語言模型會將單詞依據詞意、關聯性、頻率轉換成數字特徵的形式,這種轉換方式有分三種,一種是傳統機器學習使用的方式,使用規則與統計做one-hot編碼方式,又稱關鍵字檢索。一種是基於神經網路的詞嵌入(Embedding)方式,將詞句轉換成向量,又稱向量檢索。又有一種是結合了前面兩種再加上Rerank的混合式檢索。今天會說明傳統的one-hot編碼方式。明天再講詞嵌入方式。
將資料集中出現過的所有詞彙一一記錄,生成一張詞彙與出現數量對應的陣列,在目前文章有出線的詞彙就紀錄為1,沒有出現過就記錄為0。缺點是無法描述詞意關聯性,還會讓陣列資料過多空值,降低檢索效率。
會統計目前文章出現過的每個單詞的出現次數,出現次數越多代表越重要,但無法代表詞意和語序。
TF-IDF是一個基於BOW衍伸的技術,常用於資料檢索。延伸又有更精確的BM25。
TF(詞頻)指的是某個詞在特定文件裡出現的次數。如果某個字像英文的“the”、“a”、"is"或中文的「的」、「吧」這類常用字,在文章裡出現非常多次,但通常資訊價值較低,所以它的TF雖高、但重要性不大。
IDF(逆文件詞頻)則是衡量一個詞在所有文件中出現的稀有程度。如果某個字經常在某份文件出現,但很少出現在其他文件,這代表該詞對那份文章有特殊意義,應被加上較高的權重;反過來,如果某個詞在多數文章裡都很常見,它的代表性就會降低,權重也要相應減少。
BM25是強化版的TF-IDF,常被搜尋引擎像Elasticsearch採用。特別之處在於它的公式可以根據不同需求調整,像參數 k1 和 b 就能讓每個人選擇適合自己場景的排名方式。
在BM25裡,IDF(逆文件詞頻)的運算和TF-IDF很接近,不過對於極其罕見的詞有點平滑,讓不同詞之間差距不會太大。TF(詞頻)部分則有「邊際效應」──同一個詞在文章出現越多次,雖然分數會增加,但提升效果會慢慢趨緩、不會無限線性拉高。這也能避免有人故意重複關鍵字來灌分。
BM25的參數k1可以調整關鍵字出現次數的影響程度,k1越大,分數提升就越明顯;b則用來調整文章長度對分數的作用,b越小,長文章帶來的影響越低。根據不同的資料型態,像書籍、網頁或商品標題,可以調整不同的參數來達到最佳搜尋效果。
控制詞頻 (TF, term frequency) 增加時,分數上升的速度與「飽和」的程度。
k1 越大 → 關鍵字多次出現仍然能提升分數(不容易飽和)。
k1 越小 → 出現幾次就差不多封頂,後面再多也不會有什麼加分。
控制文件長度對分數的影響。
b 越大(接近 1) → 長文件要出現更多次關鍵字才算「重要」,長度影響大。
b 越小(接近 0) → 幾乎不考慮文件長度,短或長的文章影響差不多。
(最紮實的數學呈現可見此連結~ 推推!!)[^3]
🔍 對應 BM25:這就是 k1 調小 → 讓詞頻快速飽和,多次出現不會持續加分。
✅ 判斷:正確。因為廣告頁常見 keyword stuffing,如果不降低敏感度,系統會誤以為這些詞很重要。
⚠️ 質疑點:但要注意,「調低 k1」只能減少 spam 的效果,卻不能完全解決廣告亂塞詞的問題,這通常還需要 其他 anti-spam 機制(例如 TF-IDF 權重、正規化特徵、甚至手動過濾)。
🔍 對應 BM25:這句話牽涉到兩個面向:
關鍵字次數多但比例低 → 如果你只想讓「總出現次數」更有影響力,應該是 k1 調高。
篇幅太長造成被懲罰 → 這是 b 的問題(因為 b 越大,長文件越被「壓低」分數)。
⚖️ 判斷:部分正確,但不完整。
你說「調高對關鍵字的敏感度」→ 如果你指的是 k1 ↑,那是合理的。
但在長篇論文情境下,還要同時考慮 b ↓,因為否則長度懲罰太重,會讓長文件吃虧。
⚠️ 質疑點:
光靠 k1 ↑ 可能仍不足,因為詞頻密度低會被 b 抑制。
所以更準確的做法應該是:論文場景 → k1 ↑、b ↓,讓重複詞仍能發揮作用,同時避免長度懲罰過度。
總體來說,BM25只是眾多決定搜尋結果的工具之一,雖然本身也有斷詞、詞序、語意等限制,無法完全解決所有複雜問題,但因為實用又彈性,被廣泛運用到傳統搜尋和現代RAG等混合搜尋系統裡。
在面對不同類型的文件精準重要關鍵字出現的頻率也會不一樣,例如在廣告網頁上,重點關鍵字可能會出現很多次,我們可以調低對關鍵字的敏感度,讓他不那麼影響判讀。在論文中,因為篇幅較長,一些關鍵字出現次數多但頻率相對不高,我們要調高他對關鍵字的敏感度,才能抓到重點。
TF-IDF、BM25 這些只是單純的統計計算,會有斷詞不精確的問題、詞序問題、還有語意錯誤識別等問題。
斷詞問題:像「哈利波特」這個詞,到底應該被當成單獨的詞,還是分成「哈」、「利」、「波」和「特」四個字?
