知識庫 (Knowledge Base)、PGVector、向量資料庫、檢索增強生成 (RAG)、GPT-5、Chunk 切分、向量化 (Embeddings)
在企業導入 AI 技術的潮流中,如何讓 ChatGPT 這樣的語言模型幫助我們即時獲取企業內部知識,成為一大課題。
假設您的公司使用 Odoo 18 ERP 系統來管理文件、知識頁面、客戶資訊、郵件往來與訂單等資料,那麼累積的資料就是一座寶庫。然而,傳統關鍵字搜尋往往難以直接從這些異構資料中得到滿意的答案。
而檢索增強生成 (Retrieval-Augmented Generation, RAG) 的出現,讓我們有機會將大型語言模型與企業自有的知識庫結合,打造一個能回答內部問題的智慧問答系統。
今天我們將一起構建一個簡易的 RAG 架構範例,說明如何:從 Odoo 匯出資料→向量化建立知識庫→透過 PGVector 儲存向量→使用 FastAPI 提供查詢服務→結合 GPT-5 回答問題。
RAG 是近年來興起的一種技巧,將大型語言模型 (LLM) 與外部知識庫結合,以產生更準確且與情境相關的回答。
簡單來說,傳統的 LLM(例如 GPT 模型)在單獨使用時有兩大限制:
而 RAG 架構透過在回答問題時即時檢索相關知識提供給模型,讓模型的回答有根據。由於模型能參考最新的資料來源,RAG 可以有效解決傳統 LLM 回答中幻覺頻發(當然還是無法 100% 解決)、無法取得即時資訊以及無法存取私有資料等問題。
RAG 核心流程包含:資料蒐集、Chunk 切分、文件向量化、向量資料庫檢索、提示詞生成以及LLM 回答等步驟。換言之,我們會先將知識庫資料轉成向量並儲存,查詢時將使用者問題也轉成向量,在向量資料庫中檢索出最相關的內容片段,再將這些內容放進 LLM 的提示中來增強模型的回答。如此一來,LLM 就像連上了企業自己的「智囊庫」,即使對於訓練資料中沒有涵蓋的內部知識,也能給出可靠的解答。
💡 Gary’s Pro Tip|RAG 就是提示工程的延伸
RAG 乍聽之下好像很高大尚,但在我看來,不過就只是提示工程、上下文工程的一種應用情境而已,本質上其實就是:將有價值、相關的資訊,塞給 LLM,提高他回答的準確與可靠性。
要打造企業內部的知識庫,我們首先需要將分散在 Odoo 系統各處的資料匯出並彙整出來。Odoo 18 擁有眾多模組,例如:Documents 文件管理、Knowledge 知識維基、客戶(聯絡人)資料、郵件訊息記錄 (mail.message) 以及訂單內容等。我們關心的多半是其中的文字內容部分,因為我們最終要將文字向量化供語言模型使用。
資料擷取:Odoo 本身以 PostgreSQL 作為資料庫,我們可以透過 Odoo 提供的 ORM API 或者 XML-RPC/JSON-RPC 介面來批量讀取所需的記錄。例如,我們可以撰寫一個 Python 腳本,使用 Odoo 的外部 API 認證後,依次讀取各模型資料:文件 (documents) 模組中的文件記錄、知識 (knowledge) 模組中的頁面內容、客戶 (res.partner) 模組中的客戶筆記或說明欄位、郵件 (mail.message) 模型中的郵件正文,以及訂單 (sale.order) 模組中的備註或描述欄等。每讀取一筆記錄,就取得其主要文字欄位內容及相關的標題或元資料。如此將分散各處的資訊蒐集起來。
