在 Day 19 我們談到監控與告警,讓我們可以「看到」叢集發生了什麼事,也能在異常時即時收到提醒。但除了被動監控之外,叢集其實還需要一種 主動調整資源 的能力 —— 這就是 KEDA (Kubernetes Event-Driven Autoscaler) 的價值所在。
在我們的架構中,其實同時存在 Karpenter 和 KEDA 兩種 autoscaler:Karpenter 關注 Node 層級(決定要開幾台 EC2),KEDA 關注 Pod 層級(決定 Deployment 要幾個副本)。兩者搭配能實現從業務事件到基礎設施的 end-to-end 自動化。
今天我們聚焦在 KEDA,深入了解它的核心概念與實作。文章將從 KEDA 與 HPA 的關係開始,接著詳細探討 ScaledObject 的兩階段運作機制(Activation Phase 與 Scaling Phase),並說明如何實現 scale-to-zero 功能。我們也會介紹 KEDA 豐富的 Trigger 生態系統,透過 Cron Trigger 的實戰範例了解具體應用,最後分享如何在多叢集架構中部署和管理 KEDA。
在 Kubernetes 裡,大家最熟悉的自動擴縮機制是 HPA (Horizontal Pod Autoscaler),它根據 CPU、Memory 使用率調整 Pod 副本數。但 HPA 只看「資源使用率」這個角度。
KEDA 則是把 HPA 擴充到「事件驅動」:它透過各種 Trigger 觀察事件來源(Queue 長度、Kafka 訊息數等),當條件達到臨界值時,動態產生或更新 HPA。可以把 KEDA 想像成替 HPA 長出更多感知能力的外掛。
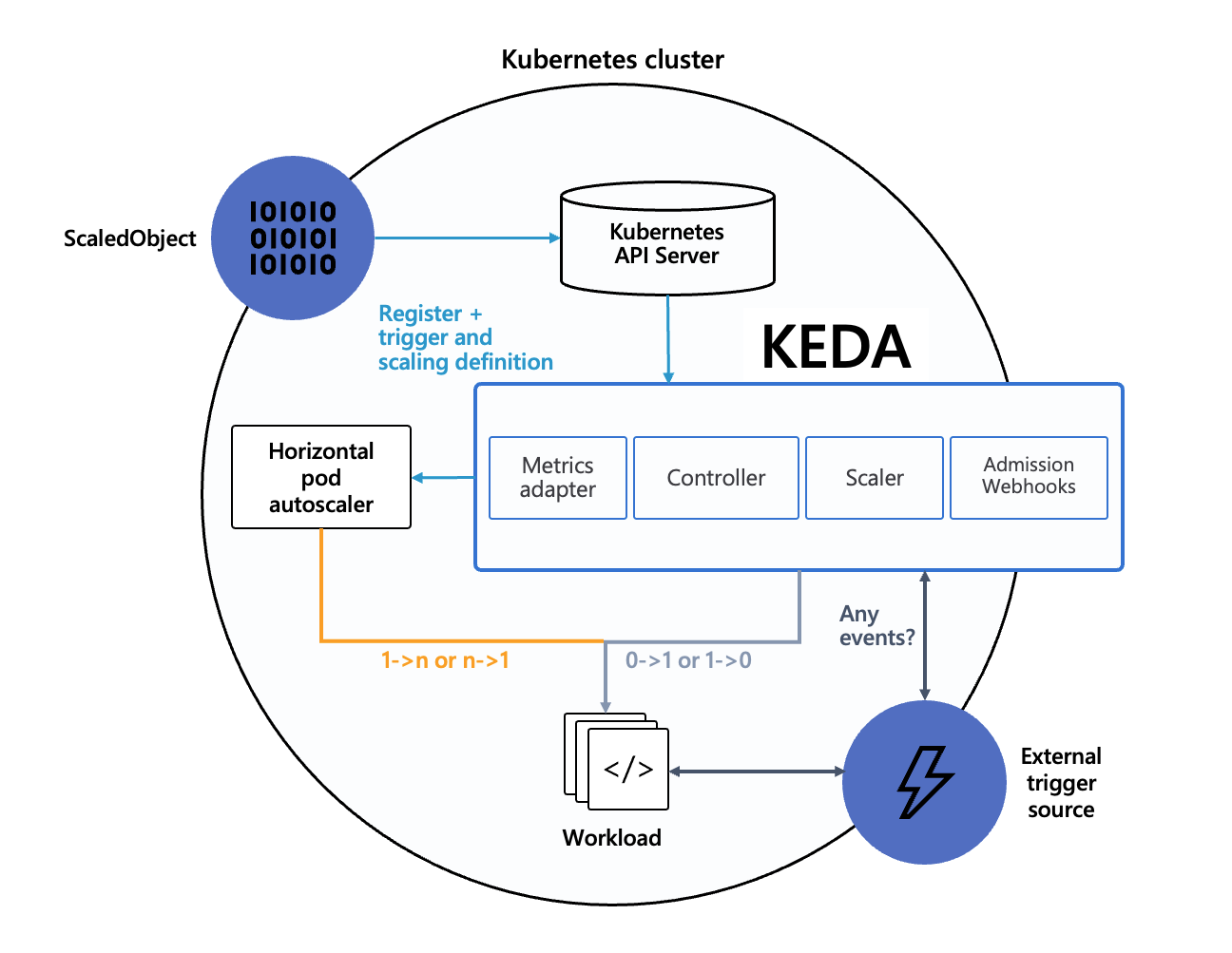
KEDA 的架構圍繞著一個核心概念:ScaledObject。他是 event 和 HPA 的介面,讓我們能透過定義一到多個 event triggers 來操控 HPA,達到 scaling 的效果。概念上分為兩個階段:
會這樣切分是因為 HPA 本身不支援 minReplicaCount = 0。KEDA 部分會取決於 IsActive function 的執行結果,來判斷現在是否要處理 0 → 1 scaling。
根據前面的邏輯,如果要 scale 到 0,必須要讓現狀滿足以下兩個條件:
現狀不符合任何 triggers:若現狀有符合任一個 trigger 條件,KEDA 會把目標 workload 的 replicas 從 0 喚醒到 1,然後交給 HPA 去處理 desired 數量。
minReplicaCount 或 idleReplicaCount 必須設置為 0:接著 KEDA 會 disable HPA,並且直接把 Deployment replica 設置為 0。
