
過去工程師用 C 寫作業系統、寫伺服器,然後花費無數個夜晚,在生產環境中除錯這兩類 bug:
懸空指標 (Dangling Pointers / Use-After-Free)
Segmentation fault。運氣不好,就是資料損毀。資料競爭 (Data Races)
Rust 的設計者看透了這一點。
他們決定,與其事後除錯,不如在編譯期間就從根本上杜絕這兩類問題。
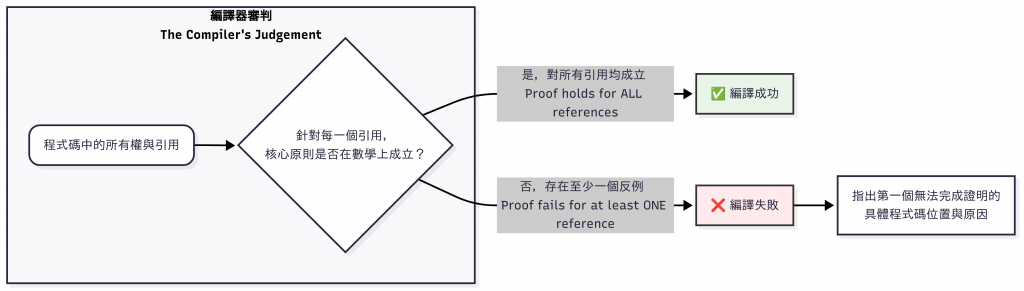
Borrow Checker 不是敵人,它是你最強大的 Code Reviewer。
它是一個證明,證明你的程式碼不可能發生上述兩種災難。
資料唯一性:
在任何時間點,一塊資料要嘛只能有一個「寫入者」(可變借用
&mut T),
要嘛可以有無數個「讀取者」(不可變借用&T),但絕不能兩者共存。
還有一個必然的推論:
任何「讀取者」或「寫入者」(引用),都不能比它指向的資料活得更久。

fn ownership_check() {
let s1 = String::from("hello");
let s2 = s1; // s1 的所有權轉移給 s2
// let s3 = s1; // ❌ 錯誤:s1 已經不是主人了,你不能再把它交給 s3
}
為什麼 s1 會失效?因為 String 存在堆上。
如果 s1 和 s2 同時認為自己擁有這塊記憶體,在它們各自離開作用域時,就會嘗試釋放同一塊記憶體兩次。
就是二次釋放 (double free) 是嚴重的記憶體錯誤。
透過轉移所有權,Rust 確保任何時候都只有一個變數負責釋放記憶體,可以從源頭上杜絕問題,而不是靠程式設計師的記性。
fn borrowing_check() {
let mut s = String::from("hello");
let r1 = &s; // 一個「讀取者」出現了
let r2 = &mut s; // ❌ 錯誤:你想在有「讀取者」的時候,引入一個「寫入者」
// println!("{}", r1);
}
它直接違反了「一個寫入者」或「多個讀取者」的原則。
如果編譯器允許這段程式碼通過,r1 在讀取 s 的時候,r2 可能正在修改它(資料競爭)。
fn lifetime_check() {
let r;
{
let x = 5;
r = &x; // ❌ 錯誤:你讓 r 借用了 x
} // x 在這裡被銷毀了。它的生命週期結束了。
// println!("{}", r); // 但 r 還活著,它現在指向一個無效的記憶體位置
}
違反了「引用不能活得比資料久」。
編譯器透過生命週期分析,看到 x 的生命週期只在內部的 {} 大括號裡,而 r 的生命週期比它長。
如果這能編譯,println! 執行時 r 就是一個懸空指標。
編譯失敗,意味著編譯器為你證明了程式
初學者遇到編譯錯誤,最喜歡的「解決方案」就是 clone()。
let s1 = String::from("hello");
let s2 = s1.clone(); // 複製一份,s1 和 s2 各自擁有資料
println!("s1 = {}, s2 = {}", s1, s2); // 能跑了!
如果你發現自己總是在用 clone() 來安撫編譯器,代表你的資料所有權設計從一開始就是錯的。你應該停下來,重新思考你的函式該接收所有權 (s: String),還是只接收一個不可變的借用 (s: &str)。
適合使用的時機是,需要一份完全獨立的資料副本時,才使用它。
Borrow Checker 的重點是:
在寫程式碼的時候,就必須想清楚資料由誰擁有、在何時會被讀取、在何時會被寫入。
它強迫你在問題最容易解決的階段——也就是在你自己的大腦裡——去處理複雜性。
強迫你寫出不垃圾的程式碼,強迫你學習正確的記憶體管理方式,並讓你成為一個「更好」的工程師。
雖然學習曲線很陡峭,但一旦你理解了它的工作原理,你就會發現它是一個非常強大的工具。
在下篇,我們將深入探討錯誤處理,看看 Rust 如何用 Result 和 Option 來處理錯誤。


 iThome鐵人賽
iThome鐵人賽