內容清洗:從 Odoo 匯出的原始內容可能會含有各種 HTML 標籤、樣板文字或雜訊。例如郵件記錄通常帶有豐富的 HTML 格式(超連結、字體樣式)或系統附加的簽名檔。我們在向量化之前,應該先將內容轉換為乾淨的純文字。去除所有 HTML 標記。我們可以利用工具將 <p>, <br>, <div> 等標籤去掉,只保留人類可閱讀的文字。同時,也可以視情況去除一些無用的資訊(例如郵件尾部自動附加的隱私聲明等)。
💡 Gary’s Pro Tip|HTML 資料清洗
當處理像 Odoomail.message這類含有大量 HTML 格式的欄位時,建議使用 Python 的 BeautifulSoup 或其他 HTML 轉純文字工具來去除標籤,萃取純文字內容。這能大幅減少雜訊,提升後續向量化的品質。
Chunk 切分:清理完畢的純文字資料,可能長短不一。一些知識頁面或文件內容可能相當冗長,直接整篇送去嵌入向量不但成本高,檢索效果也可能不佳。我們需要將內容切分為適當大小的段落,也就是常說的 chunk。每個 chunk 可以是例如 300~500 個詞或約 數百個 Token 的大小,具體依模型上下文長度而定。切分時儘量在語意完整的邊界進行(例如段落、句子邊界),以免破壞內容的連貫性。對於較短的記錄(例如客戶名稱、地址等)可以不切分或與相關欄位合併成一個 chunk。一旦決定切分策略,我們就將每筆資料分割成多個 chunk,每個 chunk 都繼承來自原始記錄的某種識別(例如記錄ID或來源模組),以方便日後追蹤。
# 簡單的 Chunk 切分範例(根據 token 長度)
import tiktoken # OpenAI 的 token 計算工具
encoder = tiktoken.get_encoding("cl100k_base") # GPT-4/GPT-5 使用的字典
MAX_TOKENS = 500
def text_to_chunks(text, max_tokens=MAX_TOKENS):
tokens = encoder.encode(text)
# 按 max_tokens 大小切分 token 並解碼回文字
for i in range(0, len(tokens), max_tokens):
chunk_tokens = tokens[i:i+max_tokens]
chunk_text = encoder.decode(chunk_tokens)
yield chunk_text
# 假設 knowledge_page_content 是從 Odoo 知識模組擷取的純文字內容
for chunk in text_to_chunks(knowledge_page_content):
embedding = embed_text(chunk) # 調用向量嵌入模型生成向量
save_to_vector_db(chunk, embedding) # 將 chunk 及其向量存入向量資料庫
上面的程式碼範例展示了如何將一段長文字依據 token 長度切分為多個 chunk,對每個 chunk 調用 embed_text 獲取其向量表示,隨後存入向量資料庫。實務中可使用 OpenAI Embedding API 或 SentenceTransformer 等模型來生成向量。
💡 Gary’s Pro Tip|因地制宜的 Chunk 策略
