昨天 (Day 23) 我們介紹了 CRI / CNI / CSI 這三個介面,其中 CNI 決定了 Pod 的網路如何被建立。今天我們就延續這個主題,深入看看 Kubernetes 中 Pods 之間的網路通訊是如何實作的。
本文基本上是參考這篇文章,整理重點成我覺得比較好理解的說法,有興趣的讀者們也可以自行參閱原文。
根據官方文件 [ref],Kubernetes 的網路模型必須滿足三個條件:
有了這些前提,就會衍生出四種常見的通訊情境:
今天我們先專注在前兩個:Pod 之內、Pod 與 Pod 之間的通訊。後面兩種則會在下一篇,與 Service 與 Ingress 一起好好介紹。
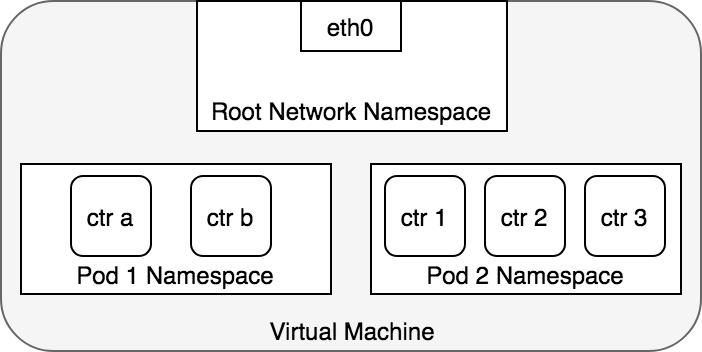
