「大師,」洛基坐下後說,「這幾天我們一直在寫入資料,但在實際系統中,讀取的頻率通常比寫入高很多。」
「很好的觀察。」諾斯克倒了兩杯茶,「在 DynamoDB 中,有兩種基本的讀取方式:get-item 和 query。你覺得它們有什麼差別?」
「Get 是取得單一項目,Query 是查詢?」洛基猜測。
大師微笑:「表面上是這樣,你還記得我們的筷子遊戲嗎?取單色筷子行為就像 get-item,而雙色筷子就像 Query,你可以一次拉出一把來。」
洛基想起了第二天的遊戲,體會其中的不同。
大師接著問:「如果要找一個特定的活動,和找某個星球的所有活動,你會用同樣的方法嗎?」
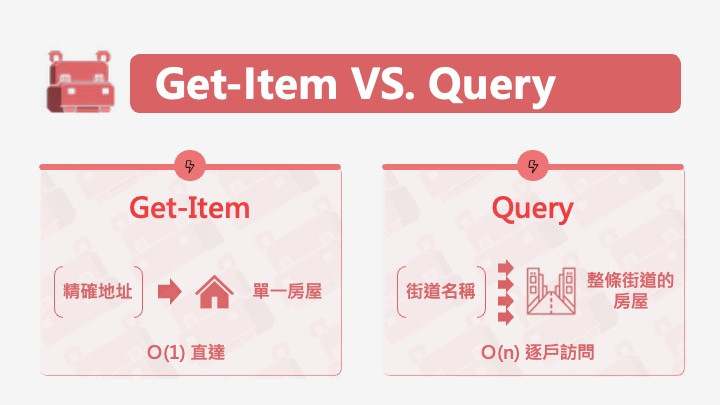
洛基思考片刻:「應該不會。找特定活動就像查地址,直接去就好。找某個星球的所有活動,就要在那個區域搜索。」
「答得很好!」Hippo 突然出聲,秀出了一張圖:
「先從 get-item 開始。」大師說,「還記得我們的火星防禦研討會嗎?」
# Get-Item:必須提供完整主鍵
aws dynamodb get-item \
--table-name IntergalacticEvents \
--key '{"PK": {"S": "EVENT#MARS-SY209"}}' \
--endpoint-url http://localhost:8000
「Get 的特點很明確:」大師在白板寫下:
Get-Item 特性:
✓ 必須提供完整主鍵(PK,如果有 SK 也要)
✓ 只返回一個 item
✓ 效能穩定可預測(O(1))
✓ 成本固定(1 RCU,選擇強一致性加倍成 2 RCU)
「就像狙擊手,」洛基比喻,「一發一個目標,精準但範圍有限。」
「沒錯。而且因為直接定位,所以極快。」大師說,「DynamoDB 根據主鍵的雜湊值,直接知道資料在哪個分區、哪個位置。」
Hippo 插話:「就像你知道朋友的完整地址,直接導航過去,不需要在街上問人。」
「但是,」大師話鋒一轉,「如果你想找『火星上所有的活動』呢?」
洛基皺眉:「用 Get 的話...我必須知道每個活動的確切 ID。」
「正是問題所在。」大師說,「所以我們需要 Query。但首先,讓我們調整資料結構來展示 Query 的威力。」
大師建立了新的測試資料:
# 新的資料結構:使用複合主鍵
# PK = LOCATION#星球名稱
# SK = DATE#日期#EVENT#編號
# 火星的活動
aws dynamodb put-item \
--table-name IntergalacticEvents \
--item '{
"PK": {"S": "LOCATION#MARS"},
"SK": {"S": "DATE#SY209-06-15#EVENT#001"},
"name": {"S": "火星防禦研討會"},
"capacity": {"N": "500"},
"speaker": {"S": "Asimov"}
}' \
--endpoint-url http://localhost:8000
aws dynamodb put-item \
--table-name IntergalacticEvents \
--item '{
"PK": {"S": "LOCATION#MARS"},
"SK": {"S": "DATE#SY209-07-20#EVENT#002"},
"name": {"S": "火星殖民地會議"},
"capacity": {"N": "300"},
"speaker": {"S": "殖民部長"}
}' \
--endpoint-url http://localhost:8000
aws dynamodb put-item \
--table-name IntergalacticEvents \
--item '{
"PK": {"S": "LOCATION#MARS"},
"SK": {"S": "DATE#SY209-08-10#EVENT#003"},
"name": {"S": "火星資源開發論壇"},
"capacity": {"N": "200"},
"speaker": {"S": "礦業大亨"}
