
直到今天之前,都在討論的是一個純聊天的模型,也就是說,透過文字一來一往的與模型聊天。但現在很多模型不只是聊天,還能上網搜尋、寫程式實際更動你的程式碼、甚至操作你的瀏覽器進行訂票、摘要社群媒體等等操作。
這樣的模型在按下 Enter 後發生了什麼事呢?
如果要讓 LLM 做到聊天以外的事,泛指讓 LLM 有達成人類除了對話任務外,其他任務的能力。對話任務與其他任務不同,這代表著對於 LLM 來說他將面臨更複雜的環境,不只是一個聊天視窗、他需要執行的動作也可能超出模型的能力。但如果能做到這些,就是現在所說的 AI Agent。
AI Agent 怎麼達成人類的任務呢?回歸到任務的本質,得先讓 LLM 了解今天如果拿到一個任務,人會怎麼去達成任務,並變成一步步系統可以執行的架構出來。
當人今天有一個目標需要執行時,通常第一步驟會先瞭解需求,並進一步規劃接下來該怎麼做。更深入地說,規劃是目標中的任務分解,將任務分解變成一系列可管理的行為。
LLM 要能夠瞭解你輸入的任務意圖,這一塊可以是一個意圖分類器來協助核心 LLM 做到也可以是 LLM 本身來做。接著基於此意圖下,生成複數個規劃,並對不同規劃搜尋哪一個是最合適的。
不同規劃中,可以透過經驗法則去剔除,也可以透過一些 Checklist e.g. 是否步驟太多、是否不包含核心動作來剔除,又或者直接讓另一個 AI 去評斷這個規劃是否合理。規劃的生成也可以由大至小,例如:如果要規劃一整天的行程,可以先規劃每個小時的目標,再進一步規劃每小時中每 15 分鐘的目標,再進一步收斂到每 5 分鐘的具體行為等等。
簡言之,在給 LLM 一個目標並按下 Enter 之際,也是由系統發一個 prompt 告訴 LLM:應基於使用者提出的目標規劃,告訴 LLM 說有哪些工具可以被使用、工具會接受什麼樣的資訊進來、並遵守下列好的規劃的原則,期待產生出一系列可執行的動作,以及一個範例,就跟前一篇文所說的好的 prompt 的原則相似,只是現在這些被系統完成了,不需要由人類自行提出這麼詳細的規劃 prompt。
Agent 能夠執行什麼,會跟它的工具庫有關。一種工具庫是知識增強類,透過外部的資料庫、API 類型去取得模型原本不知道的資料。另一種是能力增強類,讓 Agent 做到他原本不擅長的事情,例如,寫程式、計算,或找更擅長做其他事情的模型,像是找擅長圖像生成的模型來處理這類問題。同時工具庫也可以設定要接收什麼參數,甚至可以要求是否是必要使用工具、選用或需要跟其他工具搭配等等。
甚至我們可以給予模型更大的權限,讓他不只是產生出更貼近我們希望看到的資訊結果,甚至還包含直接去更動我們的現實世界,像是讓 AI Agent 直接操作我們的瀏覽器去訂票、寫 Email 甚至寫資料進資料庫。
對於 Agent 來說,會面臨的挑戰是,要選擇什麼樣的工具組合來達成目的,甚至是否能讓 Agent 即時產生出一個更適合解決問題的工具,都是 Agent 發展的未來可能性。
最終 Agent 要能夠發現自己的錯誤,甚至進一步從錯誤中成長而不只是一錯再錯。這又涉及到對目標達成狀況的評估,以及如何記憶重要的錯誤經驗來作為反思。
這個過程也不一定要是上述流程的最後一步,在拆解的每一小步中都可以執行這個步驟,例如,評估規劃是否合理、評估每一個步驟方向是否正確。同時這個步驟也不一定要同一個代理來做,可以是多代理分工,一個負責規劃跟行動、一個負責評估。
也可以將評估再進一步拆解成兩種,一種評估結果本身多好,一種評估錯誤原因,讓反思更細緻。而這些反思都可以再做為下一次規劃的上下文,提供 Agent 更周全的規劃角度。
AI Agent 在面臨更加複雜的環境,失敗的機率肯定遠比一個純對話 LLM 還要來得高,現今 AI Agent 常見的失敗原因在不同階段都有可能發生,例如,在規劃階段,產生了不存在工具的規劃、或傳入了工具無法使用的參數。又例如,正確了使用工具,但工具產出錯誤的結果,因為 AI Agent 沒有將 prompt 轉譯為正確的操作指令給工具。甚至規劃本身效率奇差無比,就算步驟執行都是對的那可能還不如人類自己來做。
人類的任務百百種,現在最前沿與吸睛的不外乎是幾乎能全自動處理我們日常瑣事的 Agent 像是操作電腦介面、甚至搭配人形機器人來做飯、做家務,但其實 Agent 並不是近一年才冒出的概念,在更早知識增強領域,就有 RAG 架構,來解決模型最擅長的知識翠取領域文提。
從前幾篇文可以得知,模型的訓練成本極高,模型每重新訓練一次都需要極大量的硬體資源來支撐。但資訊日新月易,更甚者,有些資訊並不存在於網際網路上,可能是個人或企業資料庫,像這種時候難道每個人或每間公司都要重新訓練一個自己的模型來使用嗎?
