
到目前為止,我們已經把 EKS 叢集的基礎設施打通:從 Pod → Service → Ingress → Load Balancer → DNS,都能自動化完成。接下來,問題就變成:我們怎麼知道這些東西真的有在正常運作?
這就是 Monitoring(監控) 的角色所要滿足的目標。今天的主角是 kube-prometheus-stack 這張 Helm Chart,以及他幫我們部署出來的 Prometheus、Grafana 及 AlertManager。基本上這個組合也是幾乎所有 Kubernetes 環境監控的基石。
在開始之前,我們需要先了解 kube-prometheus-stack 這個 Helm Chart —— 它不只是簡單安裝 Prometheus,而是提供了一套完整的 Kubernetes 監控解決方案。
kube-prometheus-stack 包含以下關鍵元件:
/metrics 來收集、並儲存 metrics。通常也會對這個元件下 PromQL query 來對 metrics 進行聚合、計算整個監控系統的運作流程如下:
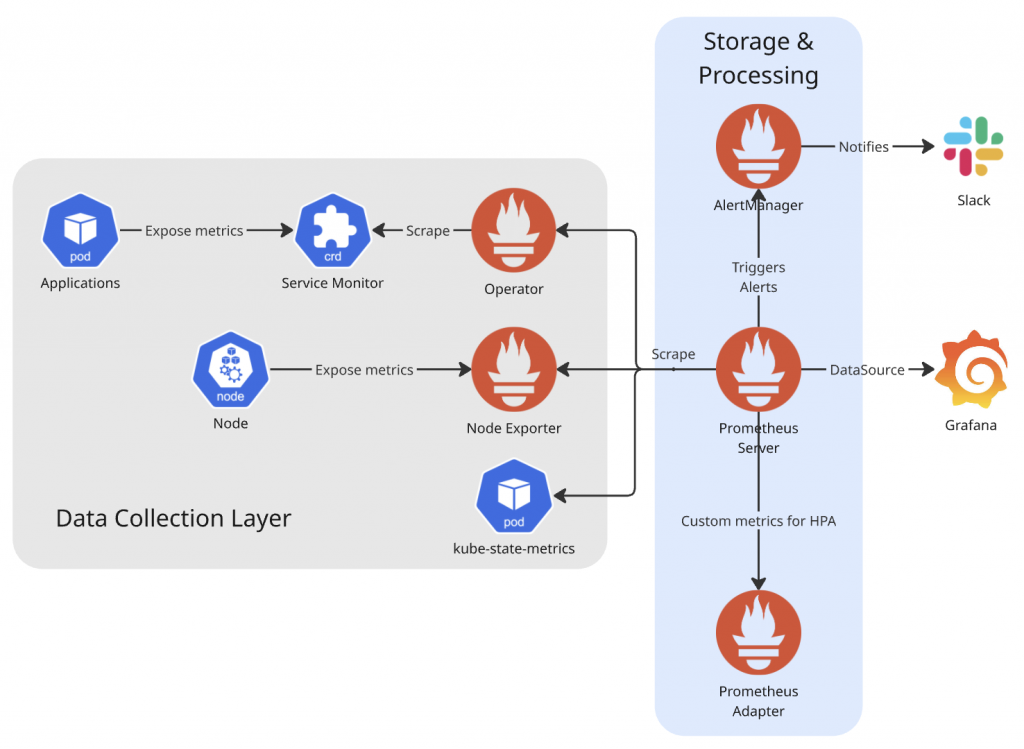
/metrics endpoint傳統的 Prometheus 需要手動配置 scrape_configs,但在 Kubernetes 環境中,Pod 會動態建立和銷毀。ServiceMonitor 這個 CRD 解決了這個痛點:
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
name: my-app-monitor
spec:
selector:
matchLabels:
app: my-app
endpoints:
- port: metrics
path: /metrics
interval: 30s
ServiceMonitor 相比傳統方式的優勢:
雖然 ServiceMonitor 需要手動配置,但大部分 Helm Chart 已經準備好選項:
# Chart 內建支援
helm install keda kedacore/keda --set prometheus.operator.enabled=true
