昨天我們已經能夠成功把網站的標題與連結抓下來,甚至存成 CSV 檔案。但實際爬下來的結果,往往會有一些問題:
有些標題是空的或只有符號
有些連結是重複的
有些標題太長,不方便閱讀
今天我們要在程式中加入 資料清理(Data Cleaning) 的步驟,讓輸出的結果更乾淨。
修改程式碼
在 crawl_titles.py 裡,找到處理結果的部分,並加上以下規則:
def clean_results(pairs, allowed, limit):
seen = set()
cleaned = []
for text, link in pairs:
# 1. 過濾掉非 http(s) 的連結
if not link.startswith(("http://", "https://")):
continue
# 2. 過濾掉不在允許網域內的連結
if not same_domain(link, allowed):
continue
# 3. 清理標題:去掉前後空白,只保留前 50 個字
text = text.strip()
if not text:
continue
if len(text) > 50:
text = text[:50] + "..."
# 4. 去重複(相同文字+網址的組合)
key = (text, link)
if key in seen:
continue
seen.add(key)
cleaned.append({"text": text, "url": link})
if len(cleaned) >= limit:
break
return cleaned
然後在 main() 中,改成:
pairs = extract_links(html, start)
cleaned = clean_results(pairs, allowed, args.limit)
測試程式
python crawl_titles.py https://ithelp.ithome.com.tw/ --allow ithelp.ithome.com.tw --limit 20 --out clean_links.csv --insecure
實作: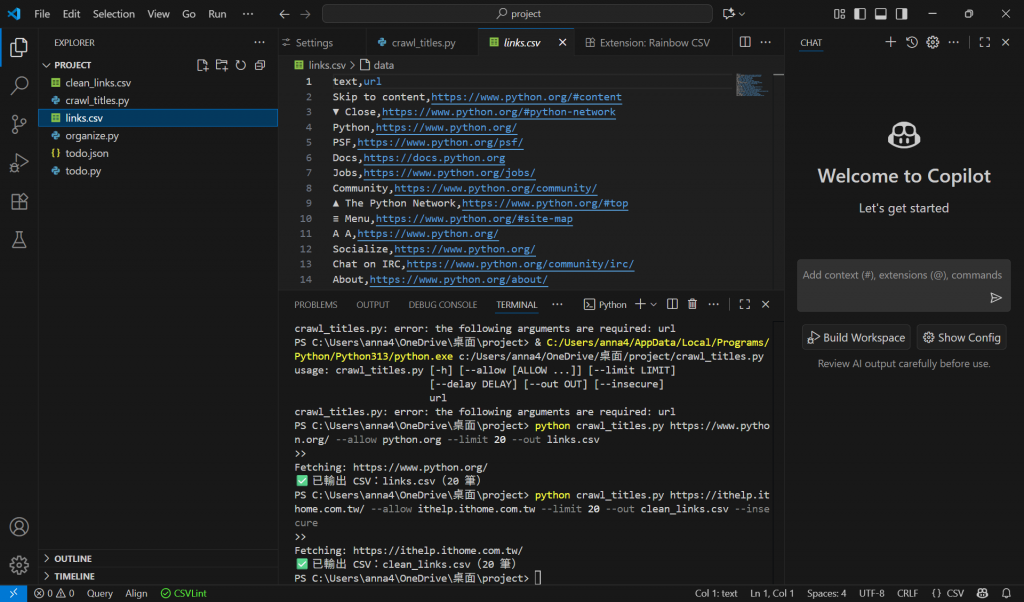
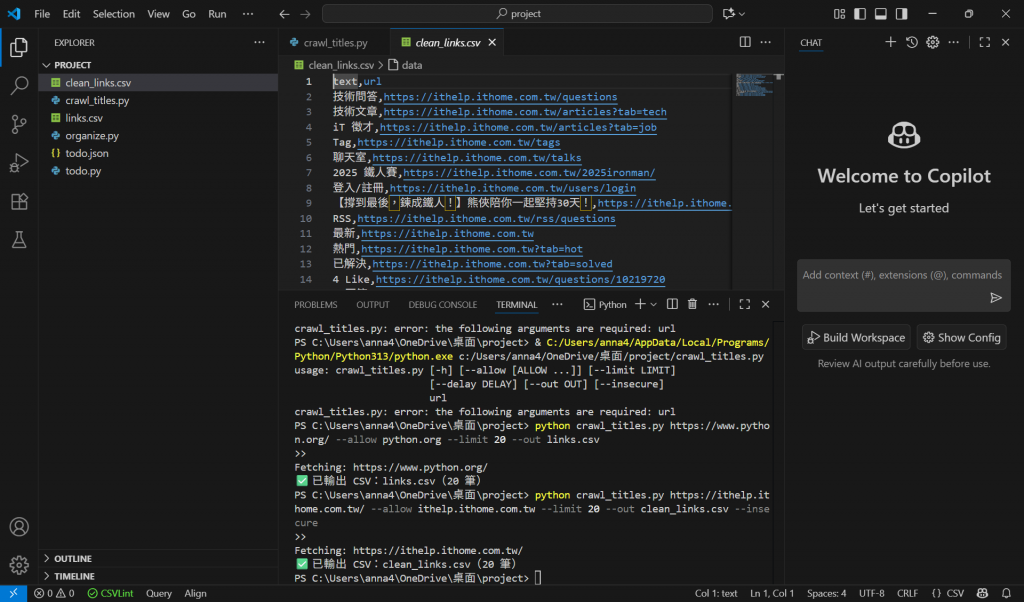
你會發現:
標題不會再出現空的或全是符號的項目
標題超過 50 字會被截斷,加上 ...
重複的連結只會保留一次
今日重點
資料清理 在爬蟲中很重要,可以大幅提升資料品質
你可以依需求調整清理規則,例如限制字數、排除特定網址
 eyeyeyeye
eyeyeyeye
