「早安,大師。」洛基坐下後說,「昨天您提到了 update-item,說它能解決 put-item 在部分更新時的問題。我一直在想,在真實的星際活動報名中,可能有上萬人同時操作...」
洛基對於這個功能相當在意,畢竟 SQL 的世界他已經遠離了一些,但是 DynamoDB 又好像還沒跨進去。今天的 update-item 又會開啟它哪些新的視野呢?
「如果說 Put 是重新粉刷整面牆,那 Update 就是在牆上精準地掛一幅畫。你只改變你想改的,其他保持不變。而且,它能做到一些 Put 永遠做不到的事情——原子性操作。」大師今天氣定神閒地開始他今天的話題。
「原子性操作?聽起來非常的玄。」
「接著聽下去就不玄了,而且我說,它非常的優雅呢。」大師呵呵笑著。
「讓我們從昨天的例子繼續。」大師說,「記得那個火星防禦研討會嗎?讓我們用 update-item 來更新報名人數。」
洛基查看了昨天的資料,確認 registered 目前是 1。
「首先,最基本的 update 操作,Hippo 幫我們更新一下人數」大師喚起了 Hippo,Hippo 也馬上在螢幕上顯示出指令。
aws dynamodb update-item \
--table-name IntergalacticEvents \
--key '{"PK": {"S": "EVENT#MARS-SY209"}}' \
--update-expression "SET registered = :val" \
--expression-attribute-values '{":val": {"N": "2"}}' \
--endpoint-url http://localhost:8000
洛基注意到:「Hippo 只指定了要更新的 registered,沒有提供其他欄位的資料。」
「正是如此。」大師說,「現在查詢這筆資料看看。」
洛基執行 get-item,發現所有其他欄位都還在:name、date、capacity、location、speaker、topic、duration、status——一個都沒少,只有 registered 變成了 2。
「看到差異了嗎?」大師問。
洛基:「使用 update-item 只要告訴它我要改什麼!不需要先讀取,不需要管理整個 item 結構,更不會意外覆蓋其他欄位。這樣就方便很多,比較像是我們平常對於更新資料的認知。」
大師點頭,「但這只是開始。Update 真正的威力在於它的原子性操作。」
「讓我們先看看 Update 最基本的原子操作。」大師在白板上寫下 UpdateExpression 的四個動作:
SET - 設定屬性值
ADD - 數值增減(原子計數器)
REMOVE - 移除屬性
DELETE - 從集合中刪除元素
「我們來試試 ADD 操作。」大師說,「假設現在有三個人同時報名。」
# 第一個人報名
aws dynamodb update-item \
--table-name IntergalacticEvents \
--key '{"PK": {"S": "EVENT#MARS-SY209"}}' \
--update-expression "ADD registered :inc" \
--expression-attribute-values '{":inc": {"N": "1"}}' \
--endpoint-url http://localhost:8000
大師解釋,「即使三個請求同時到達,DynamoDB 會自動處理併發。每個 ADD 操作都是原子的,不會互相覆蓋。」
Hippo 這時插話:「讓我模擬一下併發場景!」他同時送出了三個並行的 ADD 操作。
洛基查詢結果:registered 準確地從 2 變成了 5。
「沒有鎖,沒有重試,沒有資料遺失。」洛基讚嘆,「但是...我有點困惑。在 SQL 的世界裡,這種併發問題通常要靠鎖或交易來處理,為什麼 DynamoDB 反而說不需要?」
