洛基站在白板前,大師坐在茶桌旁,沒有說話。
這是第30天——最後一天。
白板上畫著一個場景:
星際大會即將開幕
預期:100,000 名參與者同時註冊
系統配置:
- 主表容量:5,000 WCU
- 預期流量:10,000 writes/sec
問題:
CloudWatch 告警:ThrottlingException 持續發生
但容量使用率只有 60%
診斷?
洛基仔細分析白板上的數字:「容量夠,但限流...熱分區?」
「可能,」大師說,「但你要怎麼確認?怎麼解決?」
洛基深吸一口氣。29天的學習,就是為了這一刻——能夠獨立診斷和解決真實問題。
「Hippo,」他說,「顯示 Contributor Insights 數據。」
Hippo 的螢幕顯示:
Top Contributors (寫入)
Partition Key | 寫入次數/秒 | 佔比
---------------------------------|------------|------
EVENT#galactic-summit | 9,500 | 95%
EVENT#workshop-ai | 300 | 3%
EVENT#meetup-mars | 200 | 2%
診斷:EVENT#galactic-summit 是熱分區
洛基指著第一行:「95% 的寫入都打到同一個 PK。雖然總容量 5,000 WCU,但這個 PK 所在的分區可能只有幾百 WCU...」
「正確,」大師站起來,走到白板前,「Hippo,請顯示案例的分區架構。」
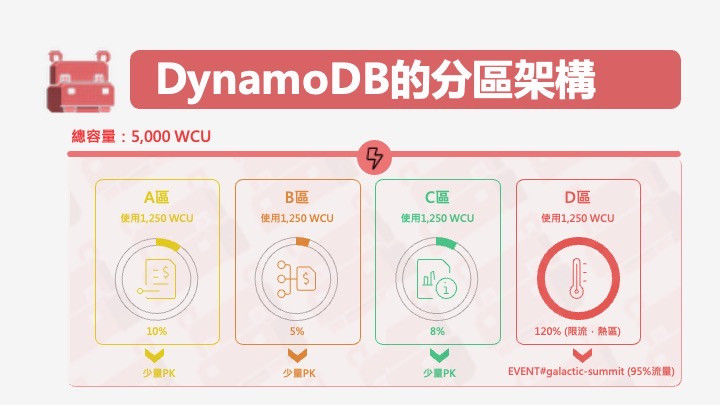
「雖然總容量充足,」大師說,「但所有流量集中在分區 D。它的 1,250 WCU 無法承受 9,500 writes/sec。」
洛基理解了:「這就是熱分區——容量分佈不均的問題。」
大師點頭:「現在的挑戰是:如何解決?」
洛基思考片刻,在筆記本上寫下:「既然問題是單一 PK 流量過大,那就...分散 PK?」
「怎麼分散?」大師問。
洛基畫出設計:
原本的設計(熱分區)
// ❌ 所有人註冊同一活動,寫入同一個 PK
async function registerEvent(userId, eventId) {
await docClient.put({
TableName: 'Registrations',
Item: {
PK: `EVENT#${eventId}`, // 所有人都是這個 PK
SK: `USER#${userId}`,
registeredAt: Date.now(),
status: 'confirmed'
}
});
}
// 問題:10,000 writes/sec 全部打到 EVENT#galactic-summit
分散式設計(解決熱分區)
// ✓ 加入分片後綴,分散到多個 PK
const crypto = require('crypto');
async function registerEvent(userId, eventId) {
// 使用 hash 確保均勻分佈(0-9)
const hash = crypto.createHash('md5').update(userId).digest('hex');
const shardId = parseInt(hash.slice(0, 2), 16) % 10;
await docClient.put({
TableName: 'Registrations',
Item: {
PK: `EVENT#${eventId}#SHARD${shardId}`, // 分散到 10 個 PK
SK: `USER#${userId}`,
eventId: eventId, // 原始 eventId 保留,供查詢用
shardId: shardId,
registeredAt: Date.now(),
status: 'confirmed'
}
});
}
// 結果:
// - 10,000 writes/sec 分散到 10 個 PK
// - 每個 PK 只承受 1,000 writes/sec
// - 單一分區壓力大幅降低
// - hash 確保即使 userId 不隨機也能均勻分佈
大師看著設計:「分散寫入解決了。但查詢怎麼辦?」
洛基意識到問題:「要查詢某個活動的所有參與者,需要查 10 個分片...」
「對,」大師說,「這就是權衡——分散寫入壓力,但增加讀取複雜度。」
讀取的處理方式
// 查詢某活動的所有參與者(需要查所有分片)
async function getEventParticipants(eventId) {
const shards = Array.from({ length: 10 }, (_, i) => i);
// 並行查詢所有分片
const results = await Promise.all(
shards.map(shard =>
docClient.query({
TableName: 'Registrations',
KeyConditionExpression: 'PK = :pk',
ExpressionAttributeValues: {
':pk': `EVENT#${eventId}#SHARD${shard}`
}
})
)
);
// 合併結果
