前 9 天,我們的 baseline 模型(User-based CF、Item-based TF-IDF)都是在 Notebook 裡執行的。
但 Notebook 有一些缺點:
👉 今天我們要用 MLflow Projects 把實驗流程封裝:
MLproject 定義 entry points。mlflow run 直接執行。MLFLOW_TRACKING_URI,讓結果自動寫入 MLflow server。.
├── src/
│ ├── train_user_based.py
│ ├── train_item_based.py
├── MLproject
├── conda.yaml # 可選,用於團隊共享,本次先以docker容器空間來示範,不使用conda
name: anime-recommender
entry_points:
user_based:
parameters:
top_k: {type: int, default: 10}
command: "python src/train_user_based.py --top_k {top_k}"
item_based:
parameters:
top_k: {type: int, default: 10}
command: "python src/train_item_based.py --top_k {top_k}"
這樣我們可以用一行指令跑不同模型。
如果團隊要共享環境,可以保留 conda.yaml。
但因為我們使用 本地 pip 環境,執行時會用 --env-manager local,不需要 conda。
name: anime-recommender-env
channels:
- defaults
- conda-forge
dependencies:
- python=3.10
- pip
- pip:
- mlflow==2.14.1
- pandas==2.2.1
- numpy==1.25.2
- scikit-learn==1.4.1.post1
src/train_user_based.py)import argparse
import os
import pandas as pd
import numpy as np
import mlflow
from sklearn.neighbors import NearestNeighbors
DATA_DIR = "/usr/mlflow/data"
def main(top_k):
anime = pd.read_csv(os.path.join(DATA_DIR, "anime_clean.csv"))
ratings_train = pd.read_csv(os.path.join(DATA_DIR, "ratings_train.csv"))
ratings_test = pd.read_csv(os.path.join(DATA_DIR, "ratings_test.csv"))
# 使用者-動畫矩陣
user_item_matrix = ratings_train.pivot_table(
index="user_id", columns="anime_id", values="rating"
).fillna(0)
# 建立 KNN 模型
knn = NearestNeighbors(metric="cosine", algorithm="brute", n_neighbors=6, n_jobs=-1)
knn.fit(user_item_matrix)
sample_users = np.random.choice(ratings_train["user_id"].unique(), 50, replace=False)
precisions, recalls = [], []
rec_records = []
for u in sample_users[:5]: # 只輸出 5 位使用者的推薦清單
if u not in user_item_matrix.index:
continue
user_vector = user_item_matrix.loc[[u]]
_, indices = knn.kneighbors(user_vector, n_neighbors=6)
neighbor_ids = user_item_matrix.index[indices.flatten()[1:]]
neighbor_ratings = user_item_matrix.loc[neighbor_ids]
mean_scores = neighbor_ratings.mean().sort_values(ascending=False)
seen = user_item_matrix.loc[u]
seen = seen[seen > 0].index
rec_ids = mean_scores.drop(seen).head(top_k).index
recs = set(rec_ids)
user_test = ratings_test[ratings_test["user_id"] == u]
liked = set(user_test[user_test["rating"] > 7]["anime_id"])
if len(liked) == 0:
continue
hit = len(recs & liked)
precisions.append(hit / top_k)
recalls.append(hit / len(liked))
rec_records.append({
"user_id": u,
"liked_in_test": anime[anime["anime_id"].isin(liked)]["name"].tolist(),
"recommended": anime[anime["anime_id"].isin(rec_ids)][["anime_id","name"]].to_dict(orient="records")
})
mean_precision = np.mean(precisions) if precisions else 0
mean_recall = np.mean(recalls) if recalls else 0
# MLflow logging (由 mlflow run 自動管理 run)
mlflow.log_param("model", "user_based_cf")
mlflow.log_param("sample_users", 50)
mlflow.log_param("top_k", top_k)
mlflow.log_metric("precision_at_10", mean_precision)
mlflow.log_metric("recall_at_10", mean_recall)
# 推薦清單 CSV
df_examples = pd.DataFrame(rec_records)
out_path = os.path.join(DATA_DIR, "user_based_examples.csv")
df_examples.to_csv(out_path, index=False)
mlflow.log_artifact(out_path, artifact_path="recommendations")
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument("--top_k", type=int, default=10)
args = parser.parse_args()