大師微笑:「好問題。讓我問你,如果你是一個星際中央銀行,全星際分行的交易都要回到總行處理,會發生什麼事?」
「會塞車,」洛基立刻回答,「所有交易都要排隊等待。」
Hippo 搶著說:「沒錯。這就是傳統關聯式資料庫的處境。讓我給你看一張圖」
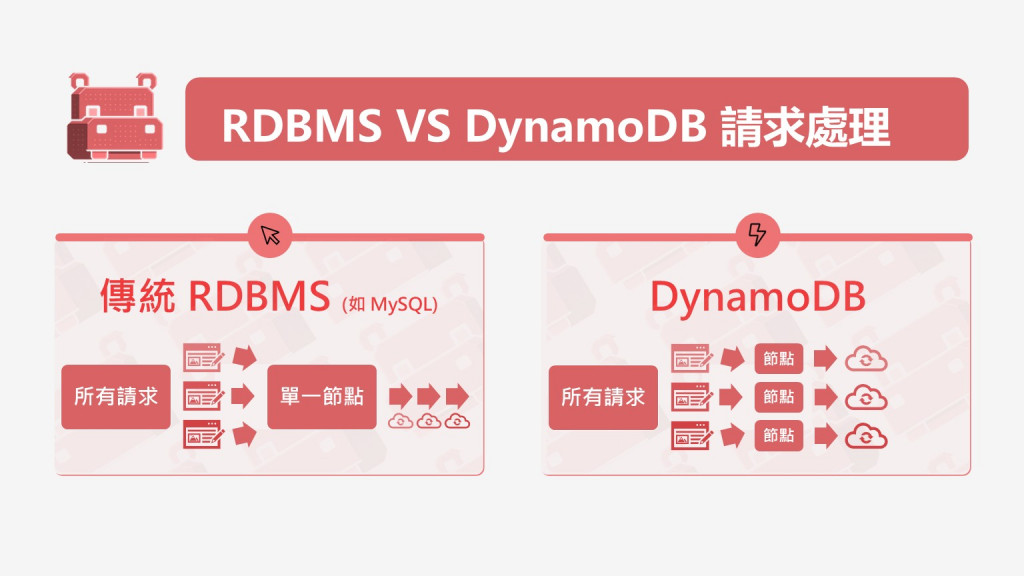
大師指著圖解釋:「MySQL 這類資料庫,每筆資料最終都要在一個節點上保持一致性。當你要更新一個值時,必須鎖定它,改完後釋放,其他人才能繼續。這就像只有一支筆,大家輪流用。」
「但 DynamoDB 不同。」大師繼續,「每個 item 根據主鍵被分配到特定的分區,而每個分區內部有自己的『原子計數器』機制。想像每個分區是一個獨立的收銀機,各自管理自己的帳本。」
洛基開始理解了:「所以當我對 EVENT#MARS-SY209 做 ADD 操作時...」
「正是!這個 item 只存在於一個特定分區中。」大師說,「DynamoDB 在分區層級實現了一個精巧的機制:每個 ADD 操作會被轉換成一個不可分割的指令。就像收銀機的『計數按鈕』,按一次就是加一,不存在『讀取當前值、加一、寫回』這種多步驟操作。」
「但等等,」洛基想到另一個問題,「DynamoDB 不是有多個副本嗎?怎麼保證它們都是對的?」
大師露出讚許的表情:「關鍵在於『最終一致性』和『強一致性讀取』的設計。當你執行 ADD registered :1 時」
大師在白板上寫著
1. 請求首先到達主副本(Leader)
2. 主副本執行原子操作,立即返回結果
3. 變更異步複製到其他副本
「如果你需要絕對準確的值,使用強一致性讀取,它會從主副本讀取。但即使是最終一致性,因為每個操作都是原子的,副本之間只是時間差,不會有數值錯誤。
DynamoDB 使用 Quorum 機制確保資料一致性:寫入時至少要有 2 個副本確認,讀取強一致性時也會檢查多個副本,確保拿到最新的值。」
洛基皺起眉頭:「等等,大師。您說每個分區有個主副本處理 ADD 操作,那在高併發時,這個主副本不也會成為瓶頸嗎?這和 MySQL 的單點處理有什麼不同?」
大師眼睛一亮:「非常銳利的觀察!來,給你看真正的差異。」他在白板繼續寫著:
MySQL 處理 UPDATE count = count + 1:
1. 讀取當前值 (需要 I/O)
2. 鎖定這一行
3. 在記憶體計算 new_value = old_value + 1
4. 寫入新值 (需要 I/O)
5. 寫入 transaction log
6. 釋放鎖
總時間:假設 5ms
DynamoDB 處理 ADD count :1:
1. 直接追加操作到 log (順序寫入)
2. 返回成功
總時間:假設 0.5ms
「看到關鍵了嗎?」大師問。
洛基仔細看著:「MySQL 要做 6 步,DynamoDB 只要 2 步?」
「不只是步驟數量,更重要的是『本質』的不同。」大師解釋,「MySQL 必須執行 Read-Modify-Write 循環,每個請求都要等待完整的 I/O 往返。但 DynamoDB 的 ADD 是一個『單向指令』。」
大師繼續說道:「DynamoDB 的主副本不是在處理『計算』,而是在處理『日誌追加』。它收到 ADD 指令後,只是把『+1』這個操作追加到操作日誌中,這是純粹的順序寫入,極其快速。實際的計算可以異步進行。」
Hippo 這時在白板上展示了兩種高併發場景的對比:
高併發場景對比:
MySQL (1000 個 +1 請求):
請求1: [讀取][計算][寫入] ----------> 5ms
請求2: 等待... [讀取][計算][寫入] --> 5ms
請求3: 等待... [讀取][計算][寫入]
總計:5000ms (串行處理)
DynamoDB (1000 個 +1 請求):
請求1: [追加log] -> 0.5ms
請求2: [追加log] -> 0.5ms
請求3: [追加log] -> 0.5ms
...同時處理...
