到目前為止,我們已經:
但是,光有實驗記錄還不夠。
👉 我們需要一個 模型倉庫 (Model Registry),來管理不同版本的模型,並控制它們的狀態:
今天的目標:
mlflow.pyfunc 封裝模型。mlflow.pyfunc.log_model 註冊到 MLflow Registry。MlflowClient 控制模型版本與狀態。在 python-dev 容器中建立檔案:
notebooks/day11_model_registry.ipynb
這個 Notebook 將包含以下流程:
import os
import pandas as pd
DATA_DIR = "/usr/mlflow/data"
anime = pd.read_csv(os.path.join(DATA_DIR, "anime_clean.csv"))
ratings_train = pd.read_csv(os.path.join(DATA_DIR, "ratings_train.csv"))
ratings_test = pd.read_csv(os.path.join(DATA_DIR, "ratings_test.csv"))
print("Anime:", anime.shape)
print("Train:", ratings_train.shape)
print("Test:", ratings_test.shape)
從訓練集計算「最受歡迎的前 10 部動畫」:
anime_stats = (
ratings_train.groupby("anime_id")
.agg(avg_rating=("rating", "mean"),
count=("rating", "count"))
.reset_index()
)
# 過濾掉評分數太少的動畫
anime_stats = anime_stats[anime_stats["count"] > 50]
# 取 Top-10
top10 = anime_stats.sort_values(
["avg_rating", "count"], ascending=[False, False]
).head(10)
top10_ids = top10["anime_id"].tolist()
top10_titles = anime[anime["anime_id"].isin(top10_ids)]["name"].tolist()
print("Top-10 Anime:", top10_titles)
mlflow.pyfunc 與 PythonModel)這裡我們第一次用到 MLflow 的 pyfunc API。
mlflow.pyfunc:讓你用 Python 方式封裝任意模型,方便後續在不同環境載入與推論。mlflow.pyfunc.PythonModel:一個抽象類別,只要繼承並實作 predict 方法,就能把任何邏輯轉換成 MLflow 模型。import mlflow.pyfunc
class PopularTop10(mlflow.pyfunc.PythonModel):
def __init__(self, df, top10_ids):
self.df = df
self.top10_ids = top10_ids
# 這裡的 predict 就是未來 API 推薦會呼叫的方法
def predict(self, context, model_input):
return self.df[self.df["anime_id"].isin(self.top10_ids)]["name"].tolist()
