對累積時間的邏輯分散在程式碼的不同地方、會增加潛在的維護難度,後續不管是開發新功能還是除錯都會需要考慮到這個"總累積時間” 用想的就麻煩。
2 無法維持各種統計資料的彈性
針對活動時間,我們將會有各種產出的圖表、統計報告,這當中高機率有很多是跟”總累積時間”無關的統計,例如:本週累積時間、本日累積時間。
所以除非真的遇到效能瓶頸,目前打算用計算的方式去計算各式各樣的累積時間。
那麼就照著上面的規劃來產生DDL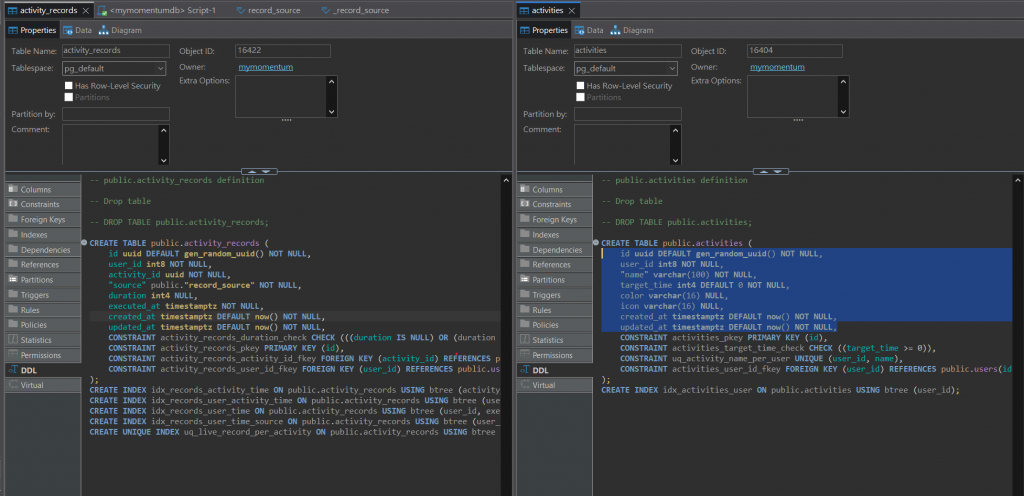
這邊比較要注意的是這兩行需要先執行:
-- 建立 UUID 函數用的 extension(如尚未啟用)
CREATE EXTENSION IF NOT EXISTS "pgcrypto";
-- 建立 ENUM 型別 for source 欄位
CREATE TYPE record_source AS ENUM ('LIVE', 'MANUAL');
沒有啦,因為GPT說ENUM比起儲存文字較有效率,而且我也覺得比起存字串、ENUM比較不會出錯。
(聽朋友說有坑!? 遇到再說)
執行完成後,下一步要開始進入後端開發
我們要來把資料庫跟後端串起來,再試著透過前端call API 到後端來儲存資料。