總計:可能只需 50-100ms (批次處理 + 管線化)
「而且,」大師補充,「DynamoDB 還有個絕招:它可以將多個 ADD 操作合併。如果短時間內收到 100 個 +1 請求,它可以在日誌中記錄一個 +100,而不是 100 個 +1。」
洛基驚訝:「所以根本不是在同一個層次的競爭!」
「正是如此。」大師說,「MySQL 在應用層面處理業務邏輯,每個操作都要完整的資料庫事務。DynamoDB 在儲存引擎層面就設計了原子操作,把 ADD 當作基礎指令,就像 CPU 的原子指令一樣。」
「還有一點,」大師指向白板,「分區的威力:」
DynamoDB 的擴展性:
- EVENT#MARS-SY209 的 +1 操作 -> 分區 A 的 Leader
- EVENT#VENUS-SY210 的 +1 操作 -> 分區 B 的 Leader
- EVENT#EARTH-SY210 的 +1 操作 -> 分區 C 的 Leader
三個完全獨立,平行處理!
MySQL 的侷限:
- 所有 UPDATE 都要經過同一個主節點
- 即使分表,在單一交易中仍是串行
「所以 DynamoDB 的『優雅』在於,」洛基總結,「它不是把傳統資料庫的鎖機制做得更快,而是從根本上改變了遊戲規則。用 append-only log 取代 read-modify-write,用分區隔離取代全局鎖定。」
「而且每個分區可以獨立擴展。」大師補充,「當某個熱門活動報名量暴增時,DynamoDB 可以自動分割該分區,增加更多處理能力,而不影響其他活動。」
「我終於明白了,」洛基說,「這不是優化,是革命。」
大師點頭:「現在你明白了。當你使用 ADD、DELETE 這些原子操作時,你其實是在利用 DynamoDB 分散式架構的精髓。每個操作都是一個自給自足的指令,不依賴外部狀態,所以可以在任何分區、任何時間、以任何順序執行,結果都是正確的。」
「而且即使在一個操作中組合多個動作,這個原子式操作的本質一樣不受影響。」大師展示:
aws dynamodb update-item \
--table-name IntergalacticEvents \
--key '{"PK": {"S": "EVENT#MARS-SY209"}}' \
--update-expression "SET #status = :status, lastModified = :time ADD registered :inc" \
--expression-attribute-names '{"#status": "status"}' \
--expression-attribute-values '{
":status": {"S": "ACTIVE"},
":time": {"S": "SY210-03-20T10:00:00Z"},
":inc": {"N": "1"}
}' \
--endpoint-url http://localhost:8000
「一次請求完成三個更新:狀態改為 ACTIVE、更新時間戳、報名人數加一。」大師說。
「哇,這樣我完全不用再利用 Queue 或是一些錯開請求的方式來處理資料寫入了。不過...」洛基注意到一個細節:「為什麼 status 要用 #status?」
「好觀察。status 是 DynamoDB 的保留字,所以需要用 expression-attribute-names 來替換。」大師解釋,「這是一個小技巧,但很重要。」
Hippo 這時補充說:「也有人建議與其去查詢 DynamoDB 有哪些保留字,不如把所有使用到的 attribute name 都改成 # 開頭的表示法,雖然麻煩了一些,但可避免因撞到保留字而發生錯誤的問題。」
洛基點了點頭,「聽起來也是個務實的辦法,要記住哪些是保留字的確是不太可能。」
「現在你理解了原子操作的威力,」大師說,「讓我們看看如何結合條件表達式,實現更精確的控制。比如,如何防止活動超額報名?」
洛基思考:「需要檢查當前報名人數是否小於上限...」
「沒錯。」大師寫下:
# 只有在未滿額時才允許報名
aws dynamodb update-item \
--table-name IntergalacticEvents \
--key '{"PK": {"S": "EVENT#MARS-SY209"}}' \
--update-expression "ADD registered :inc" \
--condition-expression "registered < capacity" \
--expression-attribute-values '{":inc": {"N": "1"}}' \
--endpoint-url http://localhost:8000
「如果活動已滿,這個操作會失敗,返回 ConditionalCheckFailedException。」大師說,「這確保了資料的業務邏輯完整性。」