在 Linux 世界裡,所有執行中的 process 都能夠透過 root network namespace 來進行溝通。而每個執行中的 process 也都會在某個 network namespace (netns) 裡。每個 netns 都有自己的 routing table、firewall rules 和虛擬網路裝置。如果兩個 process 在同一個 netns,就能直接透過這些網路資源溝通。
在 Kubernetes 中,Pod 的定義就是「一組共享同一個 netns 的 containers」。也就是說,同一個 Pod 裡的 containers 會拿到相同的 IP 和 Port 空間,可以直接用 localhost 互相存取。
👉 實際範例:假設一個 Pod 裡有兩個容器
它們其實都在同一個 netns,因此 Nginx 可以直接透過 localhost:1234 呼叫 Sidecar 的服務,不需要額外設定。
接下來我們看 Pod 與 Pod 之間的溝通,這裡要分成 同一個 Node 和 跨 Node 兩種情境。
根據前一段所描述的基本架構,Pod 中的 container 會共享一個 netns,因此 Pod ↔ Pod 溝通「等於是兩個 namespace 之間的溝通」。而在這個情境下,我們可以透過 virtual ethernet devices (veth pair) 的機制,來將 packet 傳到 root netns 來進行溝通。
veth pair 可以想像是由一對 virtual interface 所組成,只要將一個 virtual interface 貼在 root netns、另一個 virtual interface 貼在 pod netns 上,這兩個 netns 就可以透過這一對 veth pair 來進行溝通。