const allParticipants = results.flatMap(r => r.Items);
return allParticipants;
}
// 優化:用 GSI 反向查詢
// GSI_PK: USER#${userId}
// GSI_SK: EVENT#${eventId}
// 這樣可以避免查詢所有分片
洛基思考:「所以分片數量是個權衡——太少無法分散,太多增加查詢複雜度。」
「正確,」大師說,「通常 10-100 個分片是合理範圍,取決於流量規模。」
「還有其他方法嗎?」洛基問。
大師展示第二種策略:
// 場景:活動報名在特定時間爆發(如:開放報名的瞬間)
// ✓ 時間分片:在 PK 中加入時間維度
async function registerEvent(userId, eventId) {
const timeBucket = getTimeBucket(); // 例如:2210-04-20-10(小時)
await docClient.put({
TableName: 'Registrations',
Item: {
PK: `EVENT#${eventId}#${timeBucket}`, // 每小時一個 PK
SK: `USER#${userId}`,
eventId: eventId,
registeredAt: Date.now()
}
});
}
function getTimeBucket() {
const now = new Date();
return `${now.getUTCFullYear()}-${String(now.getUTCMonth()+1).padStart(2,'0')}-${String(now.getUTCDate()).padStart(2,'0')}-${String(now.getUTCHours()).padStart(2,'0')}`;
}
// 優點:
// - 時間自然分散流量
// - 適合時間序列資料
// - 查詢時可按時間範圍查詢
// 適用場景:
// - 日誌系統(每小時/每天一個分區)
// - 時間序列監控資料
// - 活動報名(按時段分散)
洛基比較兩種策略:「用戶分片適合長期存取的資料,時間分片適合時間序列資料。」
「對,」大師說,「選擇策略取決於資料特性和查詢模式。」
「如果問題不是寫入,而是讀取呢?」大師提出新場景。
場景:熱門活動資訊被大量讀取
問題:
- 活動詳情頁:50,000 QPS
- 單一 PK: EVENT#galactic-summit
- 配置:5,000 RCU
- 結果:ReadThrottleEvents
如何解決?
洛基想了想:「讀取熱分區...不能用分片,因為活動資訊只有一份。」
「對,」大師說,「這時要用讀寫分離。」
// 策略:快取層 + CDN
const readWriteSeparation = {
// 1. 寫入:直接寫 DynamoDB
write: async (eventId, data) => {
await docClient.put({
TableName: 'Events',
Item: {
PK: `EVENT#${eventId}`,
SK: 'METADATA',
...data
}
});
// 同時更新快取
await cache.set(`event:${eventId}`, data, { ttl: 300 });
},
// 2. 讀取:優先從快取
read: async (eventId) => {
// 先查快取(ElastiCache/CloudFront)
const cached = await cache.get(`event:${eventId}`);
if (cached) return cached;
// 快取未命中,查 DynamoDB
const result = await docClient.get({
TableName: 'Events',
Key: {
PK: `EVENT#${eventId}`,
SK: 'METADATA'
}
});
// 寫回快取
if (result.Item) {
await cache.set(`event:${eventId}`, result.Item, { ttl: 300 });
}
return result.Item;
}
};
// 結果:
// - 99% 讀取命中快取,不打 DynamoDB
// - DynamoDB 只承受 1% 的讀取流量
// - 熱分區問題解決
洛基記下這個策略:「所以不是所有問題都要在 DynamoDB 層解決,有時候加一層快取更有效。」
「正確,」大師說,「系統設計是多層次的。」
「現在,」大師說,「設計完整的解決方案。」
洛基在白板上寫下綜合方案:
// 星際大會:100,000 人註冊,解決方案
const crypto = require('crypto');
// 1. 寫入分散(10 個分片)
async function registerForSummit(userId) {
// 使用 hash 確保均勻分佈
const hash = crypto.createHash('md5').update(userId).digest('hex');