minReplicaCountvsidleReplicaCount的差異
minReplicaCount:在 Scaling Phase(有任何 trigger 被觸發時)最小的 replicaCountidleReplicaCount:在 Activation Phase(沒有觸發任何 trigger 時)時的 replicaCount(現在這個值只能是 0,詳見 GitHub Issue)
在這個情況下,儘管我們使用 kubectl 把 replica count 設置成 0 以外的數字,KEDA 還是會在下一輪 polling trigger 時(發現沒有觸發任何 trigger 後),一樣將 replica count 設置為 0。
重要觀念:基本上寫 ScaledObject triggers 要以 scale up 的角度來寫,所有條件都不符合才會 scale down。
因為我們在同個 ScaledObject 裡面可以同時設定一到多個 triggers,幾本上只要現狀有符合任何一個 trigger,那現在這個 ScaledObject 就會處於 Scaling Phase,也就是交由 HPA 來做 scaling。
而在一個 ScaledObject 裡面,所有的 triggers 都會被轉成 HPA 的 metrics(ie, ScaledObject 裡面有五個 triggers,那他長出來的 HPA 就會有五個 metrics)。HPA 會對每個指標各自算出期望副本數,最後取「最大值」作為本輪期望副本數;若有任一指標無法取到數值而其他指標建議縮容,會跳過縮容。
細節可以看 HPA 官方文件的解釋:Horizontal Pod Autoscaling。
概念介紹的最後讓我用流程圖來 sum up KEDA 的完整運作機制:
[Start: KEDA ScaledObject]
│
▼
(1) KEDA 輪詢每個 trigger (pollingInterval)
├─ Trigger A → active 嗎?
├─ Trigger B → active 嗎?
└─ Trigger C → active 嗎?
│
▼
(2) 判斷「是否有任何一個 trigger active?」
├─ 是 → 進入「活動模式 Scaling Phase」
│ │
│ ├─ 如果目前 replicas = 0 → KEDA 直接把目標 workload 設成 ≥1
│ └─ 將所有 triggers 轉換成 HPA 指標 (external metrics)
│ └─ HPA 接管:
│ ├─ 計算每個指標的期望 replicas,取最大值
│ └─ 若計算結果 < minReplicaCount → 強制維持在 minReplicaCount
│
└─ 否 → 進入「非活動模式 Activation Phase」
│ │
│ └─ 有設定 idleReplicaCount ?
