向量檢索是現代RAG系統的核心技術之一。簡單來說,就是將文本轉換為高維向量表示,然後透過計算向量之間的相似度來找到最相關的文檔。
傳統的關鍵字檢索(如BM25)依賴精確的詞匯匹配,但向量檢索能理解語義相似性。比如說,當你搜索「快樂」時,它也能找到包含「開心」、「愉悅」等相近含義的文檔。
文檔編碼:使用預訓練模型將文檔轉為向量
查詢編碼:將用戶查詢也轉為向量
相似度計算:計算查詢向量與文檔向量的相似度(通常使用餘弦相似度)
結果排序:按相似度分數排序並返回最相關的文檔
根據文檔內容,主要的向量檢索工具包括:
1. ChromaDB
輕量級的向量數據庫,非常適合原型開發
支持多種相似度計算方法(cosine、euclidean等)
內建元數據過濾功能
2. SentenceTransformer
專門用於生成高質量中文語義向量
文檔中使用了 shibing624/text2vec-base-chinese 模型
能夠很好地處理中文語義理解
3. 其他常見工具
雖然文檔中主要使用ChromaDB,但業界還有其他優秀的向量檢索工具:
Faiss:Facebook開發的高性能向量檢索庫
Pinecone:雲端向量數據庫服務
Weaviate:開源的向量搜索引擎
Milvus:專為AI應用設計的向量數據庫,最專業的向量檢索工具,適合企業引入。
實作目標:實作情緒感知的向量檢索,使用ChromaDB開源版+SentenceTransformer,這個免費的強強組合不須任何規費
核心分工:各司其職的完美配合
SentenceTransformer:語義編碼專家
專長:將文本轉換為高質量向量表示
語義理解能力強:特別是 shibing624/text2vec-base-chinese 對中文語義的理解