}' \
--endpoint-url http://localhost:8000
# 地球的活動
aws dynamodb put-item \
--table-name IntergalacticEvents \
--item '{
"PK": {"S": "LOCATION#EARTH"},
"SK": {"S": "DATE#SY209-06-15#EVENT#004"},
"name": {"S": "地球防衛會議"},
"capacity": {"N": "1000"},
"speaker": {"S": "地球總統"}
}' \
--endpoint-url http://localhost:8000
「看到結構的巧思了嗎?」大師問。
洛基觀察:「所有火星的活動都有相同的 PK,但 SK 不同。而且 SK 包含了日期,所以會自動按時間排序!」
大師讚許,「這就是複合主鍵的威力。」
「現在,讓我們用 Query 找出火星上的所有活動。」
# Query:只需要 Partition Key
aws dynamodb query \
--table-name IntergalacticEvents \
--key-condition-expression "PK = :pk" \
--expression-attribute-values '{":pk": {"S": "LOCATION#MARS"}}' \
--endpoint-url http://localhost:8000
執行後,返回了三個火星的活動,而且按照日期排序。
「Query 像是區域掃蕩,」洛基說,「在特定區域內搜索所有目標。」
「而且你可以更精確。」大師展示:
# 查詢火星上 SY210-07 月之後的活動
aws dynamodb query \
--table-name IntergalacticEvents \
--key-condition-expression "PK = :pk AND SK >= :sk_start" \
--expression-attribute-values '{
":pk": {"S": "LOCATION#MARS"},
":sk_start": {"S": "DATE#SY209-07"}
}' \
--endpoint-url http://localhost:8000
「甚至可以用前綴搜索:」
# 查詢火星上所有SY210-06 月的活動
aws dynamodb query \
--table-name IntergalacticEvents \
--key-condition-expression "PK = :pk AND begins_with(SK, :sk_prefix)" \
--expression-attribute-values '{
":pk": {"S": "LOCATION#MARS"},
":sk_prefix": {"S": "DATE#SY209-06"}
}' \
--endpoint-url http://localhost:8000
「在比較兩者之前,」Hippo 插話,「讓我先解釋 DynamoDB 獨特的計費機制。菜鳥,你以前用 MySQL 時,知道一個查詢會用多少資源嗎?」
洛基想了想:「這...我從來沒想過。好像只要伺服器夠強,就能處理?」
「就怕你這樣想!」Hippo 在白板上畫了對比圖:
MySQL 的世界:
[你的查詢] → [MySQL 伺服器] → [結果]
↑
用多少算多少
(CPU/記憶體/磁碟 I/O)
DynamoDB 的世界:
[你的查詢] → [預購的容量] → [結果]
↑
事先買好「票券」
(RCU/WCU)
「為什麼要這樣設計?」Hippo 解釋,「因為 DynamoDB 是無伺服器的!AWS 需要預先知道要為你準備多少資源。」
容量單位機制:
• RCU (Read Capacity Unit) = 讀取資源的預約券
• WCU (Write Capacity Unit) = 寫入資源的預約券
具體保證:
• 1 RCU = 每秒穩定讀取 4KB(強一致性)或 8KB(最終一致性)
• 1 WCU = 每秒穩定寫入 1KB
💡 這不是限制,而是性能保證!
