在深入探討卷積神經網路 (CNN) 之前,我們先回顧一個用於手寫數字識別的基礎模型:全連接網路。
- 全連接網路處理 MNIST 資料集
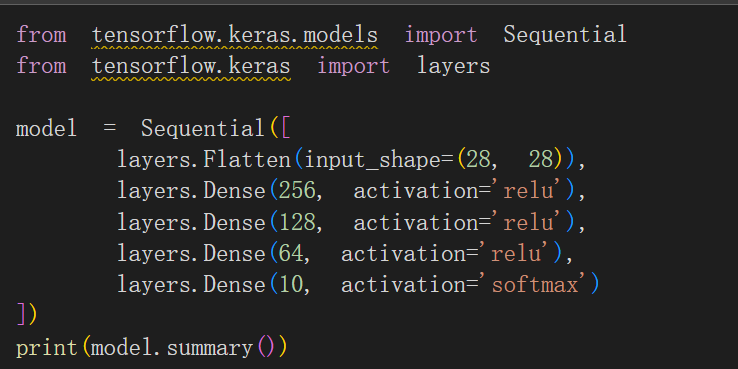
在處理 MNIST 資料集中的 28×28 像素的圖像時,一個常見的做法是先將 28×28=784 個像素點攤平 (Flatten) 成一個 784 維的輸入特徵向量,然後輸入到全連接網路中。
這個網路模型採用了 Keras 的 Sequential 結構,包含一個攤平層和四個全連接 (Dense) 層
1. 參數計算與全連接網路的局限性
全連接層的參數數量是輸入神經元數 × 輸出神經元數 + 偏置數 (Bias)。例如,第一層隱藏層的參數為 784×256+256=200,960。
這種全連接網路雖然可以對小尺寸圖像進行分類,但存在幾個嚴重的問題:
- 權重參數爆炸 (Parameter Explosion): 當圖片尺寸變大,例如 224×224 或更高,網路的參數數量將會暴增,極大地增加計算負擔和記憶體需求。
- 無法保留空間資訊: 攤平操作會破壞圖像中像素點的空間關係和局部結構。對於圖像識別,這就像將一張人臉的所有像素打亂後再試圖識別五官一樣,第一層隱藏層對待輸入的像素點是等同的,沒有考慮到相鄰像素的重要性。
- 訓練問題: 隨著網路層次加深,可能出現過度擬合 (Overfitting) 和梯度消失 (Vanishing Gradient) 等問題,導致深層網路的性能反而不如淺層網路。
2. 卷積神經網路 (CNN) 的核心思想
卷積神經網路 (CNN) 被提出,就是為了解決全連接網路在圖像處理上的這些根本限制。
CNN 是一種模擬人類視覺認知的深度學習方法。它不是以單一像素點的方式來進行圖像對比,而是透過以下方式來進行圖像特徵提取和學習:
- 局部連接和權重共享: CNN 通過卷積核 (Convolutional Kernel) 只與輸入圖像的局部區域進行連接,並在圖像的不同位置共享這個卷積核的權重,從而極大地減少了模型的參數數量。
- 特徵提取: 網路會從圖像中自動提取出不同層次的特徵,例如:
- 低階特徵: 邊緣、線條、斑點等。
- 高階特徵: 這些低階特徵經過組合,形成更複雜的模式(例如圖 7-4 所示的人臉五官)。
- 平移不變性 (Translation Invariance): 由於卷積核的權重共享特性,CNN 對圖像中物體的位置變化具有一定的容忍性,即一個物體無論在圖像的哪個位置,都能被識別。
3. LeNet-5:經典的 CNN 架構
LeNet-5 是 Yann LeCun 於 1998 年提出的一個經典卷積神經網路架構,它為後來的 CNN 發展奠定了基礎。
LeNet-5 架構(如圖 7-5 所示)主要由以下核心部分組成:
特徵提取與壓縮部分 (Convolutional and Pooling Layers):
- 卷積層 (Convolution layer, C): 用於提取圖像中的局部特徵。
- 池化層/次採樣層 (Pooling/Subsampling layer, S): 用於對特徵圖進行降維和壓縮,同時增強模型的魯棒性。
LeNet-5 結構通常包含多次卷積 → 池化的組合。
分類部分 (Fully Connected Layer):
- 全連接層 (Fully Connected layer, F): 在特徵提取完成後,將提取到的高階特徵輸入到傳統的全連接網路中進行最終的物體分類。
總結
CNN 巧妙地利用了圖像的空間結構,透過卷積和池化操作有效地提取特徵並大幅減少了參數,成功克服了傳統全連接網路在處理高維圖像資料時遇到的參數爆炸和空間資訊丟失等問題,成為現代電腦視覺領域的基石。


 iThome鐵人賽
iThome鐵人賽