RAG 就是一個為了解決此問題的架構,RAG 全名又叫做 Retrieval-augmented generation,這個架構讓每一次問 LLM 一個他不知道的問題時,都可以自動的去抓有關的資料,去補全相關知識在模型的上下文中。
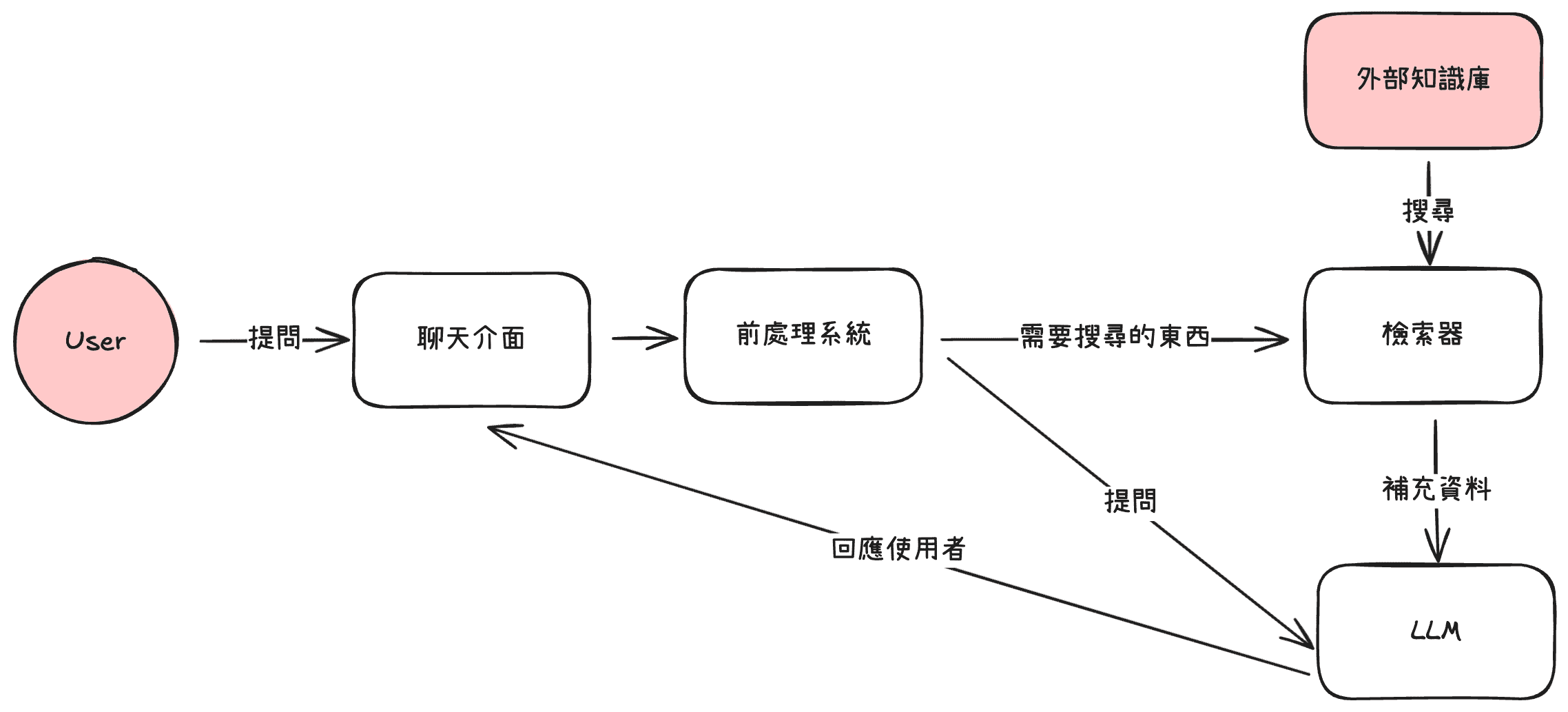
例如:公司在處理某某客服問題時,都怎麼處理的?當在對話框按下 Enter 之際,假設如果是一個開源訓練好的 LLM 也不知道啊。但在 RAG 架構的設計下,這時他就可以去調用檢索器,讓檢索器搜尋公司資料庫,並補上相關的 FAQ 給 LLM 一起詢問相關問題,這樣 LLM 就能回復你更正確的作法。
怎麼找到有關的資料並提供給 LLM 是 RAG 核心 - 檢索器的職責,這個議題也不是近幾年才有,早在好幾年前,電商、廣告等領域就已經在處理此「推薦」問題。最常見的檢索器機制有基於搜尋詞的出現頻率以及我們前幾篇提到過的 Embedding 相似度來檢索。
基於詞頻的,可以從搜尋的句子中,其中句子中的所有字,出現在一個文件中幾次與出現在所有文件中幾次來交叉算出一個分數:在一個文件中可以看到特定字詞,代表這文件與字詞有關。但如果一個字詞在所有文件都會出現,有可能這個字詞特別不重要 e.g. 介系詞。而這就是最有名的 TF-IDF 演算法。這類型的算法還可以根據文件長度再做一些校正,但這類算法既便宜、也已經相當成熟廣泛用在我們的生活之中。缺點是對於一些組合字、或會隨著不同脈絡有不同含意的字詞準確路比較差。
為了在特殊情境中有更精準的搜尋結果,後來又有基於 Embedding 的,也就是前幾篇文中有提到的,將文字轉為一組編碼,此編碼代表數學上的考量過前後文後的文字意義。所以更精準的檢索器,會將文件先透過 Embedding 模型,將文件轉為一組編碼,放到編碼資料庫,當今天需要檢索時,則是從編碼資料庫中取得對應的編碼。