詞序問題:TF-IDF等統計方式只會計算一個詞出現的次數,不會考慮出現的順序。例如搜尋「我好愛吃糖果」,如果一篇文章裡這六個字連在一起,另一篇則是「我知道你好愛吃糖果」,雖然兩篇出現次數一樣,但顯然前一篇相關性更高,TF-IDF 卻分不出來。
語意問題:像是「哈利波特風格的小說」這句話,雖然出現了「哈利波特」,但內容和原本查詢的意思可能差很多,TF-IDF 看不懂背後的語意。
因此,這些統計方式適合作為一個基礎的評估指標,但不足以解決所有與詞義或關聯性有關的複雜問題,需要跟分詞器結合。^1^2
實作目標: 建立帶情緒標籤的BM25檢索系統
延續昨天程式:直接使用昨日實作的CSVEmotionAnalyzer類別和訓練好的模型
靈活的數據載入:可以從CSV檔案或已訓練的pkl模型載入
情緒增強檢索:結合BM25和情緒分析的優勢
參數可調整:支援不同場景的BM25參數調整
豐富的分析功能:提供詳細的檢索分析和情緒趨勢分析
這個系統結合了傳統統計方法(BM25)與現代機器學習(情緒分析),並且我們可以根據實際需求進一步調整和擴展功能。
(1)評論資料集(同昨天文章內資料集)
1. 評論資料集特性:
文檔較短且長度一致,情緒類別集中。報告提供了針對這些特性的 BM25 參數調整建議。同時,提供三種不同參數組合的效果可做實測,以優化 BM25 檢索系統的性能。
屬於「同質長度資料集」或「短文檔資料集」,可以嘗試在這些建議範圍內調整 k1 和 b,並根據檢索結果進一步微調。
2. 參數調整建議:
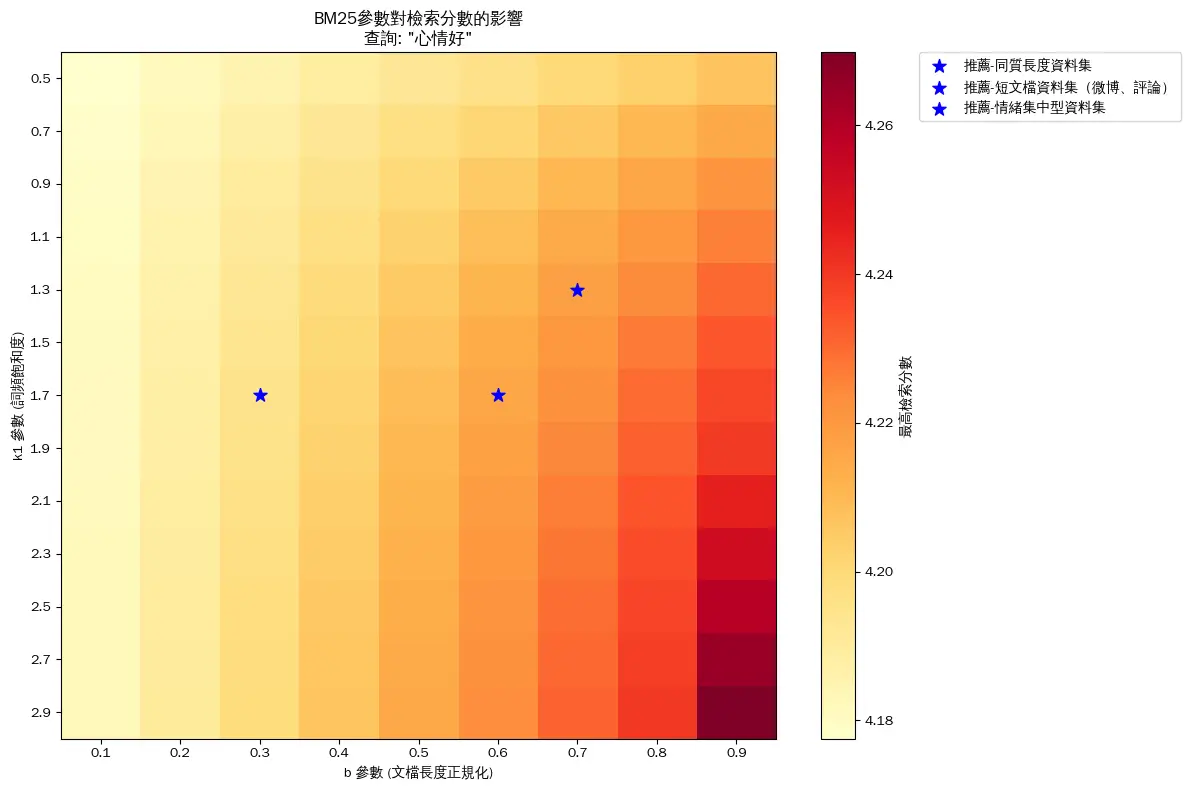
(2)論文資料集和廣告口號資料集(在程式碼中)
論文資料檢索結果圖塊不理想原因:
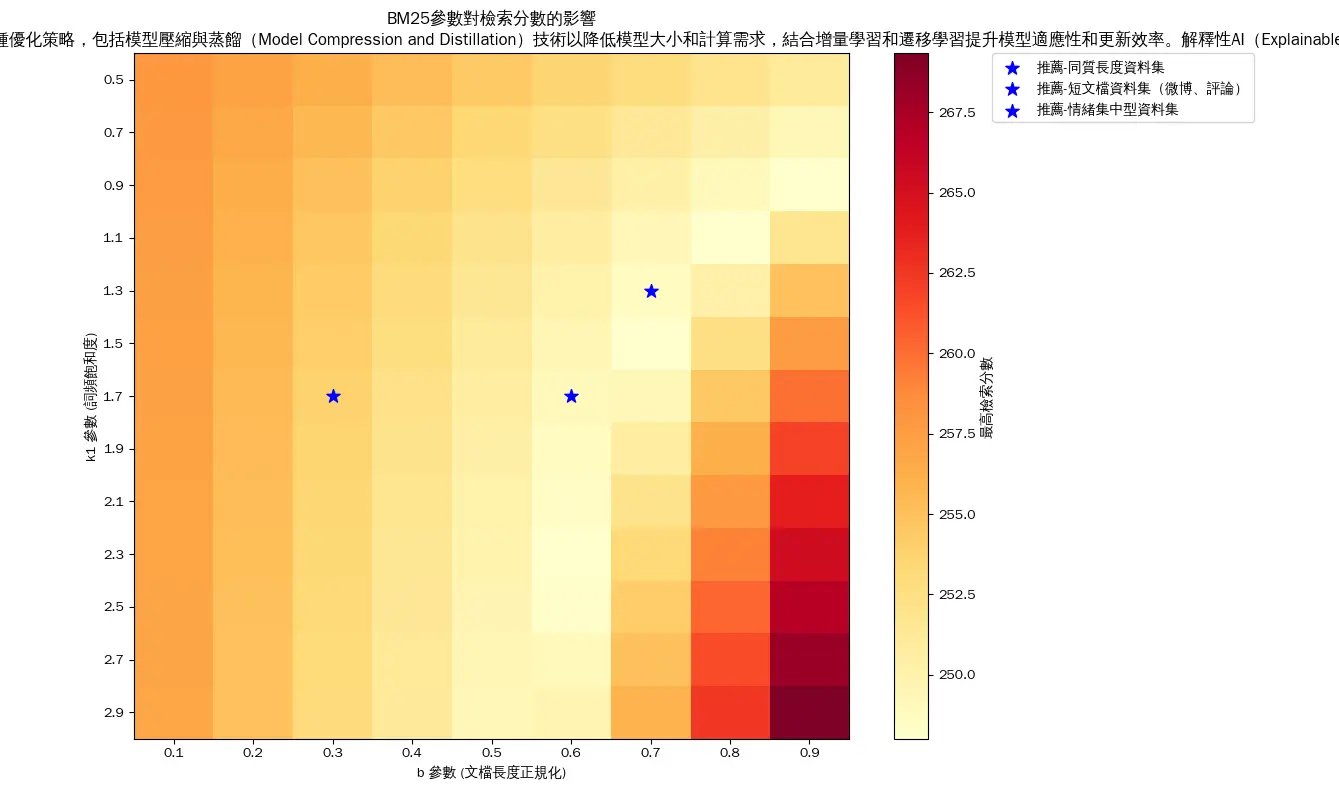


 iThome鐵人賽
iThome鐵人賽