「另外,你還可以使用舊值來計算新值。」大師補充:
# 將報名費設為人數的10倍(動態計算)
aws dynamodb update-item \
--table-name IntergalacticEvents \
--key '{"PK": {"S": "EVENT#MARS-SY209"}}' \
--update-expression "SET fee = registered * :multiplier" \
--expression-attribute-values '{":multiplier": {"N": "10"}}' \
--endpoint-url http://localhost:8000
「Update 還能操作複雜的資料結構。」大師建立了一個新的測試資料:
{
"PK": {"S": "EVENT#ADVANCED-SY210"},
"speakers": {"L": [
{"S": "諾斯克大師"},
{"S": "戰神將軍"}
]},
"tags": {"SS": ["防禦", "戰略", "星際"]},
"metadata": {"M": {
"level": {"S": "advanced"},
"prerequisites": {"N": "3"}
}}
}
「現在,我們來添加一個新的講者:」
# 在列表末尾添加新講者
aws dynamodb update-item \
--table-name IntergalacticEvents \
--key '{"PK": {"S": "EVENT#ADVANCED-SY210"}}' \
--update-expression "SET speakers = list_append(speakers, :new_speaker)" \
--expression-attribute-values '{":new_speaker": {"L": [{"S": "洛基上尉"}]}}' \
--endpoint-url http://localhost:8000
「甚至可以更新嵌套的屬性:」
# 更新 metadata 中的 level
aws dynamodb update-item \
--table-name IntergalacticEvents \
--key '{"PK": {"S": "EVENT#ADVANCED-SY210"}}' \
--update-expression "SET metadata.#level = :new_level" \
--expression-attribute-names '{"#level": "level"}' \
--expression-attribute-values '{":new_level": {"S": "expert"}}' \
--endpoint-url http://localhost:8000
洛基驚訝:「這個使用彈性真是驚人。」
「這只是冰山一角。」大師說,「但記住,不要為了炫技而使用複雜功能。一般而言,選擇最簡單、最清晰的方案就是最好的方案。」
「現在,讓我們總結一下何時用 Put,何時用 Update。」大師在白板上畫了一個對比表:
Put-Item 適用場景:
✓ 建立全新的 item
✓ 需要完整替換(如狀態轉換)
✓ 冪等性寫入(如每日重置)
✓ 資料結構簡單且完整
Update-Item 適用場景:
✓ 部分欄位更新
✓ 原子計數器(庫存、計數)
✓ 併發更新場景
✓ 複雜資料結構操作
✓ 基於舊值計算新值
「Put 是畫家的畫布,每次都重新創作。Update 是雕刻家的鑿子,精準地修改細節。」大師總結。
「兩者都有其價值,關鍵是知道何時使用哪一個。」洛基理解了。
「這幾天我們學了 put-item 和 update-item,資料已經妥善存入 DynamoDB。」大師說,「但寫入是為了讀取。明天,我們要學習如何有效地查詢資料。 但今天,好好消化 Update 的概念,它會是你最常用的工具之一。」
洛基起身敬禮:「謝謝大師。Update 的原子性操作確實解決了我很多疑慮。」
走出工作室時,基回頭看了一眼白板上的圖表。Put 和 Update,簡單和精準,各有所用,他始理解 DynamoDB 的設計哲學了。
Hippo:「來,讓我教你 UpdateExpression 的完整武器庫!」
# 設定單一值
SET attribute = :value
# 設定多個值
SET attr1 = :val1, attr2 = :val2
# 使用函數
SET attribute = if_not_exists(attribute, :default)
SET counter = attribute + :increment
SET list = list_append(list, :new_items)