main(args.top_k)
src/train_item_based.py)import argparse
import os
import pandas as pd
import numpy as np
import mlflow
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.metrics.pairwise import linear_kernel
DATA_DIR = "/usr/mlflow/data"
def main(top_k):
anime = pd.read_csv(os.path.join(DATA_DIR, "anime_clean.csv"))
ratings_train = pd.read_csv(os.path.join(DATA_DIR, "ratings_train.csv"))
ratings_test = pd.read_csv(os.path.join(DATA_DIR, "ratings_test.csv"))
# TF-IDF
anime["text"] = anime["genre"].fillna("") + " " + anime["type"].fillna("")
tfidf = TfidfVectorizer(stop_words="english")
tfidf_matrix = tfidf.fit_transform(anime["text"])
cosine_sim = linear_kernel(tfidf_matrix, tfidf_matrix)
indices = pd.Series(anime.index, index=anime["anime_id"]).drop_duplicates()
sample_users = np.random.choice(ratings_train["user_id"].unique(), 50, replace=False)
precisions, recalls = [], []
rec_records = []
for u in sample_users[:5]:
user_ratings = ratings_train[ratings_train["user_id"] == u]
liked = user_ratings[user_ratings["rating"] > 7]["anime_id"].tolist()
if len(liked) == 0:
continue
sim_scores = np.zeros(cosine_sim.shape[0])
for anime_id in liked:
if anime_id in indices:
idx = indices[anime_id]
sim_scores += cosine_sim[idx]
sim_scores = sim_scores / len(liked)
sim_indices = sim_scores.argsort()[::-1]
seen = set(user_ratings["anime_id"])
rec_ids = [anime.loc[i, "anime_id"] for i in sim_indices if anime.loc[i, "anime_id"] not in seen][:top_k]
recs = set(rec_ids)
user_test = ratings_test[ratings_test["user_id"] == u]
liked_test = set(user_test[user_test["rating"] > 7]["anime_id"])
if len(liked_test) == 0:
continue
hit = len(recs & liked_test)
precisions.append(hit / top_k)
recalls.append(hit / len(liked_test))
rec_records.append({
"user_id": u,
"liked_in_test": anime[anime["anime_id"].isin(liked_test)]["name"].tolist(),
"recommended": anime[anime["anime_id"].isin(rec_ids)][["anime_id","name"]].to_dict(orient="records")
})
mean_precision = np.mean(precisions) if precisions else 0
mean_recall = np.mean(recalls) if recalls else 0
# MLflow logging
mlflow.log_param("model", "item_based_tfidf")
mlflow.log_param("sample_users", 50)
mlflow.log_param("top_k", top_k)
mlflow.log_metric("precision_at_10", mean_precision)
mlflow.log_metric("recall_at_10", mean_recall)
# 推薦清單 CSV
df_examples = pd.DataFrame(rec_records)
out_path = os.path.join(DATA_DIR, "item_based_examples.csv")
df_examples.to_csv(out_path, index=False)
mlflow.log_artifact(out_path, artifact_path="recommendations")
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument("--top_k", type=int, default=10)
args = parser.parse_args()
main(args.top_k)
因為我們使用 本地 pip 環境,所以要加 --env-manager local:
mlflow run . -e user_based -P top_k=10 --env-manager local --experiment-name anime-recommender-project-run
mlflow run . -e item_based -P top_k=10 --env-manager local --experiment-name anime-recommender-project-run


打開 MLflow UI → Experiments → anime-recommender-baseline
metrics:
user_based_cf → precision_at_10, recall_at_10item_based_tfidf → precision_at_10, recall_at_10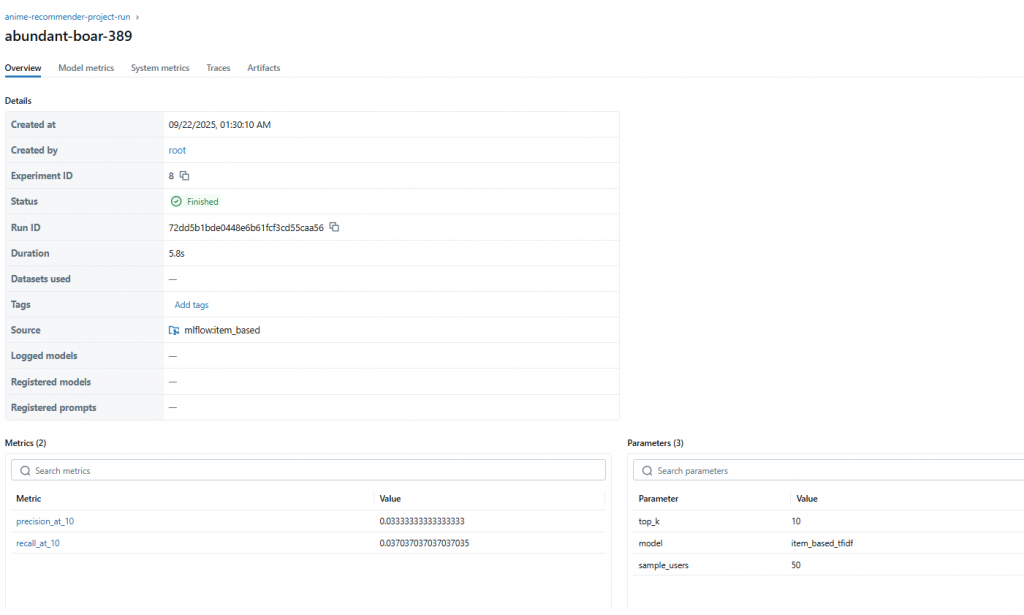
artifacts:
recommendations/
├── user_based_examples.csv
├── item_based_examples.csv
👉 點下載 CSV,就能看到部分使用者的「測試集喜歡動畫 vs 模型推薦動畫」清單。
mlflow run 搭配 --env-manager local 就能直接在本地環境跑。

 iThome鐵人賽
iThome鐵人賽