早安大家~
前幾天我們已經把斷詞的概念以及如何操作介紹完了,昨天提到我們在做資料預處理時也會選擇把停用詞清除,這樣除了在做模型訓練時不會有雜訊外,有時候我們單純想看資料的關鍵詞也會比較準確。
那說到關鍵詞,我們就會想到林俊傑,或是說在資料中常出現的字詞,我們想知道哪些詞彙是重要的時候,通常會計算字詞出現的頻率,我們稱作Term Frequency(TF)。他的計算方式很直白的就是
TF = 某詞在文件中出現的次數 ÷ 文件的總詞數(就是每個詞在每個文本中出現的比率拉~),
我們前幾天用到的
Counter只有算頻率而已呦,如果要算詞頻需要再除以總詞數
而一般會認為,如果詞頻越高,就代表這個字詞對於這份資料越重要,但大家可以想想看:
以小說 《Dune(沙丘)》 為例,書中 「Dune」 這個詞可能是整套小說裡出現次數最多的詞,
然而它真的就是文本裡最有資訊價值、最能代表情節的關鍵詞嗎?可能不是吧!
所以單純算詞頻會遇到一些問題,像是一些功能詞(function words)、stop words 在文本當中一定是很常出現的,不過他們對於文本來說並不是特別重要(每個文本都會大量出現),或是說有些高頻詞幾乎在每篇文章都會出現,無法幫助我們判斷對於文本、資料的特殊性,也無法提供太多有用的資訊。
因此為了改進這個算法,後續就有了IDF 以及 TF-IDF 的算法來補足單純算詞頻(TF) 會有的缺陷,讓我們在考量詞頻的同時,也能衡量這個詞在整體文本集中有多「罕見」。所以今天的內容很簡單,就是要小小來介紹這些觀念拉!
💡 function words:又稱「功能詞」,指的是語法上必須存在,但語義資訊很少的詞,如冠詞、介系詞、助詞等。
那什麼是IDF 呢?
可以把他想像成是一個詞出現在文本中的「罕見機率」,可用來評估這個詞對於整個文本集來說的「重要性」。
他的算法為:文本數總和/想觀察的字詞出現在的文本數量,然後取log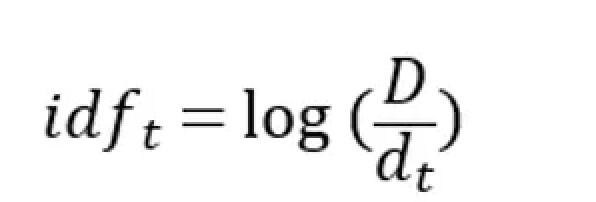
所以以公式上來看,如果在越多文本中越常出現,值會越小,越大就代表越少出現!
直白一點的理解就是,如果一個詞在很多文件裡都出現(例如英文的 the、中文的「的」),分母就大,這樣IDF 算出來的結果就會很小,可能就代表他沒有什麼資訊價值,而如果一個詞只在少數文件出現,分母就小,那它算出來的IDF 就會比較大,藉此代表它出現的很罕見
舉例來說,以剛剛說到的沙丘這本小說為例:
假設我們把全套小說分成很多章節(每章是一份文件)。
如果「Dune」這個詞只出現在極少數關鍵章節中,那它的 IDF 會很高,代表它一出現就帶有豐富的資訊量
最基本的公式如上,不過通常為了避免出現0的情況,也很常會使用有平滑之後的公式: log(文檔總數 + 1 / 特定字詞出現在的文本數量 +1) + 1
就是TF 和IDF 的結合xd,基本的概念就是如果一個詞在某篇文本中(例如《沙丘》第一章)出現頻率很高,但在整個文本集(例如整套《沙丘》)中相對罕見,那麼這個詞對這篇文本的代表性就越高,TF-IDF 的值也就越大。
舉例來說,若沙丘第一章中大量出現了dune這個詞,但其他章節幾乎沒出現,那他可能就是第一章的關鍵詞。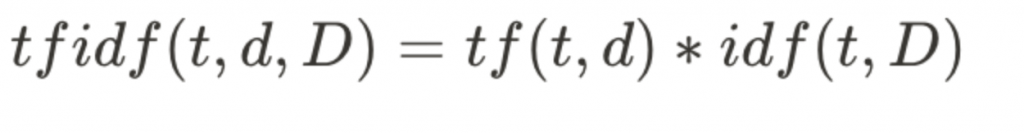
就是上面提到的 Term Frequency 乘上 IDF!
透過這些算法,就可以補足只算詞頻的不足,所以在許多任務上面我們也會選擇TF-IDF 的方式去找出關鍵訊息或是作文檔分類!
那今天就介紹這些小觀念給大家,實作的部分我們後面會再帶到,大家心裡先有個底,知道這是在算什麼的就好~
那我們就明天見嚕!掰噗~


 iThome鐵人賽
iThome鐵人賽