在 Day 15,我們統一了推薦輸出的格式,並存到 MLflow artifacts。
今天我們來進行:
/usr/mlflow/src/pipeline/pipeline_v4.py # 更新 explain_and_log
/usr/mlflow/run_pipeline_v4.py # 執行入口
📂 路徑:/usr/mlflow/src/pipeline/pipeline_v4.py
import os
import json
import pandas as pd
import numpy as np
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.metrics.pairwise import cosine_similarity
import mlflow
DATA_DIR = "/usr/mlflow/data"
class AnimePipelineV4:
def __init__(self, sample_size=500):
# 抽樣確保速度快
self.sample_size = sample_size
def load_data(self):
anime = pd.read_csv(os.path.join(DATA_DIR, "anime_clean.csv"))
anime = anime.sample(self.sample_size, random_state=42).reset_index(drop=True)
return anime
def train_model(self, anime, max_features=500, ngram_range=(1,1), min_df=2, use_type=True):
if use_type:
anime["features"] = anime["genre"].fillna("") + " " + anime["type"].fillna("")
else:
anime["features"] = anime["genre"].fillna("")
vectorizer = TfidfVectorizer(
stop_words="english",
max_features=max_features,
ngram_range=ngram_range,
min_df=min_df
)
tfidf = vectorizer.fit_transform(anime["features"])
sim_matrix = cosine_similarity(tfidf)
return sim_matrix, vectorizer
def explain_and_log(self, anime, vectorizer, params):
"""同時輸出 單一樣本 + 全資料集 平均特徵重要性"""
feature_names = vectorizer.get_feature_names_out()
# ✅ 單一樣本 (第一筆動畫)
tfidf_vector = vectorizer.transform([anime.iloc[0]["features"]]).toarray()[0]
sample_importance = sorted(
zip(feature_names, tfidf_vector),
key=lambda x: abs(x[1]),
reverse=True
)[:10]
sample_dict = {f: float(v) for f, v in sample_importance}
# ✅ 全資料集平均權重
tfidf_matrix = vectorizer.transform(anime["features"])
avg_weights = np.asarray(tfidf_matrix.mean(axis=0)).flatten()
global_importance = sorted(
zip(feature_names, avg_weights),
key=lambda x: abs(x[1]),
reverse=True
)[:10]
global_dict = {f: float(v) for f, v in global_importance}
# ✅ 存到 MLflow
with mlflow.start_run(run_name="pipeline-v4-explain") as run:
mlflow.log_params(params)
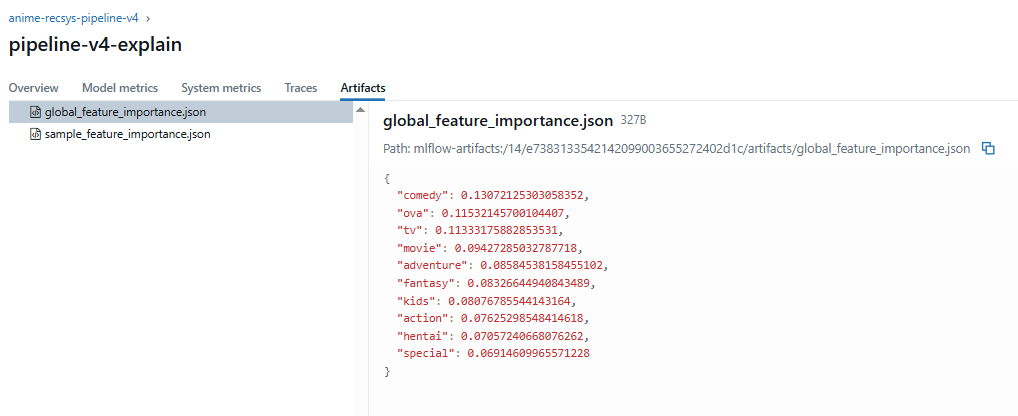
mlflow.log_dict(sample_dict, "sample_feature_importance.json")
mlflow.log_dict(global_dict, "global_feature_importance.json")
print("Run ID:", run.info.run_id)
print("Artifacts URI:", run.info.artifact_uri)
return sample_dict, global_dict
📂 路徑:/usr/mlflow/day16_run_pipeline_v4.py
import mlflow
from src.pipeline.pipeline_v4 import AnimePipelineV4
mlflow.set_tracking_uri("http://mlflow:5000")
mlflow.set_experiment("anime-recsys-pipeline-v4")
def main():
pipeline = AnimePipelineV4(sample_size=500)
anime = pipeline.load_data()
params = {
"max_features": 500,
"ngram_range": (1,1),
"min_df": 2,
"use_type": True
}
sim_matrix, vectorizer = pipeline.train_model(anime, **params)
sample_dict, global_dict = pipeline.explain_and_log(anime, vectorizer, params)
print("Pipeline V4 完成 ✅")
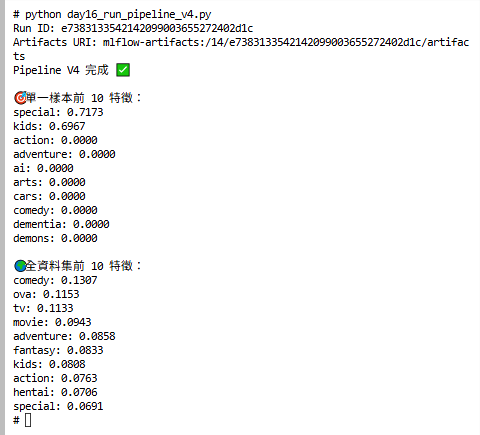
print("\n🎯 單一樣本前 10 特徵:")
for k, v in sample_dict.items():
print(f"{k}: {v:.4f}")
print("\n🌍 全資料集前 10 特徵:")
for k, v in global_dict.items():
print(f"{k}: {v:.4f}")
if __name__ == "__main__":
main()
mlflow.log_dict(dict_obj, artifact_file)
可存多份 JSON。
這裡我們用了:
sample_feature_importance.json → 單一樣本解釋global_feature_importance.json → 全資料集平均python day16_run_pipeline_v4.py
結果:
Console 會印出:
special, kids)。action, comedy, drama)。MLflow UI → Artifacts 裡會有:
sample_feature_importance.json
global_feature_importance.json
👉 換句話說:
這些特徵就是推薦系統的「分類依據」。如果你喜歡某部 comedy + adventure 的動畫,系統會特別去找其他同樣有 comedy + adventure 標籤的動畫來推薦。
而且特徵分數越高,就代表它對於分辨喜好、影響推薦結果的能力越強。
AnimePipelineV4
│
├── load_data()
├── train_model() → TF-IDF
└── explain_and_log()
├── sample_dict (單一樣本)
├── global_dict (全資料集平均)
└── mlflow.log_dict() → 存兩個 JSON
今天我們強化了 Day 16:
Artifacts 裡會有兩份 JSON,方便下載或對比。
👉 下一步(Day 17),我們將學習如何用 MLflow Models Serve 把模型包裝成 API,進行實際推論。


 iThome鐵人賽
iThome鐵人賽