針對特定領域資料可以調整 chunk 切分策略。例如法律事務所的大量合約或法規文件往往具有嚴謹的章節結構,建議以條款或章節為單位切分,而非機械地每 500 字就切一段,避免將具連貫意義的內容拆散,導致檢索不精確。善用文件原有的階層結構(標題、段落)來切分,可以提升後續檢索相關性。
向量化 (Vectorization):我們使用預訓練的語意嵌入模型(embedding model)將每個 chunk 轉換成數學向量。常見的做法是利用 OpenAI 提供的文本嵌入模型(如 text-embedding-3-small)得到 d 維的浮點向量(目前比較新的嵌入模型都可以指定輸出向量的維度,因為都有用到俄羅斯套娃 Matryoshka 的技術),或使用社群開源的模型(如 sentence-transformers)產生向量表示。每個 chunk 都會被映射到向量空間中,以便後續以向量相似度進行搜尋。
💡 Gary’s Pro Tip|向量維度的選擇
一般來說,向量維度越高,搜尋的效果會越好,然而實務上,不可能動不動就選擇幾千維的向量來使用,原因是因為成本和速度的考量,當維度越高,對於向量資料庫的儲存與維護費用會提高;另一方面就是在查找的速度上,也會變慢。所以選擇合適的向量大小也是一門在實作上要考量的因子。
存儲至 PGVector 向量資料庫:有了 chunk 及其向量,我們需要一個高效的方式將它們儲存並供未來查詢。在此我們選擇 PGVector —— PostgreSQL 的一個擴充套件,可讓資料庫支援向量欄位類型及相似度查詢。由於 Odoo 本身使用 PostgreSQL,這意味著我們可以直接在現有的資料庫上開啟 PGVector 功能,或在同一資料庫中新增一個專門的向量表。啟用 PGVector 相當簡單,只需在資料庫中執行安裝指令:CREATE EXTENSION vector;。接著我們建立一個資料表來存放知識庫向量,例如:
CREATE TABLE odoo_knowledge_vectors (
id BIGSERIAL PRIMARY KEY,
content_text TEXT,
embedding VECTOR(1024)
);
CREATE INDEX idx_vectors_embedding ON odoo_knowledge_vectors USING ivfflat (embedding vector_cosine_ops);
上述建表語句中,VECTOR(1024) 定義了一個長度為 1024 的向量欄位,並建立了一個 ivfflat 索引以加速 cosine 相似度的搜尋。之後,我們可以使用一般的 SQL INSERT 將每個 chunk 文字及其對應的向量插入表中。PGVector 讓我們在熟悉的 Postgres 環境下,就具備了先進的向量相似度查詢能力。整個知識庫準備過程完成後,資料庫中已經累積了大量「內容片段->向量」的對應記錄,等待查詢階段被檢索調用。
上述步驟完成後,我們便把 Odoo 各模組的文字資料轉化為了一個可供向量檢索的內部知識庫。下圖總結了資料從 Odoo 匯出到建立 PGVector 知識庫的流程:

有了向量化的知識庫,我們便可以建置前端應用或服務來處理使用者的提問並返回答案。在本例中,我們選擇用 FastAPI 建立一個簡易的查詢服務,整合前述的 PGVector 資料庫與 GPT-5 模型,實現 RAG 問答的流程。整體架構如下圖所示:
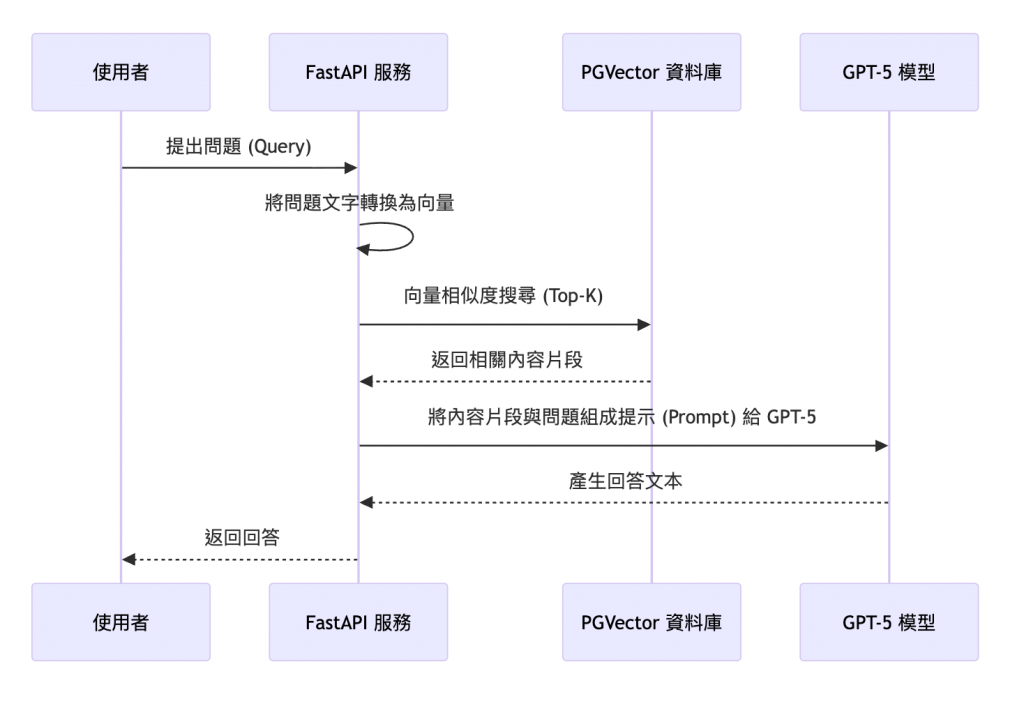