const shard = parseInt(hash.slice(0, 2), 16) % 10;
await docClient.put({
TableName: 'Registrations',
Item: {
PK: `EVENT#galactic-summit#S${shard}`,
SK: `USER#${userId}`,
eventId: 'galactic-summit',
userId: userId,
shard: shard,
registeredAt: Date.now()
}
});
// 同時更新聚合統計(避免每次查詢所有分片)
await incrementCounter('galactic-summit');
}
// 2. 聚合統計(Lambda + Streams)
// 用 Streams 觸發 Lambda,即時更新總人數
exports.handler = async (event) => {
for (const record of event.Records) {
if (record.eventName === 'INSERT') {
const item = unmarshall(record.dynamodb.NewImage);
if (item.PK.startsWith('EVENT#galactic-summit')) {
// 更新聚合統計
await docClient.update({
TableName: 'EventStats',
Key: {
PK: 'EVENT#galactic-summit',
SK: 'STATS'
},
UpdateExpression: 'ADD totalRegistrations :inc',
ExpressionAttributeValues: { ':inc': 1 }
});
}
}
}
};
// 3. 查詢優化(GSI)
// GSI1: 按用戶查詢「我報名了哪些活動」
// GSI1_PK: USER#${userId}
// GSI1_SK: EVENT#${eventId}
// 這樣可以:
// - 避免查詢所有分片
// - 提供高效的用戶視角查詢
// 4. 讀取快取(活動詳情)
// 用 CloudFront 快取活動詳情頁
// TTL: 5 分鐘
// 降低 DynamoDB 讀取壓力
// 結果:
const performance = {
寫入分散: '10,000 writes/sec 分散到 10 個分區',
每分區壓力: '1,000 writes/sec(容量內)',
讀取優化: '快取命中率 99%',
統計查詢: '聚合視圖,無需掃描所有分片',
零限流: true
};
大師檢視設計,點頭:「很完整。你已經能獨立設計生產級系統了。」
大師站起身,走到窗邊。
星空中,星球依然沿著軌道運行,如同三十天前洛基第一次來到茶室時看到的景象。
「三十天前,」大師說,「你帶著疑惑不知道如何學DynamoDB 。」
洛基點頭,記得那天的困惑。
「現在,」大師轉過身,「如果有人問你同樣的問題,你會怎麼回答?」
洛基想了想,緩緩說:
「我會說:
DynamoDB 的學習,不是背語法、記指令,
而是建立一種全新的設計思維。
從 SQL 的關聯思維,轉換到 Access Pattern 優先的思維。
從追求靈活性,轉換到接受權衡的智慧。
從單純的技術實現,轉換到成本可見性的設計。
這個過程需要時間,需要實踐,需要犯錯和反思。
但一旦建立起這種思維,你會發現——
DynamoDB 不是限制,而是工具。
知道它能做什麼、不能做什麼,
才能在合適的場景發揮它的價值。」
大師微笑:「你已經準備好了。」
洛基收起筆記本,裡面密密麻麻記錄了三十天的學習——從基礎概念到複雜設計,從迷惑到清晰,從學習者到實踐者。
他站起身,走向門口。
「謝謝,」他說。
大師揮揮手:「去吧。去完成你的任務。莉莎指揮官和 B-613 的人們,正等著你帶回這份知識。」
洛基推開茶室的門,夜空中,地球的城市燈火已經漸漸暗下。
他的飛船停在不遠處,艙門緩緩開啟。
三十天前,他帶著星球的托負與期盼來到這裡——一個在玫瑰星系內戰中受傷退居後勤的特種軍人,肩負著為跨星際開發者大會建置系統的任務。
那時的他,對 DynamoDB 所知有限,對分散式系統充滿疑惑。
而現在,他帶著完整的知識體系、系統化的思維方式、以及對未來的清晰方向感,準備返回 B-613。
飛船緩緩升空,穿過地球的大氣層,駛向玫瑰星系。
透過艙窗,洛基看著地球漸漸縮小成一個光點。
他想起大師第一天說的話:「思考是網狀的,資訊會落在各個點上。」
他想起這三十天的每個瞬間——從困惑到頓悟,從犯錯到修正。他不只是獲得技術,更是思維上的轉換——從關聯式資料庫的線性思考,到 NoSQL 的網狀設計;從追求完美方案,到接受權衡與約束的智慧。
洛基閉上眼睛,左腿的痛似已經逐漸消失。當年的冒進的代價讓他學會謹慎規劃;現在的學習讓他懂得系統思考。一個成熟的系統設計師將帶著知識返航。
而在遙遠的地球,茶室的燈依然亮著。
星空依然運轉。
學習永不止息。
時間設定說明:故事中使用星際曆(SY210 = 西元2210年),程式碼範例為確保正確執行,使用對應的西元年份。
終於完成三十天了,很不容易。歡迎有在讀的邦友路過打聲招呼。

覺得這些思維「不只 DynamoDB,在 OLAP 也用得到」