模型選擇豐富:支援100多種語言的預訓練模型
編碼一致性:同一個模型確保查詢和文檔在同一向量空間
ChromaDB:向量存儲與檢索專家
專長:高效的向量存儲、索引和相似度搜索
向量數據庫功能:專為向量檢索優化的存儲引擎
多重檢索能力:支援向量搜索、全文搜索、元數據過濾
相似度計算:內建餘弦相似度等多種距離計算方法
"心情不錯"的距離都在0.3多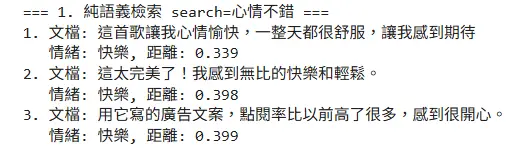
"生氣"的距離都在0.45多
"厭惡"的距離都在0.41多
將文字轉換成向量座標0-1之間的一維表示法。
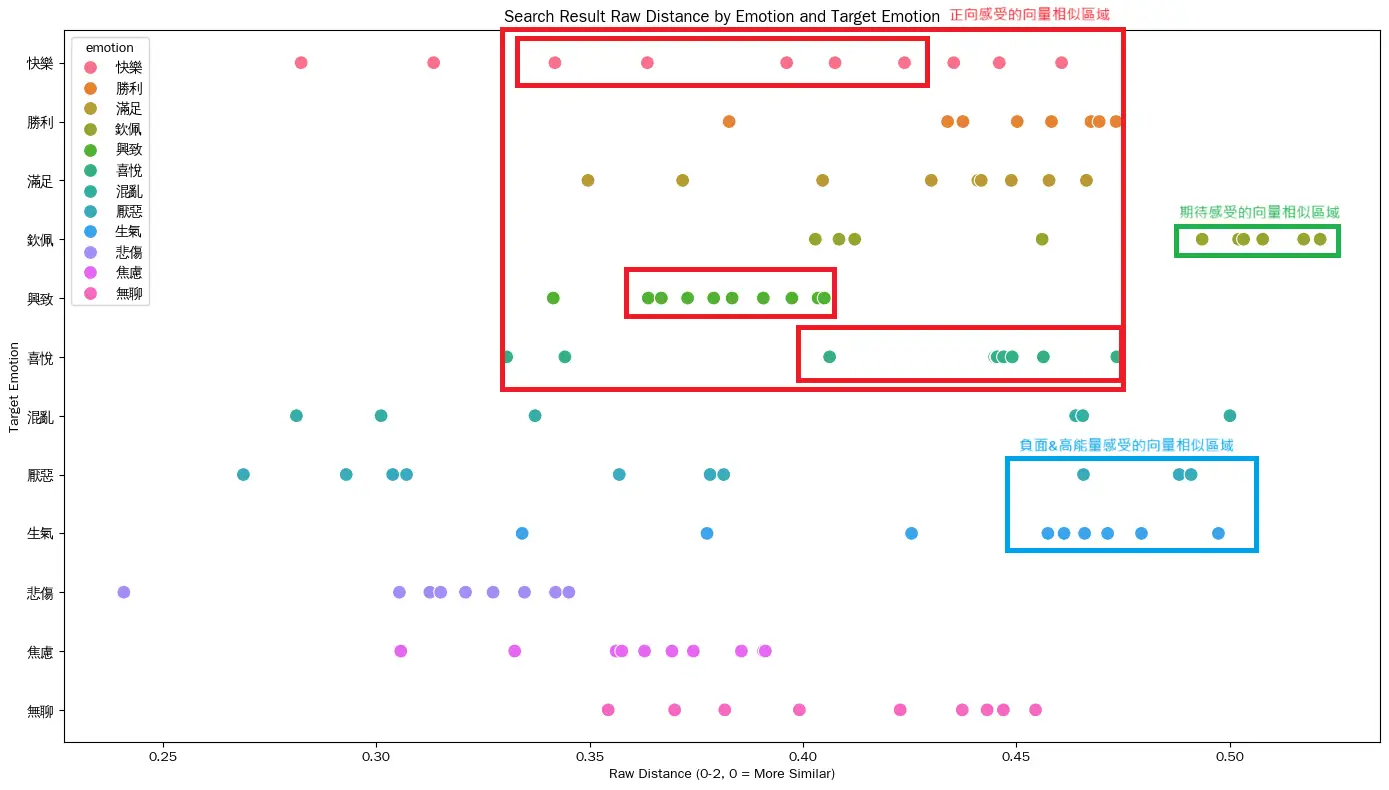
圖表顯示了一個很重要的現象:即使設定目標情緒過濾,仍會檢索到其他情緒的文檔。
比如"悲傷"目標情緒下出現了"焦慮"的點,這反映了:
同類情緒點呈現明顯的聚類趨勢
為了更好地視覺化相似度,我們將 ChromaDB 返回的原始距離(通常在 0 到 2 之間,距離越小越相似)轉換為一個 0 到 1 的 scaled_position 尺標。
scaled_position 的計算公式為 (2 - distance) / 2。這使得值越接近 1 表示相似度越高,點在圖表上越靠右。
這說明SentenceTransformer在情緒語義空間的表示是有效的,同類情緒文本在向量空間中確實聚集在一起!
大多數點集中在0.75-0.87的中等相似度區間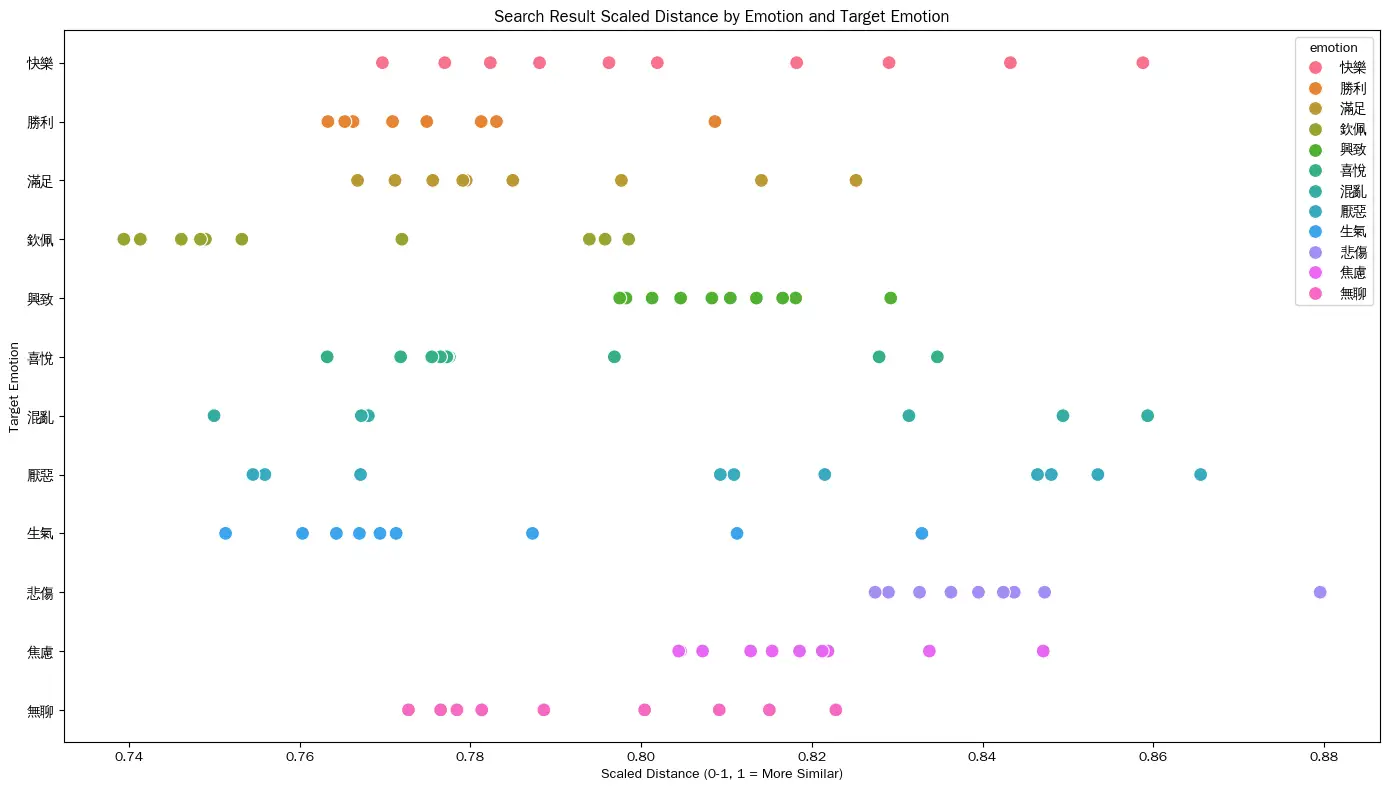
實作放在colab


 iThome鐵人賽
iThome鐵人賽