如上所示,查詢階段的關鍵步驟如下:
問題向量化:當使用者通過介面或 API 提交一個問題時,我們的 FastAPI 後端會先接收到這個查詢字串。如同知識庫建立時的做法,我們利用相同的嵌入模型將問題轉換成一個向量 q_vector。這確保了我們在相同的向量空間中比較問題與內容的相似度。(維度和模型記得要和建立向量知識庫時一樣)
向量相似度檢索:接著,我們在 PGVector 資料庫中執行一條向量相似搜尋查詢,找出與 q_vector 最相近的那些內容 chunk。具體而言,可以使用 PGVector 提供的 <-> 符號來比較向量距離,搭配 SELECT * FROM odoo_knowledge_vectors ORDER BY embedding <-> 'q_vector' LIMIT k 來取得距離最近的前 k 筆記錄。其中 k 是超參數,看你想要拿出幾筆紀錄(chunk),用來控制取出幾個最相關的內容片段。資料庫會返回這些記錄的內容文本以及(可能還有相關的來源資訊)。
組裝提示 (Prompt):FastAPI 後端拿到相關內容片段後,會將它們的文字與使用者的原始問題一起組合成一個提示(prompt)。提示的設計很重要——我們通常會加上一些說明,例如:「以下是內部知識庫文件的內容節選,請根據這些內容回答最後的問題。」然後列出幾段檢索到的內容,再附上「問題:{使用者問題}」以及「回答:」的字樣。這樣我們就構建了一個包含外部知識的輸入,提交給 GPT-5 模型。
💡 Gary’s Pro Tip|使用 XML tag 格式來區分資訊段落
在寫 LLM Prompt 的時候,可以有很多方式來區分不同目的、作用的資訊段落,有的人會用換行、##、===、””” 等等符號,而在 Agent 開發的經驗中,最好的間隔方式是使用 XML tag,例如:<relevant-documents> 相關的文件內容 … </relevant-documents>
LLM 生成回答:有了帶知識內容的 prompt,我們呼叫 GPT-5 模型的 API(或透過其 SDK)來生成回答。GPT-5 會將我們提供的內容作為參考來理解並回答問題。由於我們在 prompt 中提供了相關知識,GPT 的回答將會基於這些內容,而非憑空臆測。理想情況下,模型的回答不僅正確,還會引用我們給的內容要點,做到有憑有據。
返回結果:FastAPI 接收到 GPT-5 返回的回答文本後,最後一步就是將這個回答傳回給使用者。如果有需要,也可以在回答中附帶來源片段的引用資訊(例如告知答案根據哪幾份文件生成),以增加可信度。不過在我們的簡化流程中,可先不處理引用格式問題。
下面是一段示意性的 FastAPI 端點程式碼,展示上述流程的實現:
from fastapi import FastAPI
app = FastAPI()
@app.post("/query")
def query_answer(question: str):
# 第一步:將用戶問題轉換為向量
q_embedding = embed_text(question)
# 第二步:在 PGVector 資料庫中查詢最相近的內容片段
results = pg_query_top_k(q_embedding, table="odoo_knowledge_vectors", k=3)