# 手動建立(如果 Chart 沒有內建)
kubectl apply -f my-app-servicemonitor.yaml
重要觀念:你需要明確告訴 Prometheus「要監控什麼」,但 Prometheus Operator 會自動處理後續的配置更新。
Grafana 是可視化平台,專門將時序資料轉換成直觀的圖表和儀表板。在監控架構中,Prometheus 負責「存數據」,Grafana 則負責「讓數據好看」。
Grafana 透過 PromQL 查詢 Prometheus 的時序資料,提供豐富的視覺化選項:折線圖展示趨勢變化、熱力圖顯示資源分佈、儀表板呈現即時狀態。更重要的是,它支援告警視覺化、多維度資料鑽取,以及團隊協作功能。
對於 DevOps 團隊來說,Grafana 不只是「看圖表」,更是「發現問題」和「分析根因」的利器。一個設計良好的 dashboard 能讓你在幾秒內判斷系統健康狀況,快速定位效能瓶頸。
一開始我們用的都是內建 dashboard。雖然能看基本 CPU、Memory、Node 狀態,但當我想提升 Node Utilization 時,發現這些圖表根本看不出「Pod 的 request/limit 是否合理」。
於是我寫了 PromQL 查詢,自訂了一張 dashboard:
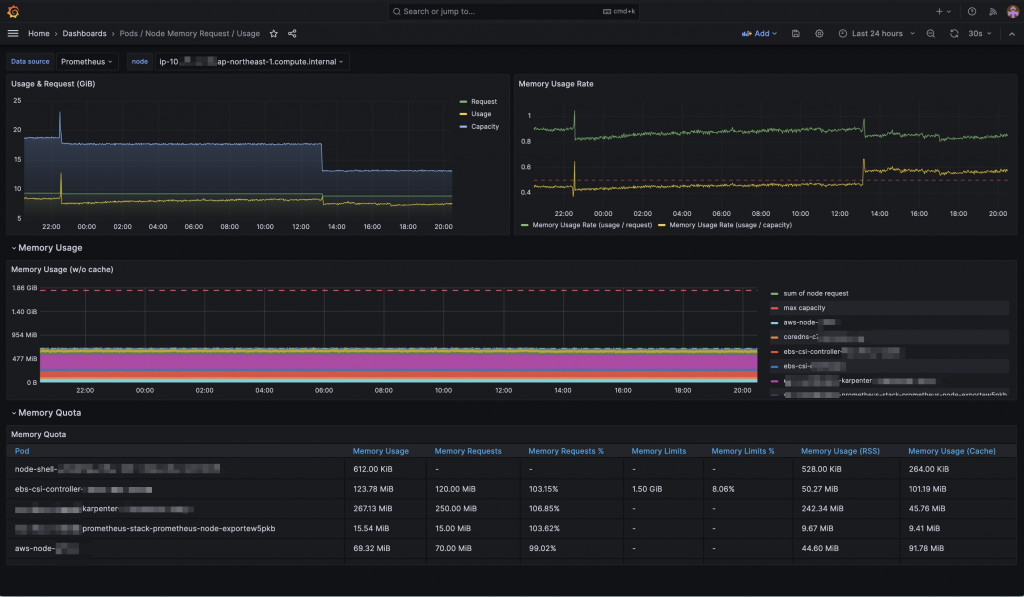
關鍵 PromQL 查詢範例:
# Node Usage vs Request
sum(container_memory_usage_bytes{container!="", container!="POD"})
/
sum(cluster:namespace:pod_memory:active:kube_pod_container_resource_requests)
# Node Request vs Capacity
sum(container_memory_usage_bytes{container!="", container!="POD"})
/
sum(node_memory_MemAvailable_bytes)
這張圖讓我能看出:
調整之後,Node Utilization 提升到 80% 以上,資源使用效率大幅改善。