# 數字增減
ADD counter :increment # 可以是正數或負數
# 集合添加元素
ADD tags :new_tags # 添加到 String Set
# 移除屬性
REMOVE attribute
# 移除多個屬性
REMOVE attr1, attr2
# 移除列表元素(按索引)
REMOVE list[0]
# 從集合中刪除特定元素
DELETE tags :tags_to_remove
if_not_exists(path, value)
SET view_count = if_not_exists(view_count, :zero) + :increment
list_append(list1, list2)
SET messages = list_append(messages, :new_messages)
SET messages = list_append(:new_messages, messages) # 前置
DynamoDB 有很多保留字,常見的包括:
使用 expression-attribute-names 來處理:
--expression-attribute-names '{
"#s": "status",
"#n": "name",
"#t": "time"
}'
批次處理 vs 原子操作
條件表達式的使用
返回值的選擇
NONE(預設)是最高效的版本控制模式
# 樂觀鎖定
--update-expression "SET data = :new_data, version = version + :one" \
--condition-expression "version = :current_version"
// UpdateItem 返回值選項詳解
const returnValuesGuide = {
NONE: {
描述: "不返回任何值(預設)",
使用場景: "當你不需要確認更新結果時",
優點: "最高效,最少網路傳輸",
範例回應: {
// 只有 ConsumedCapacity 等元數據
}
},
ALL_OLD: {
描述: "返回更新前的完整項目",
使用場景: "需要備份或審計舊值",
優點: "可以知道被替換的完整資料",
範例回應: {
Attributes: {
id: "USER#123",
name: "舊名字",
score: 100,
updated: "SY210-01-01"
}
}
},
ALL_NEW: {
描述: "返回更新後的完整項目",
使用場景: "需要立即使用更新後的資料",
優點: "省去額外的 GetItem 操作",
範例回應: {
Attributes: {
id: "USER#123",
name: "新名字",
score: 150, // 更新了
updated: "SY210-07-15" // 更新了
}
}
},
UPDATED_OLD: {
描述: "只返回被更新屬性的舊值",
使用場景: "只關心哪些欄位被改變",
優點: "精確追蹤變更,減少傳輸量",
範例回應: {
Attributes: {
// 只有被更新的屬性
score: 100,
updated: "SY210-01-01"
}
}
},
UPDATED_NEW: {
描述: "只返回被更新屬性的新值",
使用場景: "確認更新是否成功應用",
優點: "最小傳輸量,精確確認",
範例回應: {
Attributes: {
// 只有被更新的屬性
score: 150,
updated: "SY210-07-15"
}
}
}
};
// 如何選擇正確的返回值
function chooseReturnValue(scenario) {
const decisionTree = {
"需要舊值做備份?": "ALL_OLD",
"需要立即使用更新後的完整資料?": "ALL_NEW",
"只關心哪些欄位被改變?": "UPDATED_OLD",
"只需確認更新的值?": "UPDATED_NEW",
"純粹更新,不需要任何返回?": "NONE"
};
return decisionTree[scenario];
}
// 關鍵差異對比
const comparisonChart = {
PutItem: {
支援選項: ["NONE", "ALL_OLD"],
原因: "完全替換操作,新值已知",
典型用法: "替換前備份"
},
UpdateItem: {
支援選項: ["NONE", "ALL_OLD", "ALL_NEW", "UPDATED_OLD", "UPDATED_NEW"],
原因: "部分更新,需要追蹤變化",
典型用法: "精確控制和追蹤"
}
};
Hippo 總結:「記住,返回值的選擇直接影響效能和成本。只在真正需要時才要求返回值,大部分情況下 NONE 就足夠了!」