# 將結果的 content_text 字段取出並拼接
context = "\n".join([res["content_text"] for res in results])
# 第三步:組裝 Prompt,包含檢索到的內容和原始問題
prompt = f"以下是知識庫內容節選:\n<context>{context}</context>\n根據以上內容,回答以下問題。\n問題:{question}\n回答:"
# 第四步:呼叫 GPT-5 API 完成回答生成
answer = gpt5_api_complete(prompt)
# 第五步:將回答返回給使用者
return {"answer": answer}
以上程式碼展示了一個最小原型:從接收問題到返回答案的完整 RAG 流程。在實際應用中,您可能還需要考慮異步請求的處理、錯誤處理、以及對 GPT-5 提示詞工程的調整(例如讓模型只根據提供的內容回答且不要編造)。
💡 Gary’s Pro Tip|控制 Token 用量
在部署 RAG 系統時,務必注意控制 Token 的用量以兼顧效能與成本。優化方法包括:精簡輸入內容,只檢索必要的相關片段,避免把過多無關文本塞進提示中;同時也可以限制模型輸出的長度,例如在 OpenAI API 呼叫時設定max_tokens,或在提示中明確要求簡明回答。如果使用 GPT-5,善用它提供的verbosity參數來控制回答的詳略程度也是有效方式——將verbosity設為 low 可讓回答更精簡,以減少 Token 消耗。透過這些措施,可以降低 API 調用成本並提升回應效率。
完成了上述架構搭建,我們的 FastAPI 服務就相當於一個「內部 ChatGPT」。用戶提出問題後,後端會在自家知識庫中檢索相關資訊,輔助 GPT-5 產生答案。例如,若業務人員問:「去年與某某客戶簽的合同付款條款是什麼?」系統會檢索 Odoo Documents 或 Knowledge 中那份合同的相關條文內容,並由 GPT-5 根據片段內容給出準確的付款條款說明。
值得一提的是,使用 PGVector 打造向量資料庫讓我們無需依賴第三方服務,直接在 Postgres 中完成向量索引與搜尋。這不僅節省成本,也讓資料留存在企業內部,安全性更高。我們也可以利用 Postgres 的事物和權限機制,確保資料庫操作可靠且具備基礎的存取控制能力。
我們完成的 RAG 系統雖然是個初步版本,但已具備核心的 Knowledge Base + LLM 問答能力。不過還有多方面可以加強與擴充:
WHERE department = 'Legal' 條件,只檢索法律部門允許的內容。透過對向量的過濾實現嚴格的存取控制。也可考慮串接企業的單一登入 (SSO) 或權限系統,做到問答響應因人而異,該看才能看。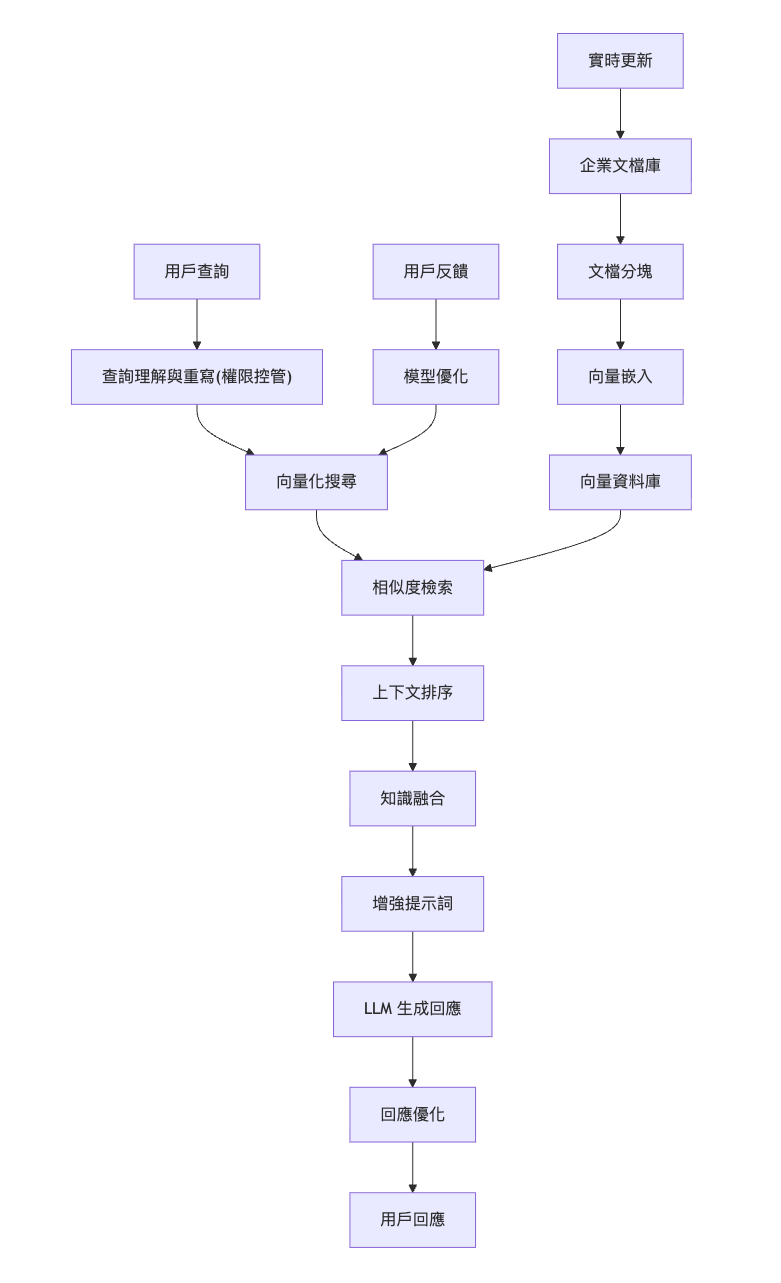
今天我們說明了實現 Odoo 知識庫 + PGVector + GPT-5 的 RAG 架構,是企業內部智慧問答的一個雛形。它讓繁雜的企業資料透過向量語意索引變得可檢索、可對話,讓 AI 幫助我們從大量文件中提取重點答案。
同時,這個架構具有良好的可擴充性。我們可以逐步引入版本控制確保知識新舊有序,強化權限管理保障數據安全,引入更多索引與多語支持來覆蓋更廣泛的需求。期待未來透過這樣的技術方案,企業能構建屬於自己的「AI 知識專家」,讓正確的人在正確的時刻,以對話的方式獲取所需的智慧與資訊!