mlflow.pyfunc.log_model)mlflow.pyfunc.log_model:將模型與 artifacts 一起存到 MLflow,並且(如果指定 registered_model_name)會直接放進 Model Registry。mlflow.pyfunc.load_model 就能在任何環境載入。import mlflow
from mlflow.tracking import MlflowClient
mlflow.set_tracking_uri("http://mlflow:5000")
mlflow.set_experiment("anime-recsys-model-registry")
with mlflow.start_run(run_name="popular-top10") as run:
# 紀錄參數與評估指標
mlflow.log_param("model_type", "PopularTop10")
mlflow.log_metric("avg_rating_mean", top10["avg_rating"].mean())
mlflow.log_metric("min_count", top10["count"].min())
# 註冊模型到 Registry
mlflow.pyfunc.log_model(
artifact_path="model",
python_model=PopularTop10(anime, top10_ids),
registered_model_name="AnimeRecsysModel"
)
執行後,在 MLflow UI → Models 可以看到:
AnimeRecsysModel / Version 1 → PopularTop10 baseline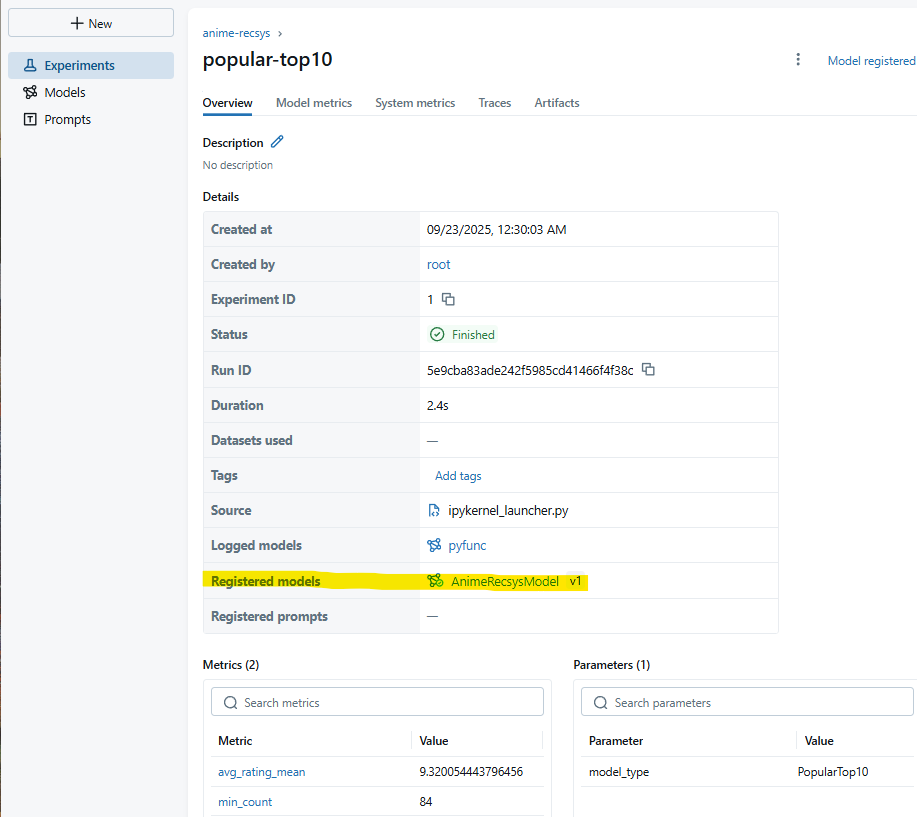
MlflowClient)MlflowClient:MLflow 的程式化 API,可以查詢、刪除、切換模型版本。client = MlflowClient()
# 把 Version 1 升級到 Staging
client.transition_model_version_stage(
name="AnimeRecsysModel",
version=1,
stage="Staging"
)
AnimeRecsysModel v1 進入 Staging 狀態。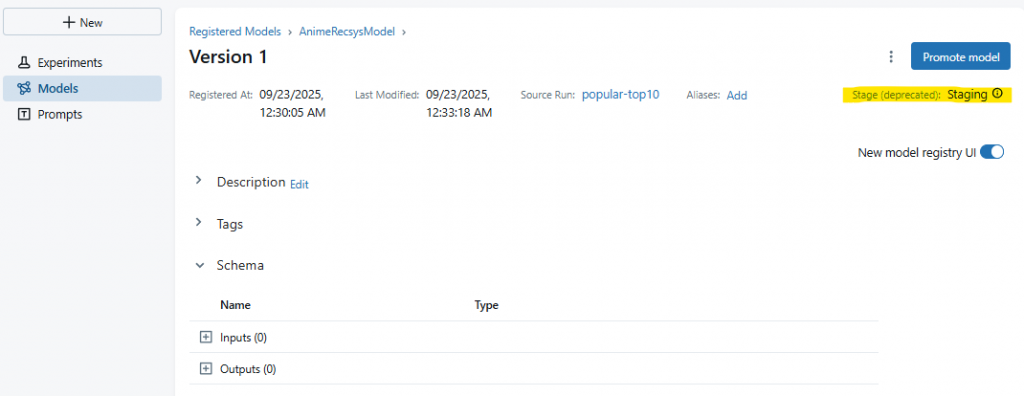
ratings_train.csv → 計算 Top-10 baseline
│
▼
[ mlflow.pyfunc.PythonModel ]
│
▼
mlflow.pyfunc.log_model → MLflow Registry
│
▼
MlflowClient 控制版本
今天我們第一次使用了幾個關鍵 API:
mlflow.pyfunc:MLflow 的 Python function API,能讓任意 Python 模型符合 MLflow 的標準格式。mlflow.pyfunc.PythonModel:用來自訂模型邏輯,只要實作 predict() 就能讓 MLflow 接管推論。mlflow.pyfunc.log_model:把自訂模型存到 MLflow,並可直接註冊進 Registry。MlflowClient:MLflow 的程式化控制介面,能修改模型版本狀態(Staging、Production、Archived)。👉 有了 Registry,我們就能清楚知道:
下一步(Day 12),我們將用 Optuna 自動搜尋最佳參數,並讓 Registry 自動更新最佳模型。


 iThome鐵人賽
iThome鐵人賽