│ ├─ 是 → replicas = idleReplicaCount
│ └─ 否 → replicas = minReplicaCount
│ (如果 =0,就縮到 0)
│
▼
(3) 重複下一輪 pollingInterval / HPA syncPeriod
KEDA 支援的事件來源非常多,常見的有:
完整清單可以參考官方文件 👉 KEDA Scalers。
這也是 KEDA 的強大之處 —— 幾乎任何「能被量化的事件」都可以成為伸縮依據。
讓我們看一個實際的例子:
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
name: gitlab-runner-arm-1
namespace: gitlab-runner
spec:
cooldownPeriod: 10
idleReplicaCount: 0
initialCooldownPeriod: 0
maxReplicaCount: 4
minReplicaCount: 0
pollingInterval: 30
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: arm-gitlab-runner-gitlab-runner
triggers:
- type: cron
metadata:
desiredReplicas: "1" *# 如果現況大於 1 且符合 trigger 條件,則不會改變數量*
end: 0 18 * * mon-fri
start: 0 10 * * mon-fri
timezone: Asia/Taipei
效果:週一到週五的 10:00 ~ 18:00,HPA 會確保我們的 replica ≥ 1。超過這些時間段以外,KEDA 會確保我們的 replica = 0。
但是他會直接去把 deployment replica count 改成 0,就算我們手動改成 1 還是會被 KEDA 改回去。解決方法為,暫時讓 KEDA 的 ScaledObject 停止作用:
*# ScaledObject 停止作用*
kubectl annotate scaledobject gitlab-runner-arm-1 autoscaling.keda.sh/paused=true -n gitlab-runner --overwrite
*# 加班完之後 ScaledObject 開始作用*
kubectl annotate scaledobject gitlab-runner-arm-1 autoscaling.keda.sh/paused=false -n gitlab-runner --overwrite
因為 KEDA 是基礎設施的一部分,我們選擇在多個叢集都安裝它。延續 Day 15 Karpenter 和 Day 19 Prometheus Stack 的架構模式,我們的做法是:
在 Helm chart templating 時,會 iterate 這個 list,幫我們自動建立多個 ScaledObject。
*# https://github.com/kedacore/charts/tree/v2.17.2/keda*
keda:
*# -- Kubernetes cluster name. Used in features such as emitting CloudEvents*
clusterName: example-internal
nodeSelector:
usage: system
tolerations:
- key: SystemOnly
operator: Exists
prometheus:
metricServer:
enabled: true
serviceMonitor:
enabled: true
scaledObjects:
- name: gitlab-runner-arm
namespace: gitlab-runner
target:
kind: Deployment
name: arm-gitlab-runner-gitlab-runner
minReplicaCount: 1
maxReplicaCount: 3
triggers:
- type: cron
metadata:
timezone: Asia/Taipei
start: 0 10 * * mon-fri *# At 10:00 AM*
end: 0 18 * * mon-fri *# At 6:00 PM*
desiredReplicas: "2"
- name: gitlab-runner-x86
namespace: gitlab-runner
target:
kind: Deployment
name: x86-gitlab-runner-gitlab-runner
minReplicaCount: 1
maxReplicaCount: 3
triggers:
- type: cron
metadata:
timezone: Asia/Taipei
start: 0 10 * * mon-fri *# At 10:00 AM*
end: 0 18 * * mon-fri *# At 6:00 PM*
desiredReplicas: "2"
和 Karpenter、Prometheus Stack 一樣,因為我們希望在部署 KEDA Helm Chart 的同時一併部署 ScaledObject CRD,所以 values file 才會包含 ScaledObject 的定義。
這樣做的好處是:
KEDA 讓我們的叢集從「資源驅動」走向「事件驅動」的自動化:
透過 ScaledObject 的兩階段機制(Activation Phase + Scaling Phase),KEDA 解決了 HPA 無法縮放到 0 的限制,讓我們能實現真正的 serverless 體驗。配合豐富的 Trigger 生態系統,幾乎任何可量化的事件都能成為擴縮依據。
在 Day 21,我們將轉向另一個重要主題 —— CI/CD 流程的建構,看看如何在我們的 GitOps 架構中實現自動化的持續整合與部署。