就像包廂預約 - 保證有位子,保證服務品質
洛基恍然大悟:「所以這就是為什麼 DynamoDB 能做到毫秒級延遲保證?」
「正是!」大師接過話題,「現在讓我們深入比較兩者:」
Get-Item Query
----------------------------------------------------------------
時間複雜度 O(1) 固定 O(n) n=結果數量
必要條件 完整主鍵 只需 Partition Key
返回數量 0 或 1 個 0 到多個
成本計算 固定 RCU 依返回的資料量計算 RCU
最佳使用場景 已知確切 ID 列表、範圍查詢
效能預測 完全可預測 取決於結果集大小
Hippo 補充:「來看實際的 RCU 計算:」
Get-Item 成本範例:
• Item 大小 2KB,最終一致性 → 1 RCU (2KB/8KB,無條件進位)
• Item 大小 2KB,強一致性 → 1 RCU (2KB/4KB,無條件進位)
• Item 大小 10KB,最終一致性 → 2 RCU (10KB/8KB,無條件進位)
Query 成本範例:
• 返回 5 個 item,每個 1KB,最終一致性 → 1 RCU (5KB/8KB,無條件進位)
• 返回 10 個 item,每個 1KB,強一致性 → 3 RCU (10KB/4KB,無條件進位)
「舉個實際例子,」大師說,「假設火星上有 1000 個活動:」
Get 特定活動:
- 時間:~10ms(不管資料庫多大)
- 成本:1 RCU(假設 item 2KB)
Query 所有火星活動(1000 個活動,每個 2KB):
- 時間:可能 100-200ms
- 總資料量:1000 × 2KB = 2000KB
- 成本:2000KB ÷ 8KB = 250 RCU(最終一致性)
洛基看著這些數字,若有所思:「這個成本差異很大耶!1 RCU vs 250 RCU...但如果我需要顯示活動列表,總不能執行 1000 次 Get 吧?那樣豈不是更貴?」
「你抓到重點了!」大師讚許,「成本的思考也是 DynamoDB 設計的核心原則之一。記得我之前提醒過的網狀思考,你不能只用單一方向來想事情。」
Hippo 補充:「在傳統 SQL 中,你先建表,再想查詢。但在 DynamoDB,你必須先確定查詢模式,再設計表結構。」
「沒錯,」大師強調,「如果你經常需要『查詢某個用戶的所有訂單』,那麼設計時就要把用戶 ID 作為 PK,訂單相關資訊作為 SK。這樣一個 Query 就能高效取得所有資料,而且合乎成本。」
「讓我展示 Sort Key 條件的各種可能。」大師寫下:
# Sort Key 支援的條件操作符:
# = : 精確匹配
# < : 小於
# <= : 小於等於
# > : 大於
# >= : 大於等於
# BETWEEN : 範圍
# begins_with : 前綴匹配
# 範例:查詢特定日期範圍的活動
aws dynamodb query \
--table-name IntergalacticEvents \
--key-condition-expression "PK = :pk AND SK BETWEEN :start AND :end" \
--expression-attribute-values '{
":pk": {"S": "LOCATION#MARS"},
":start": {"S": "DATE#SY209-06-01"},
":end": {"S": "DATE#SY209-06-30"}
}' \
--endpoint-url http://localhost:8000
「這就是為什麼 Sort Key 的設計如此重要。」大師說,「它不只是排序,更是查詢的關鍵。」
洛基若有所思:「所以 SK 的前綴設計很關鍵。DATE#SY209-06-15 這樣的格式,讓我們可以查詢年、月、或特定日期。」
「你學得很快!」大師讚許。
「還有一個重要概念。」大師補充,「讀取時的一致性選擇。」
# 最終一致性讀取(預設)
aws dynamodb get-item \
--table-name IntergalacticEvents \
--key '{"PK": {"S": "LOCATION#MARS"}, "SK": {"S": "DATE#SY209-06-15#EVENT#001"}}' \
--endpoint-url http://localhost:8000
# 強一致性讀取
aws dynamodb get-item \
--table-name IntergalacticEvents \
--key '{"PK": {"S": "LOCATION#MARS"}, "SK": {"S": "DATE#SY209-06-15#EVENT#001"}}' \
--consistent-read \
--endpoint-url http://localhost:8000
Hippo 解釋:「最終一致性讀取可能會讀到稍微過時的資料(通常是毫秒級),但成本只要一半。強一致性保證讀到最新資料,但成本加倍。」
「實務上,」大師說,「大部分場景最終一致性就夠了。只有在讀取剛寫入的資料,或需要絕對最新值時,才用強一致性。」
「現在總結一下使用原則。」大師在白板上寫:
何時用 Get-Item:
✓ 知道完整的主鍵
✓ 只需要單一 item
✓ 需要最佳效能
✓ 成本可預測很重要
何時用 Query:
✓ 需要多個相關 items
✓ 只知道部分鍵值(PK)
✓ 需要範圍查詢
✓ 需要排序結果
設計原則:
1. 高頻查詢 → 設計成 Get(透過良好的主鍵設計)
2. 列表需求 → 設計成 Query(利用 Sort Key)
3. 兩者結合 → Get 取主資料,Query 取相關資料
洛基總結:「Get 用於已知的精確查詢,Query 用於範圍查詢。」
大師滿意地說,「就像戰術選擇,精確打擊還是區域控制,取決於任務需求。現在你對基本存取已經有概念了,明天,我們可以來重新思考資料的組織方式了。 」
「來,讓我詳細解釋一致性讀取!」Hippo 說。
