數據切割的目的主要是分出訓練集跟測試集。
假如不分割會出現測試集資料在訓練集裡面出現,那不就是照抄答案了嘛!
會造成model的準確率不可考。之前就是這樣被教授念過,那時候笨笨的總是想懶惰不想理解。
train_test_split()
train_test_split(*arrays, test_size=None, train_size=None, random_state=None, shuffle=True, stratify=None)
參數介紹:
- arrays: 傳入要分割的陣列或資料集,通常是特徵 X 和標籤 y。
- testsize: 指定測試集佔總資料的比例或數量。
- trainsize: 指定訓練集佔總資料的比例或數量。
- randomstate: 隨機數種子,確保每次分割的結果都相同。
- shuffle: 在分割前是否要打亂資料,預設為 True。
- stratify: 用來確保分割後的訓練集和測試集中,各類別的比例與原始資料集一致,常用於處理不平衡資料。*
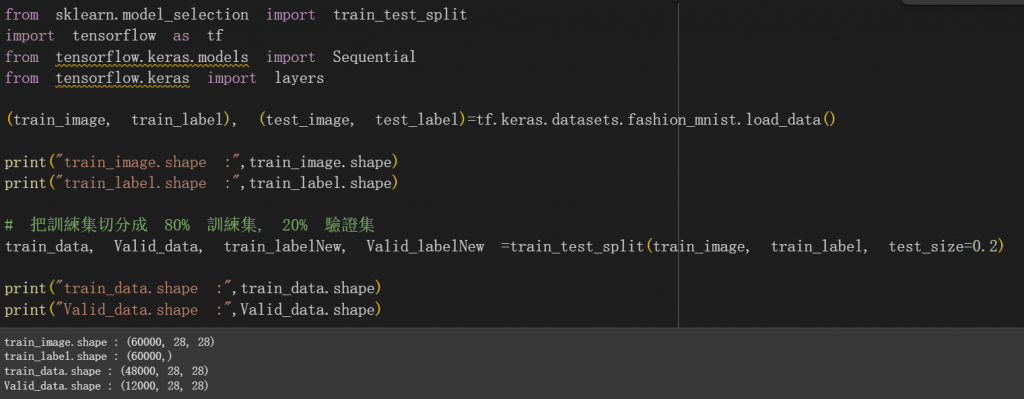
tf.split()
tf.split(value, num_or_size_splits, axis)
參數介紹:
- value: 這是要被分割的輸入張量。
- um_or_size_splits:如果是一個整數:表示要將張量平均切分成幾份。
- axis: 指定要進行切割的維度。axis=0 是第一個維度,axis=1 是第二個維度,以此類推。
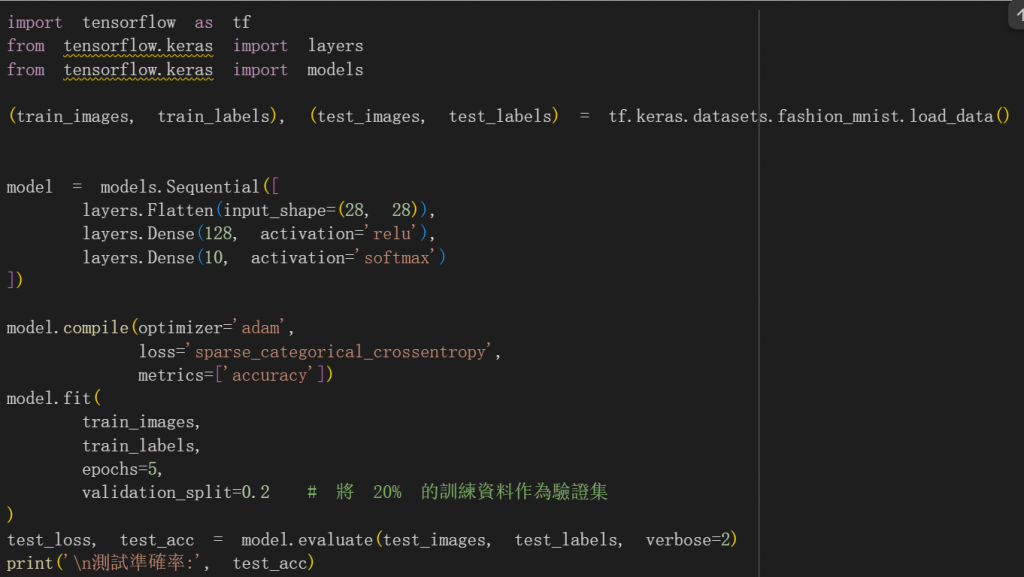
fit
fit當中的一個參數「validation_split」,平時使用時可以不用寫,但不可以不把數據切割就直接進行訓練。


 iThome鐵人賽
iThome鐵人賽