嗨嚕大家~
這幾天我們已經介紹過什麼是斷詞以及了解中文跟英文常用的斷詞工具,NLTK 以及jieba
昨天文章的最尾端我們用結巴成通斷詞,但發現斷完詞的資料依然是髒髒的,今天就來教大家怎麼清除「停止詞」!
停止詞(stop word)意思是說,在你的文字資料裡面非常頻繁的出現,但實際上他沒有太大意義的東西,
比如說標點符號、中文中的「的」、「吧」等等、英文中的介係詞、冠詞等。
說白一點就是這些東西去除掉之後對你的資料不會有任何影響,我們就會稱這些為停用詞、停止詞。
而根據你任務的不同,停止詞的內容也會有所不同,像是之前有說過如果想做情緒偵測相關的任務,標點符號對你來說可能就不會是停止詞,所以搞清楚自己的任務還是首要的!
去除停用詞的好處就是可以降低雜訊,停止詞通常對資料的意義貢獻不大,卻會在資料中大量出現,如果有時候我們可能要找資料中的關鍵詞有哪些,排除停止詞的干擾,可以幫助我們找到真正重要的關鍵詞。
以下用昨天有用到的新聞例子,如果我們今天想看前三名出現頻率最高的詞彙,在不排除停止詞的情況的結果會是這樣的:
#一樣是昨天的新聞段落
text = '''
氣象署今(22日)持續發布強烈颱風樺加沙海上、陸上颱風警報,8時的中心位置在北緯 19.3 度,東經 123.1 度,即在鵝鑾鼻的東南方約370 公里之處,以每小時20公里速度,向西轉西北西進行,暴風圈正逐漸進入台灣東南部近海,對台東、屏東、恆春半島及高雄已構成威脅,此颱風結構完整,未來強度仍有稍增強且暴風圈有稍擴大的趨勢。目前陸上警戒範圍維持高屏、台東地區。預估中午前暴風圈可能就會接觸恆春半島。氣象署表示,今天下半天到明天上半天是樺加沙颱風最接近我們的時候。'''
用自定義的字典斷詞
#自定義的字典
jieba.load_userdict("/Users/xxuan/Desktop/斷詞字典.txt")
words = jieba.lcut(text)
然後我們用Counter來幫助我們算詞頻,並印出最常見的五個
from collections import Counter
freq = Counter(words)
print(freq.most_common(5))
輸出結果
[(',', 10), (' ', 5), ('颱風', 4), ('、', 4), ('的', 4)]
有沒有看到!!這邊列出的五個最常見的詞中,只有颱風看起來真的是一個重要的詞xd 其他好像都沒什麼意義🥲
排除停止詞也因此對後續模型訓練的幫助很大,因為他可以避免模型被無意義的高頻詞影響,近一步影響模型表現。
好啦~在知道只詞的基本概念後我們就來實作一下吧!
以jieba來說,他裡面是沒有提供中文的停用詞字典,所以通常有兩個做法,ㄧ個是自己定義停用詞字典,一個是去網路上下載(網路上面有非常多可以下載的停用詞字典,大家可以多方看看,看看哪些最適合你的任務)
那在這邊我們就示範自訂義停用詞字典的方式!
首先第一步是打開一個txt 檔,裡面放你想清除的停止詞 (其實就跟昨天說的自訂義字典很像)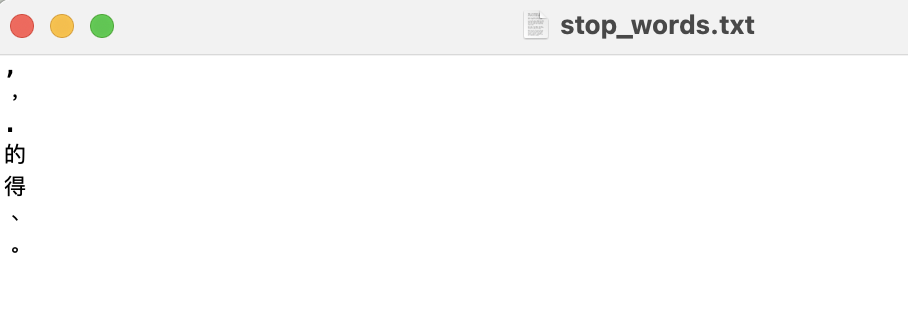
這邊就是很簡單放幾個當範例,大家可以自由新增xd
再來就是把檔案打開,讀stop_words每一行
with open('/Users/xxuan/Desktop/stop_words.txt', 'r', encoding='utf-8') as f:
stopwords = set([line.strip() for line in f])
然後再來我們一樣先用結巴斷詞,斷詞後看停止詞是否有出現,有的話就拿掉
words = jieba.lcut(text)
filtered_words = [w for w in words if w not in stopwords]
然後我們就可以來看看,最常出現的五個詞現在變成什麼了
freq = Counter(filtered_words)
print(freq.most_common(5))
輸出結果
[(' ', 5), ('颱風', 4), ('氣象署', 2), ('樺加沙', 2), ('陸上', 2)]
嘿嘿~是不是明顯比剛剛好很多,已經沒有標點符號來搗亂了!
那第一個' ' 就留給大家想想看如果今天要清掉他的話可以怎麼清🙂↕️
那其實如果你是在做英文斷詞,用NLTK套件的話,他其實是有內建字典的!
from nltk.corpus import stopwords
stopword = stopwords.words('english')
可以印出前20 個看看
print(stopword[1:20])
輸出結果
['me', 'my', 'myself', 'we', 'our', 'ours', 'ourselves', 'you', "you're", "you've", "you'll", "you'd", 'your', 'yours', 'yourself', 'yourselves', 'he', 'him', 'his']
我們直接拿這份字典來當範例,用一段bbc 的文章來練習,然後看看最常出現的10個字有哪些
text = """ As it cooks in a hot pan, these unwelcome guests
liquify, oozing into the meat before solidifying again as it cools down on your plate.
And they're not just in steak. Unwittingly, you are eating them all the time."""
from nltk.tokenize import word_tokenize
words = word_tokenize(text)
#過濾斷詞結果是否有出現在停止詞字典裡
filtered_words = [w for w in words if w not in stopword]
#算詞頻
freq = Counter(filtered_words)
print(freq.most_common(10))
輸出結果
[(',', 3), ('.', 3), ('As', 1), ('cooks', 1), ('hot', 1), ('pan', 1), ('unwelcome', 1), ('guests', 1), ('liquify', 1), ('oozing', 1)]
嘿嘿~這樣就出來拉!
會發現nltk 的停止詞字典好像沒有標點符號,這時候可以再用前幾天有介紹到的re 加以處理!
就當練習題給大家嚕~~
好啦!那今天就簡單介紹到這裡
明天見!


 iThome鐵人賽
iThome鐵人賽