從一個小故事說起:
圖片來源:透過觸覺感測器訓練,人形機器人可處理精密的小型零件。(來源:Mercedes-Benz)
從前有一座忙碌的工廠,叫做「齒輪廠」。齒輪廠裡有許多工人,他們日夜操控機器手臂,把零件一個一個裝好、檢查、包裝。一天,廠長心想:如果有一個像人一樣的幫手,不但會走路、會抓東西,還會看、會聽、會感知,那工作會變得更輕鬆、安全嗎?
於是,工程師團隊帶來了「小人」,一台人形機器人。小人的外殼像人有頭、有手、有兩條腿,但真正厲害的不是外表,而是它「身上的五官」——也就是各式各樣的感測器。
小人有一雙眼睛(高解析度相機與 3D 感測器),能看到貨架上每一個不同尺寸的零件;它有耳朵(多個麥克風),能聽出機械運轉的異常聲音;它的雙手裝了壓力感測器,摸到易碎物品會自動放輕力道;胸口有 LiDAR 幫它安全避開路上的人和叉車;內部還有陀螺儀和加速度計,讓它在被碰撞後仍能保持平衡。
這一切看起來很理想,但工程師們很快發現,要讓小人穩定工作,並不只是把零件塞滿就好,還得解決三個真正的挑戰:
第一是「系統整合」。把視覺、觸覺、語音、動作控制、電源管理、通訊模組都塞進一台機器裡,還要讓它們彼此協調,工程師得像指揮家一樣調度每個元件,確保延遲、頻寬與電力都在可接受範圍內。
第二是「可靠性」。機器人要可能一天 24 小時運作,馬達、感測器、軟體每個零件都不能常常壞;所以系統需要遠端監控、預測性維護,發現溫度飆升或震動異常就先預警,而不是等故障發生才修。
第三是「成本」。目前一台完整的人形機器人價格還不便宜,初期投資需要評估 ROI(投入產出),所以設計時要在效能與成本之間做平衡,選對核心感測器、挑最需要的功能先上線。
即使面臨挑戰,齒輪廠很快看見回報。小人可以接替重複、危險、長時間的搬運工作;遇到異常聲音能立刻通知維修;在夜間巡檢時能把畫面與振動記錄回傳資料中心,減少停機時間。更重要的是,小人能和人協同工作:人負責需要判斷與創意的任務,機器人則負責精確、重複與危險的工作。
這個故事還有更大的篇章。在另一片領域,科學家把衛星影像和 LiDAR(光達)放到一起做地表語義分割——也就是把地表的「每一塊土地」標註成樹、房屋、道路、河流等。就像小人把視覺與觸覺合併判斷,遙感研究者把不同感測器資料融合,解決單一來源無法判別的複雜場景。這告訴我們:多感測器融合的威力,不只在工廠,在醫療、智慧城市與環境監測都能發光。
市場面上,分析師也在看這場變化。隨著晶片更強、感測器更便宜、AI 演算法更成熟,投資人與企業把目光投向能結合感測與智慧的系統。大廠們(像是 Tesla、Boston Dynamics、Figure AI)把人形或移動機器人做為長期戰略,顯示這不是一時的技術噱頭,而是產業布局的一部分。
故事的尾聲,廠長在一次早會上說了一句話:「我們不用擔心被機器取代,而應該思考如何讓機器把重複性工作做掉,讓人去做有價值的判斷。」工程師微笑點頭,因為他們知道:真正成功的自動化,是人與機器互補的未來。
隨著物聯網(IoT)與人工智慧(AI)的發展,情感偵測(Affective Computing)成為智慧人機互動的核心議題。本文以技術角度出發,探討從 感測器數據採集 → 類比轉數位(ADC) → 前處理 → 多模態 AI 融合(Late Fusion) 的完整流程,並結合教育、醫療、交通等場域的實務應用,分析未來挑戰與發展方向。
在 IoT 架構下,感測器扮演「數據入口」的角色,負責將物理訊號轉換為電信號。常見模態包含:
視覺感測(Vision Sensor):CMOS / CCD 攝影機 → 影像像素矩陣
聲音感測(Acoustic Sensor):麥克風 → 聲音波形
生理感測(Physiological Sensor):心率、皮膚導電反應(EDA)→ 生理訊號
此階段對應於人類的「感官」,為後續 AI 提供多模態數據基礎。
多數感測器輸出為類比訊號(Analog),需透過 類比轉數位轉換器(ADC)處理:
聲音:連續波形 → 取樣 → PCM 編碼(形成 .wav 格式)
影像:光強度 → 電壓變化 → RGB 數值矩陣
生理:心跳電壓訊號 → 數字化的 HRV(Heart Rate Variability)
此步驟確保 IoT 設備能將物理訊號標準化,進入數位計算領域。
數據經 ADC 轉換後,仍需進一步清理與特徵萃取:
(1)濾波(Filtering):降噪(語音訊號處理)、影像去模糊
(2)正規化:數據縮放至統一範圍(0–1)
(3)特徵擷取:
臉部關鍵點(Face Landmarks, e.g., 68-point model)
聲音頻譜特徵(MFCCs, Spectrogram)
這一層對應於 IoT 的邊緣運算(Edge Computing),能減少傳輸負擔並提升即時性。
在情感偵測任務中,單一模態(例如表情或語音)易受雜訊影響。Late Fusion提供更好的解決方案:
視覺模態:CNN / MLP 將臉部影像轉換為 logits_v
聲音模態:LSTM / MLP 將聲音特徵轉換為 logits_a
融合層:將 logits_v + logits_a 拼接,輸入分類器得到最終情緒判斷
數學形式可表示為: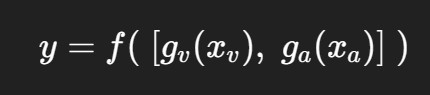

-教育科技
智慧教室中,AI 結合臉部與聲音 → 偵測學生專注度、困惑度 → 提供教師即時回饋
-醫療與長照
結合臉部表情、聲音與心率 → 偵測老人憂鬱或焦慮 → 及早介入
-智慧客服
分析顧客語調與臉部表情 → 判斷情緒狀態 → 提醒客服調整溝通策略
-智慧交通
車內攝影機 + 麥克風 → 偵測駕駛疲勞或焦躁 → 自動觸發警示或輔助駕駛
延伸案例:在遙感領域,研究者結合多光譜影像 + LiDAR 做地物語義分割(Semantic Segmentation),有效解決地景複雜與類別不平衡問題。此案例顯示多模態技術不僅適用於情感偵測,也能應對複雜的地理空間任務。
根據 Mordor Intelligence 報告【來源】:
全球多模態 AI 市場 2025 年規模約 29.9 億美元
預計 2030 年將成長至 108.1 億美元
CAGR 約 29.29%,亞太地區為增速最快市場
產業應用集中於 醫療、教育、零售 / 電商,顯示多模態 AI 在 IoT 場景具高度商業潛力。
AI 情感偵測結合 IoT,形成「感測器 → ADC → 前處理 → 多模態融合 → 應用」的閉環體系。此技術不僅提升人機互動體驗,更在教育、醫療、客服與交通領域展現廣泛應用前景。
IoT 是 AI 的數據入口,多模態融合是 AI 的理解力,而人類智慧則是最終決策的核心,未來,AI 將不僅是工具,而是人類「感官的延伸」,協助我們更全面地感知與理解世界。
 abc11032203
abc11032203
