一鍵自動化你會得到什麼
一支 pipeline.py 可以一鍵跑完 Day 4–8 的流程
支援一次處理多個網站
自動把輸出 CSV 放到 data/,查詢結果放到 exports/
結束會列出摘要
程式碼(pipeline.py)
# pipeline.py — Day 9:一鍵自動化 (crawl -> clean -> CSV -> DB -> FTS -> exports)
import subprocess, sys, csv, time
from pathlib import Path
from urllib.parse import urlparse
import argparse, re
# === 1) 參數設定:可自行修改 ===
SITES = [
{
"url": "https://ithelp.ithome.com.tw/",
"allow": ["ithelp.ithome.com.tw"],
"limit": 50,
"delay": 0.5,
"insecure": True, # ithelp 如遇憑證問題就 True
},
{
"url": "https://www.python.org/",
"allow": ["python.org"],
"limit": 50,
"delay": 0.5,
"insecure": False,
},
]
DB_PATH = "crawler.db"
# 跑完後想匯出的查詢(FTS)
EXPORT_QUERIES = [
("python", 1, 20), # (關鍵字, 第幾頁, 每頁幾筆)
("鐵人賽", 1, 20),
]
# === 2) 路徑設定 ===
ROOT = Path(__file__).resolve().parent
DATA_DIR = ROOT / "data"
EXP_DIR = ROOT / "exports"
DATA_DIR.mkdir(exist_ok=True)
EXP_DIR.mkdir(exist_ok=True)
PY = sys.executable # 使用目前的 Python 執行檔
def run(cmd: list[str], cwd: Path = ROOT) -> tuple[int, str, str]:
"""執行子行程並回傳 (returncode, stdout, stderr)"""
p = subprocess.run(cmd, cwd=cwd, text=True, capture_output=True)
if p.stdout.strip():
print(p.stdout.rstrip())
if p.stderr.strip():
print(p.stderr.rstrip())
return p.returncode, p.stdout, p.stderr
def now_tag() -> str:
return time.strftime("%Y%m%d_%H%M%S")
def sanitize(name: str) -> str:
return re.sub(r"[^-\w\.]+", "_", name)
def crawl_one(site: dict) -> Path | None:
"""呼叫 Day4/5 的 crawler,輸出到 data/*.csv,回傳 CSV 路徑"""
url = site["url"]
allow = site.get("allow") or [urlparse(url).netloc.lower()]
limit = str(site.get("limit", 50))
delay = str(site.get("delay", 0.5))
insecure = site.get("insecure", False)
dom = sanitize(urlparse(url).netloc or "site")
out_csv = DATA_DIR / f"{dom}_{now_tag()}.csv"
cmd = [PY, "crawl_titles.py", url, "--limit", limit, "--delay", delay, "--out", str(out_csv)]
if allow:
cmd += ["--allow", *allow]
if insecure:
cmd += ["--insecure"]
print(f"\n==> Crawling {url} -> {out_csv.name}")
rc, _, _ = run(cmd)
if rc != 0 or not out_csv.exists():
print(f"❌ 爬取失敗:{url}")
return None
# 檢查是否有資料
try:
with out_csv.open(encoding="utf-8") as f:
rows = sum(1 for _ in csv.reader(f)) - 1 # 扣掉表頭
print(f"✅ 產生 CSV:{out_csv.name}({max(rows,0)} 筆)")
except Exception:
print(f"⚠️ CSV 讀取異常:{out_csv}")
return out_csv
def import_csv_to_db(csv_path: Path, db: str):
print(f"==> 匯入 SQLite:{csv_path.name} -> {db}")
cmd = [PY, "save_to_db.py", "--csv", str(csv_path), "--db", db]
rc, *_ = run(cmd)