也不是說今天檢索器就一定要二選一的使用,甚至可以組合不同的檢索器,來增加檢索效率,像是先透過基於詞頻的搜尋查出一些相關文件後,再使用基於 Embedding 的檢索器再檢索。又或者這些檢索器可以平行進行,最後在對這些檢索成果打分數,選擇出總分最佳的前幾名。
但要選擇什麼樣的檢索器,除了成本、效能、在表現上會考量到的最重要兩個指標就是:準確度與召回率。準確度指的是,搜尋出的文件中,有相關的文件佔比多少,召回率則視指,所有真正相關的文件,有抓回且相關的有多少。透過這些指標,也有助於選擇什麼樣的檢索策略。
在研究 Agent 議題時,比起 Agent 能做到的事,更驚訝於 Agent 做事的方式有多高度模仿人類。當時最令我印象深刻的是一篇 Generative Agents: Interactive Simulacra of Human Behavior 的 Paper,在很久以前這篇 Paper 剛出的時候,在網路上還有許多社群貼文分享提到一個 Lab 讓一群 AI 村民住在一起好幾天,當時的焦點是:「wow AI 村民住在一起好有趣」,事隔幾年回過頭來看這篇 Paper 才發現精華之處是怎麼讓村民做到人類一天的事,從給予人設、規劃一天的行程、怎麼捕捉到周遭的觀察、這些觀察、行程的執行最後怎麼總結為反思,並成為下一個規劃的糧食。
仔細想想,搞不好自己都還沒有 AI Agent 那麼有紀律的反思 XD 或樂觀一點想,也許我有,但從來沒有明確化到像 AI Agent 那樣的程度。而這也是研究 AI 領域的樂趣之一,從 AI 的設計中取經。

 iThome鐵人賽
iThome鐵人賽