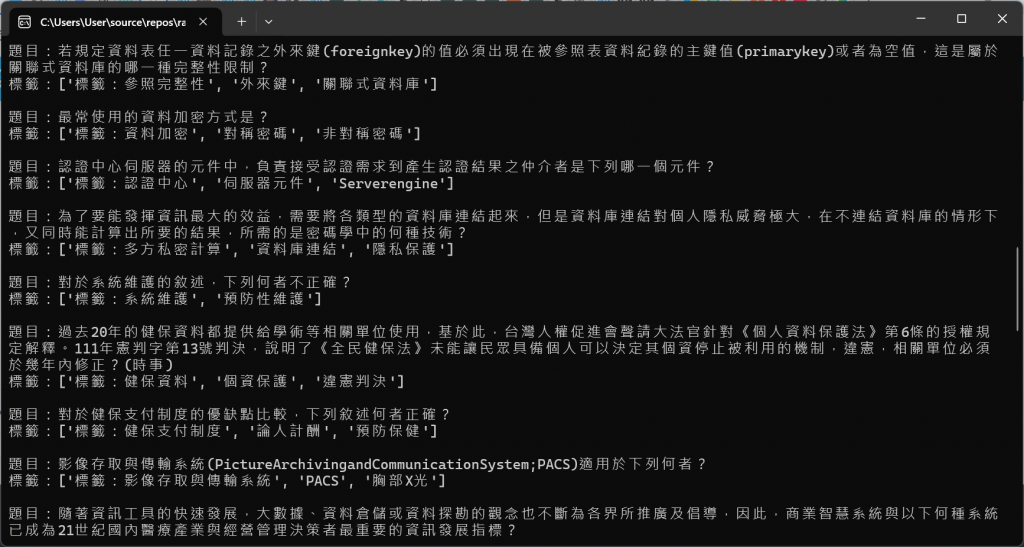
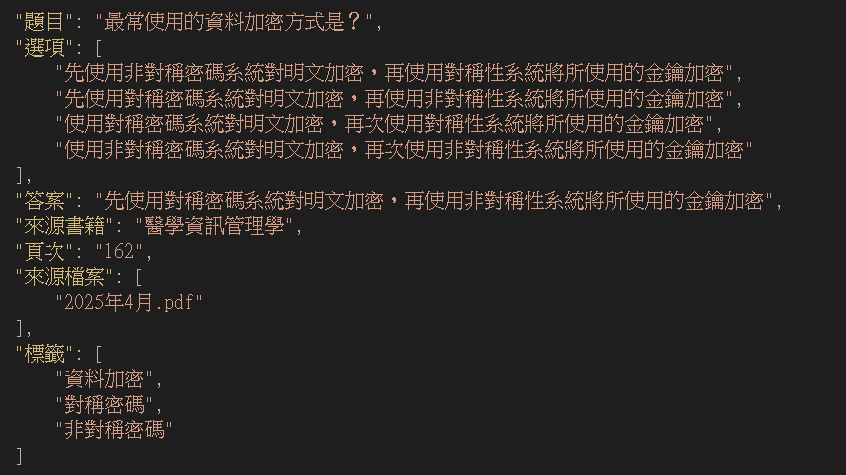
為什麼要給題目加上標籤?因為在複習時,我們不一定能記得所有的題目、專有名詞,但是給題目加上標籤後,我們就可以以標籤來做為搜尋條件,快速找到相關題目。標籤還能用來追蹤錯題的類型,讓我們更容易了解自己不懂的是哪些部分。
一般情況下,如果想要自動生成題目的標籤,想要準較高的確度,需要先進行大量人工標註,建立好訓練資料,再透過模型進行分類或標籤生成。但這樣的流程不僅耗時,還需要持續更新與維護資料集,不一定能在這次鐵人賽完成,所以這次我選擇讓ai根據題目來提取標籤。
API key獲取
這次選用mistral模型,先到 mistral 官網創建帳號,創建完後在下圖位置申請api key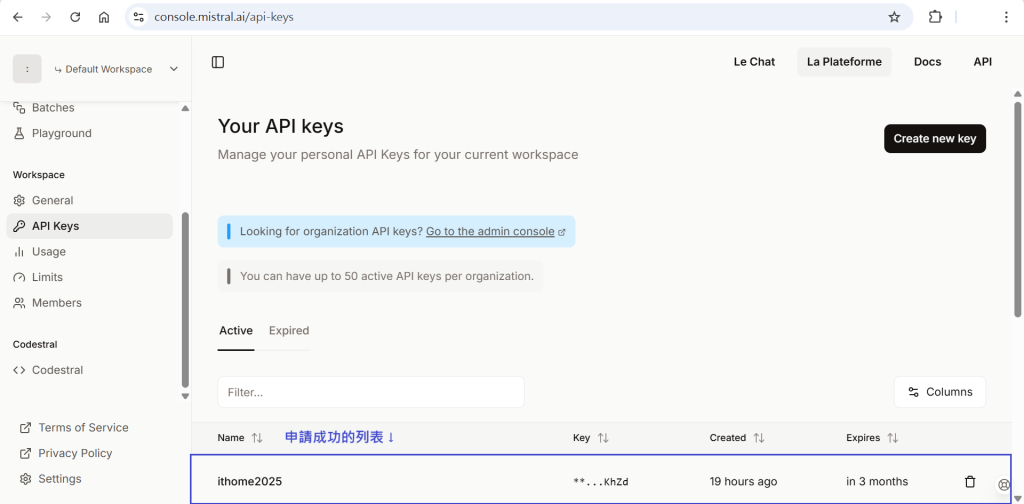
在環境變數中加入MISTRAL_API_KEY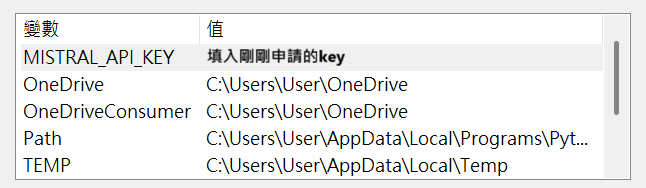
找到官方範例,換上需要的提示詞
# 讀取題目、答案,準備加入提示詞
file_path = os.path.join( " json檔路徑 " )
with open(file_path, 'r', encoding='utf-8') as f:
questions = json.load(f)
for item in questions:
question = item['題目']
answer = item['答案']
prompt = f"""
你是一個標籤生成助手。根據提供的題目和答案,請從提供的「題目」和「答案」中,提取1到3個最能代表主題的繁體中文關鍵字。
範例:
題目:白血病又稱血癌,是鄉土劇中常見的生病橋段。主因骨髓造血細胞產生不正常增生,進而影響骨髓造血功能的惡性疾病。『白血病』的英文是?
答案:Leukemia
標籤:白血病、血癌
現在,請生成以下內容的關鍵字:
題目:{question}
答案:{answer}
標籤:
"""
keywords = chat_response.choices[0].message.content.strip().replace('標籤:', '')
item['標籤'] = keywords.split('、')
except Exception as e:
print(f"在處理題目 '{question}' 時發生錯誤:{e}")
continue
# 存檔
output_file_path = os.path.join( " json檔路徑 " )
with open(output_file_path, 'w', encoding='utf-8') as f:
json.dump(questions, f, ensure_ascii=False, indent=4)
print(f"\n所有標籤處理完成,已成功儲存至 {output_file_path}")
最後執行一下測試,大功告成!