我們自己包了一個 chart,允許把 JSON 格式的 dashboard 放進 ConfigMap,再由 Grafana 自動載入。
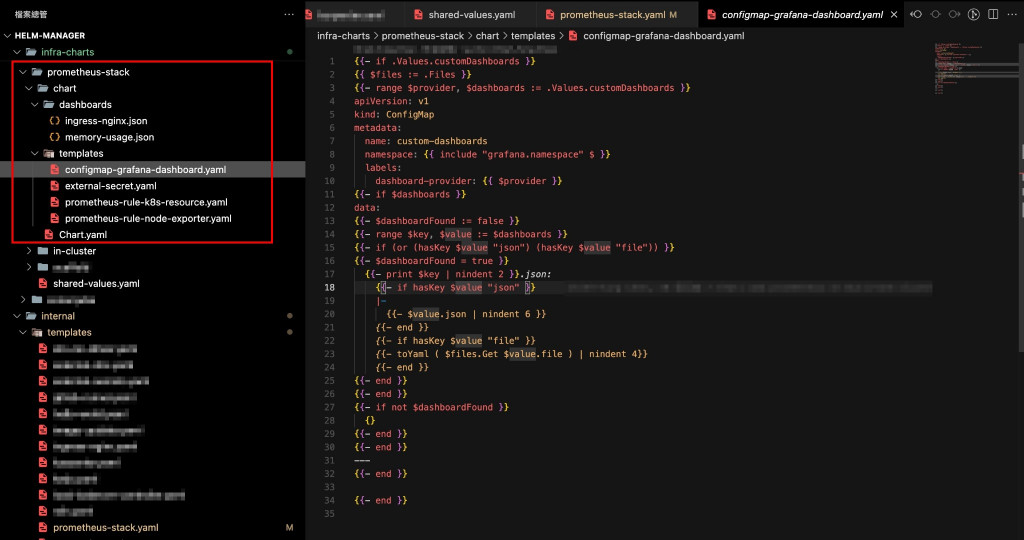
在 Cluster values 加入以下設定:
# https://github.com/grafana/helm-charts/issues/764
customDashboards:
default:
ingress-nginx-board:
file: dashboards/ingress-nginx.json
memory-board:
file: dashboards/memory-usage.json
# add more dashboards here*
這樣做的好處是:
光能「看到」還不夠,還要能「被提醒」。在我們的 Prometheus stack 裡,我們也有設定 Alertmanager,讓告警自動送到 Slack。
重點設定如下:
external_secrets:
- name: slack-webhook
data:
- secretKey: slack-webhook-url
remoteRef:
key: ops-credentials
property: slack_webhook_url
kube-prometheus-stack:
alertmanager:
enabled: true
alertmanagerSpec:
secrets:
- slack-webhook
# https://prometheus.io/docs/alerting/configuration/#configuration-file
config:
route:
routes:
- receiver: 'slack'
matchers:
- severity =~ "warning|error|critical"
receivers:
- name: 'slack'
slack_configs:
- api_url_file: /etc/alertmanager/secrets/slack-webhook/slack-webhook-url
channel: example-internal-notification
send_resolved: true