if rc != 0:
print("❌ 匯入失敗")
def rebuild_fts(db: str):
print("==> 重建 FTS 索引")
cmd = [PY, "fts_search.py", "--db", db, "rebuild"]
rc, *_ = run(cmd)
if rc != 0:
print("❌ FTS 重建失敗")
def export_query(db: str, q: str, page: int, size: int):
out = EXP_DIR / f"fts_{sanitize(q)}_p{page}_s{size}.csv"
print(f"==> 匯出查詢:{q} -> {out.name}")
cmd = [PY, "fts_search.py", "--db", db, "search", "--q", q, "--page", str(page), "--size", str(size), "--out", str(out)]
rc, *_ = run(cmd)
if rc != 0:
print(f"❌ 匯出查詢失敗:{q}")
def main():
ap = argparse.ArgumentParser(description="Day 9:一鍵自動化 Pipeline")
ap.add_argument("--skip-crawl", action="store_true", help="略過爬取/清理(直接用既有 CSV)")
ap.add_argument("--skip-import", action="store_true", help="略過匯入 DB")
ap.add_argument("--skip-fts", action="store_true", help="略過重建 FTS")
ap.add_argument("--no-export", action="store_true", help="不匯出查詢結果")
ap.add_argument("--db", default=DB_PATH, help="SQLite DB 檔名(預設 crawler.db)")
args = ap.parse_args()
produced: list[Path] = []
if not args.skip_crawl:
for site in SITES:
csv_path = crawl_one(site)
if csv_path:
produced.append(csv_path)
else:
print("⚠️ 已略過爬取階段 (--skip-crawl)")
if not args.skip_import:
# 先把 data/ 底下的 CSV 全部匯入(含本次新產生)
all_csvs = sorted(DATA_DIR.glob("*.csv"))
if not all_csvs:
print("⚠️ data/ 下沒有 CSV 可匯入")
for csv_file in all_csvs:
import_csv_to_db(csv_file, args.db)
else:
print("⚠️ 已略過匯入階段 (--skip-import)")
if not args.skip_fts:
rebuild_fts(args.db)
else:
print("⚠️ 已略過 FTS 重建 (--skip-fts)")
if not args.no_export:
for q, page, size in EXPORT_QUERIES:
export_query(args.db, q, page, size)
else:
print("⚠️ 已略過查詢匯出 (--no-export)")
# 總結
print("\n=== ✅ Pipeline 完成 ===")
if produced:
print("本次產生的 CSV:")
for p in produced:
print(" -", p.relative_to(ROOT))
print("DB:", args.db)
print("匯出資料夾:", EXP_DIR.relative_to(ROOT))
if __name__ == "__main__":
main()
怎麼跑
在 project 目錄下:
python pipeline.py
可加參數控制步驟(例如只匯出、不重建索引):
python pipeline.py --skip-crawl --skip-import
python pipeline.py --no-export
跑完該看到什麼
data/:各網站對應的 .csv(已清理過)
crawler.db:資料庫已新增/更新資料
exports/:fts_.csv 搜尋結果
Terminal 會列出每一步的 ✅ / ⚠️
實作: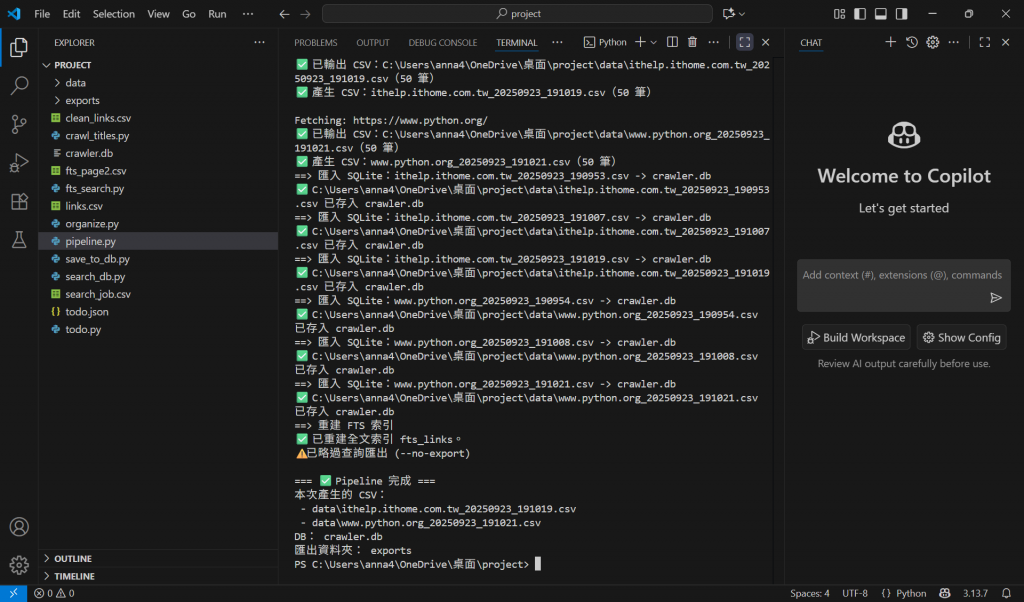
(可選)排程每天自動跑(Windows)
1.找到 pipeline.py 的完整路徑,例如:C:\Users\anna4\OneDrive\桌面\project\pipeline.py
2.以系統管理員開 PowerShell,建立每日 09:00 執行的排程:schtasks /Create /SC DAILY /TN "CrawlerPipelineDaily" ^ /TR "python C:\Users\anna4\OneDrive\桌面\project\pipeline.py" /ST 09:00
之後可在「工作排程器」裡調整時間或刪除排程。
 eyeyeyeye
eyeyeyeye