// RCU (Read Capacity Units) 計算:
// 最終一致性:1 RCU = 8KB/秒
// 強一致性: 1 RCU = 4KB/秒(成本加倍)
// Item 大小 3KB 的讀取成本:
// 最終一致性:1 RCU (3KB / 8KB = 0.375,無條件進位到 1)
// 強一致性: 1 RCU (3KB / 4KB = 0.75,無條件進位到 1)
// 實用的 RCU 計算函數
function calculateRCU(itemSizeKB, isStronglyConsistent = false) {
const baseSize = isStronglyConsistent ? 4 : 8;
return Math.ceil(itemSizeKB / baseSize);
}
// 範例
console.log(calculateRCU(3, false)); // 1 RCU (最終一致性)
console.log(calculateRCU(3, true)); // 1 RCU (強一致性)
console.log(calculateRCU(10, false)); // 2 RCU (最終一致性)
「只想要特定欄位?用投影表達式!」
# 只返回 name 和 capacity
aws dynamodb get-item \
--table-name IntergalacticEvents \
--key '{"PK": {"S": "LOCATION#MARS"}, "SK": {"S": "DATE#SY209-06-15#EVENT#001"}}' \
--projection-expression "name, capacity" \
--endpoint-url http://localhost:8000
# Query 也可以用
aws dynamodb query \
--table-name IntergalacticEvents \
--key-condition-expression "PK = :pk" \
--expression-attribute-values '{":pk": {"S": "LOCATION#MARS"}}' \
--projection-expression "name, #date" \
--expression-attribute-names '{"#date": "date"}' \
--endpoint-url http://localhost:8000
// JavaScript SDK v3 範例展示各種 SK 條件
import { DynamoDBClient } from "@aws-sdk/client-dynamodb";
import { DynamoDBDocumentClient, QueryCommand } from "@aws-sdk/lib-dynamodb";
const client = new DynamoDBClient({
endpoint: "http://localhost:8000",
region: "local"
});
const docClient = DynamoDBDocumentClient.from(client);
// 1. 精確匹配
const exactMatch = await docClient.send(new QueryCommand({
TableName: "IntergalacticEvents",
KeyConditionExpression: "PK = :pk AND SK = :sk",
ExpressionAttributeValues: {
":pk": "LOCATION#MARS",
":sk": "DATE#SY209-06-15#EVENT#001"
}
}));
// 2. 範圍查詢
const rangeQuery = await docClient.send(new QueryCommand({
TableName: "IntergalacticEvents",
KeyConditionExpression: "PK = :pk AND SK BETWEEN :start AND :end",
ExpressionAttributeValues: {
":pk": "LOCATION#MARS",
":start": "DATE#SY209-06-01",
":end": "DATE#SY209-06-30"
}
}));
// 3. 前綴匹配(最常用!)
const prefixQuery = await docClient.send(new QueryCommand({
TableName: "IntergalacticEvents",
KeyConditionExpression: "PK = :pk AND begins_with(SK, :prefix)",
ExpressionAttributeValues: {
":pk": "LOCATION#MARS",
":prefix": "DATE#SY209-06"
}
}));
Limit 參數
# 只取前 5 筆
--limit 5
注意:Limit 是在過濾前執行,可能返回少於預期的結果
反向排序
# 從新到舊
--scan-index-forward false
Count 操作
# 只要數量,不要資料
--select COUNT
需要讀取資料?
↓
知道完整主鍵?
├─ 是 → Get-Item
└─ 否 → 知道 Partition Key?
├─ 是 → Query
└─ 否 → 需要全表搜尋(明天的 Scan)
錯誤:試圖用 Query 跨分區
# 這不會工作!
--key-condition-expression "SK = :sk" # 沒有 PK!
錯誤:Get-Item 只提供 PK(當有 SK 時)
# 如果表有 SK,這會返回空
--key '{"PK": {"S": "LOCATION#MARS"}}' # 缺少 SK!
錯誤:混淆 Filter 和 Key Condition