### 設置送到 slack 的 message title
title: '🚨 [{{ .Status }}] {{ .GroupLabels.alertname }}'
### 設置送到 slack 的 message content
text: |
{{ range .Alerts }}
*Alert:* {{ .Annotations.summary }}
*Description:* {{ .Annotations.description }}
*Severity:* {{ .Labels.severity }}
{{ end }}
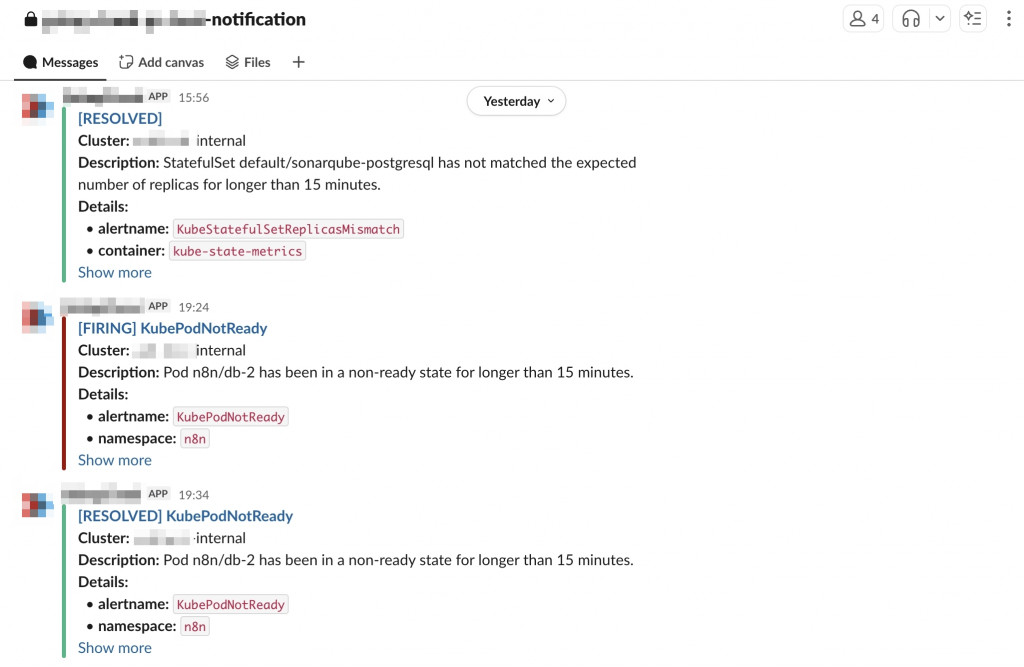
這樣當 Node Down、Pod CrashLoop、資源用量過高時,我們就能在 Slack channel 裡收到通知。
系統會自動針對以下情況發送告警:
我們今天一樣會使用 ApplicationSet 管理 Prometheus stack:
這樣所有 cluster 都能有一致的 Prometheus stack,又能根據需求增加自訂 dashboard 或告警規則。又因為我們希望同時設定好 custom dashboard、方便新增 SSO 及 slack webhook 的 ExternalSecret、以及一些我們預設的 Prometheus Rule CRD,所以特地為 Prometheus Stack 包裝成一個新的 helm chart。因此這張 chart 在部署模式上會像前幾天的 Karpenter 一樣,會把需要同時部署的 CRD 詳細資訊也一併放在 Value files 當中:
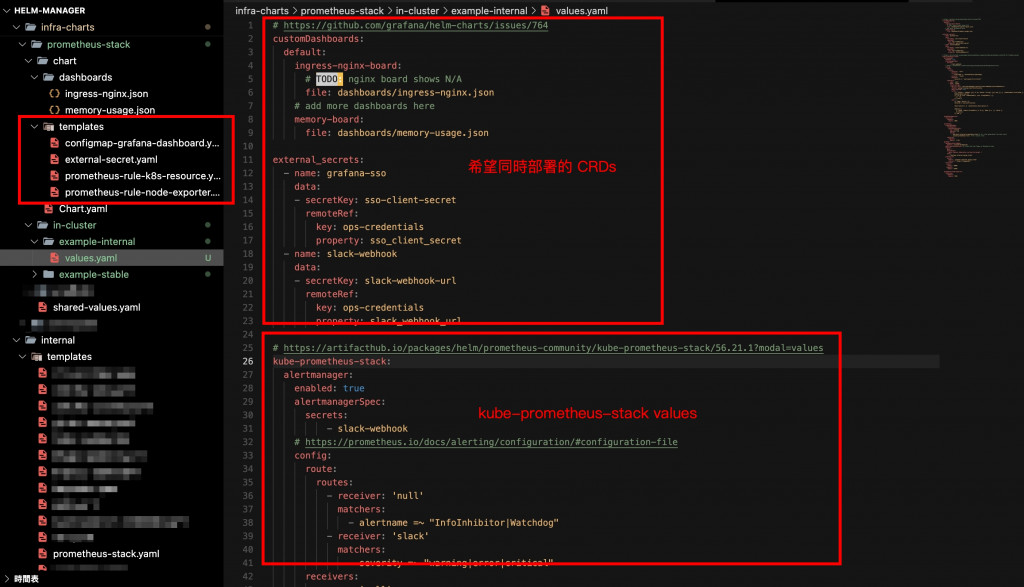
📌 更多參數可參考官方文件:kube-prometheus-stack values.yaml
今天我們透過 Prometheus stack 把監控和告警完整串了起來:
到這裡,我們不只是「看到叢集在動」,而是能主動「被提醒哪裡出問題」。
在 Day 20,我們將轉向另一個話題 —— KEDA (Kubernetes Event-Driven Autoscaler),看看如何透過事件或訊號驅動 workload 自動擴縮。