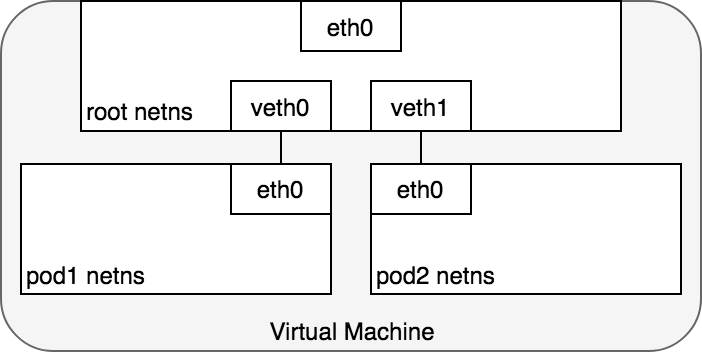
有了 veth pair 幫我們把封包送到 root netns 之後,我們還需要透過 Bridge (通常叫 cbr0) 讓封包從 veth0 走到 veth1。這個 Bridge 會看他身上的 ARP table,來根據 IP 決定這個封包要送往哪個 MAC address (assigned by virtual interface)。
基於以上的資訊,我們可以得知,Pod ↔ Pod 在同個節點上的封包傳輸流程會如下圖:
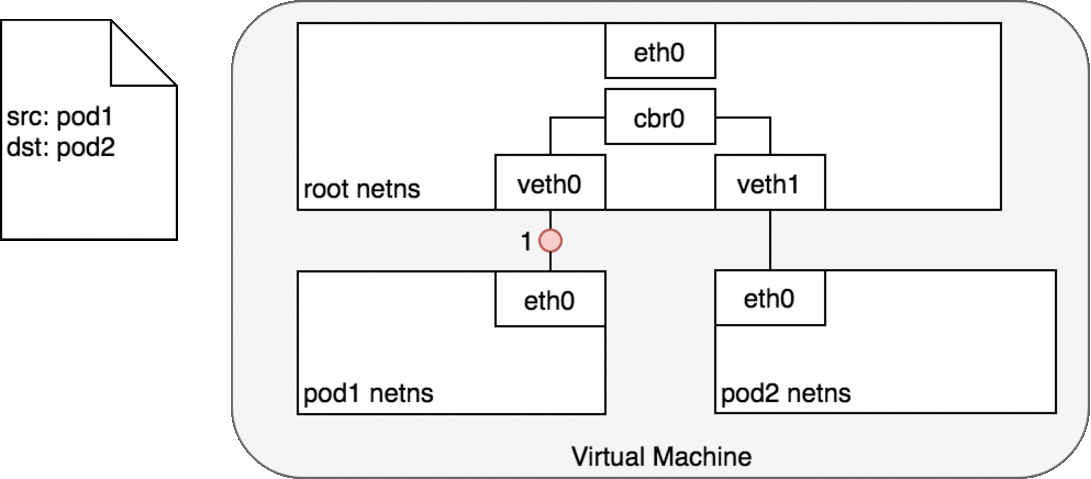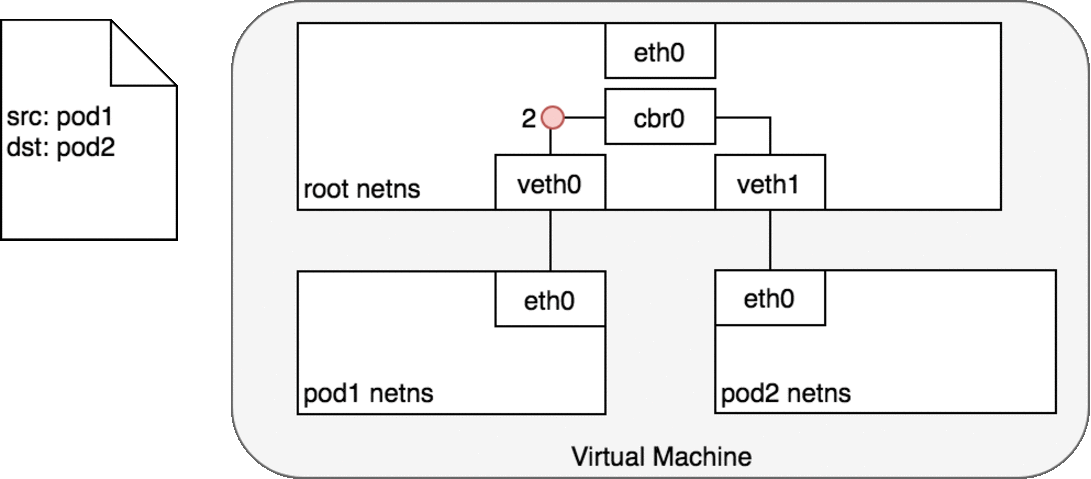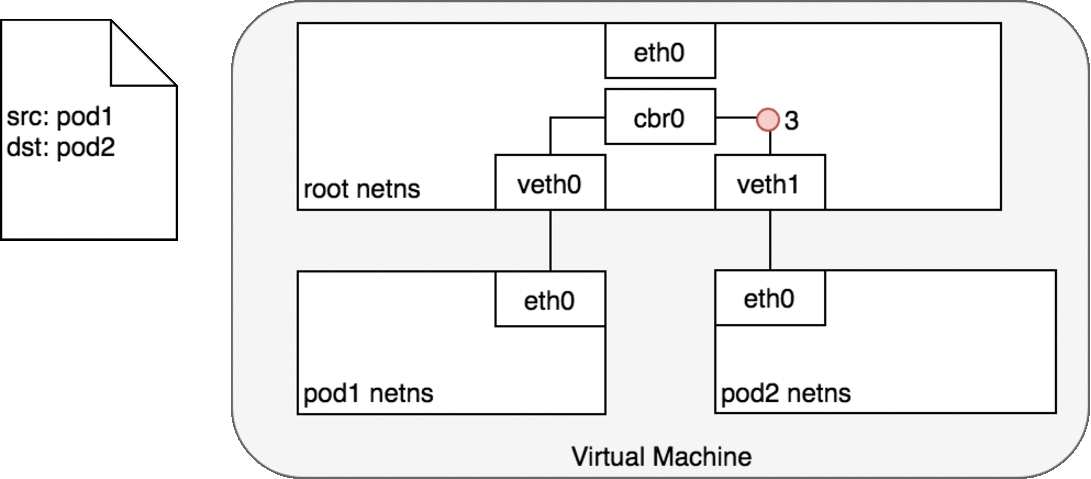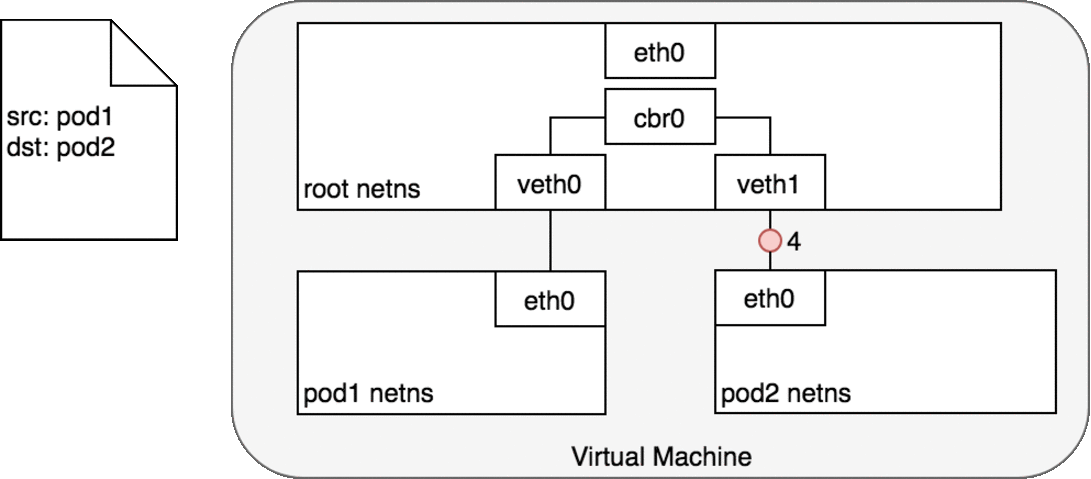
Pod ↔ Pod in the same node
在第 2-3 步時,cbr0 會根據他自己身上的 ARP table 發現,這個封包上的 IP 對應到的是 veth1 身上的 MAC address,因此封包被正確送到 pod 2 身上。
流程大概是這樣:
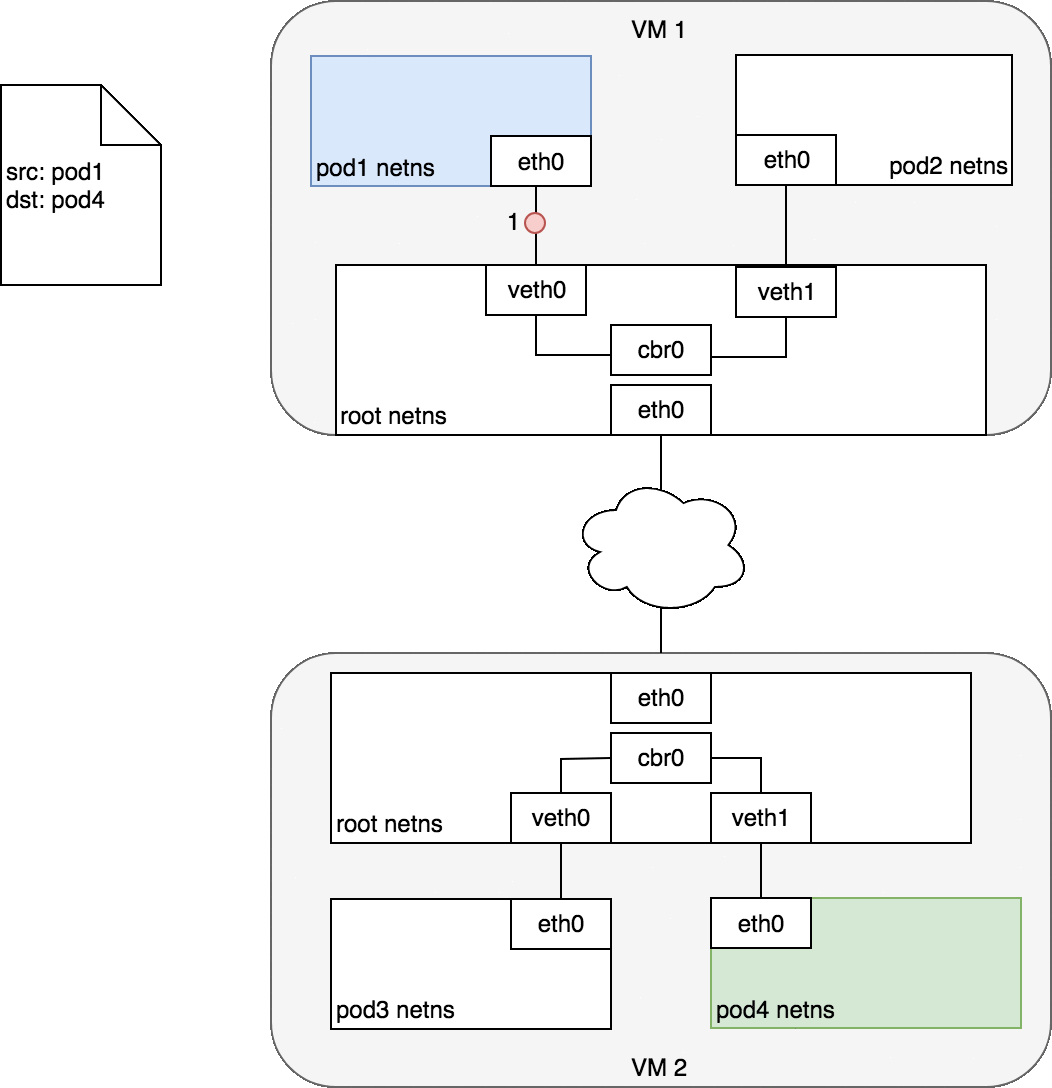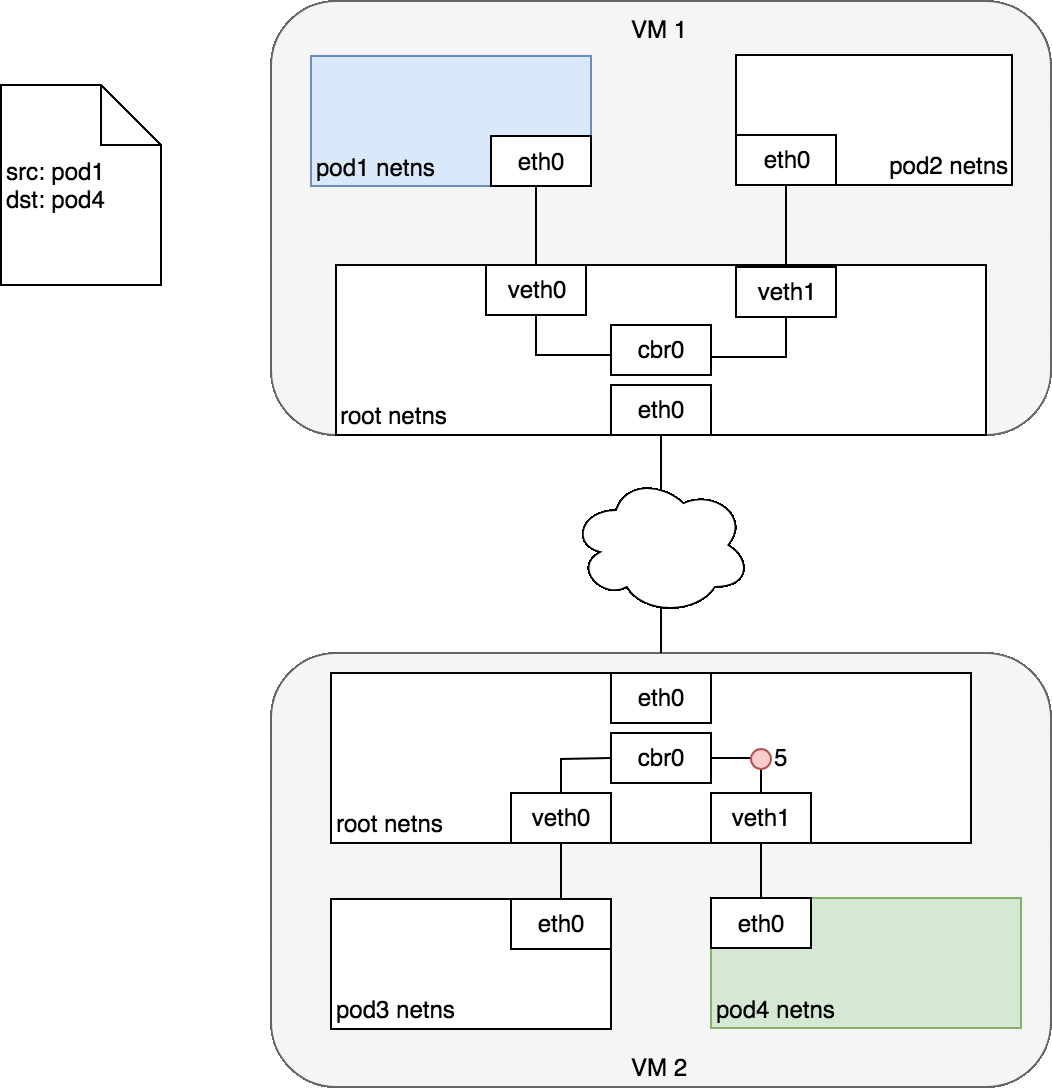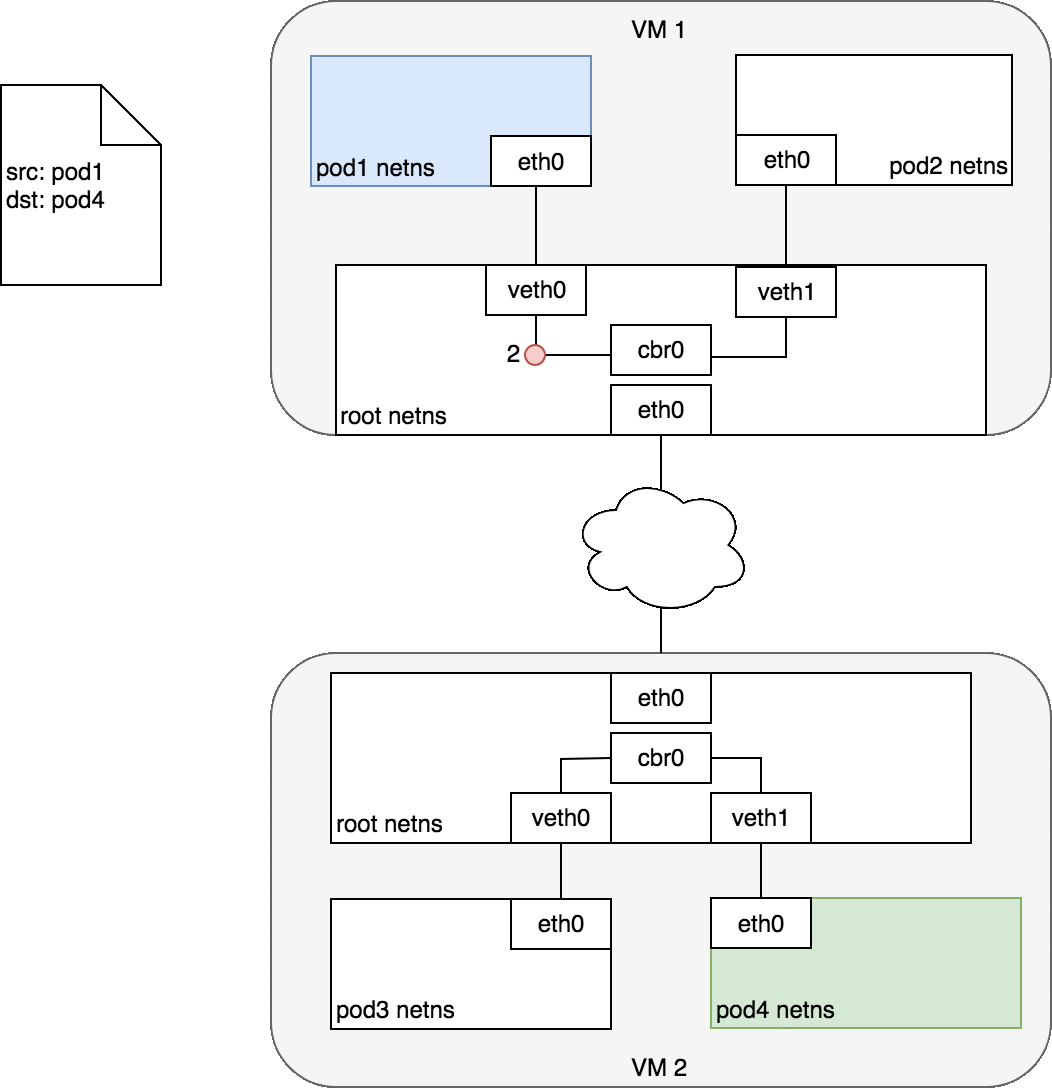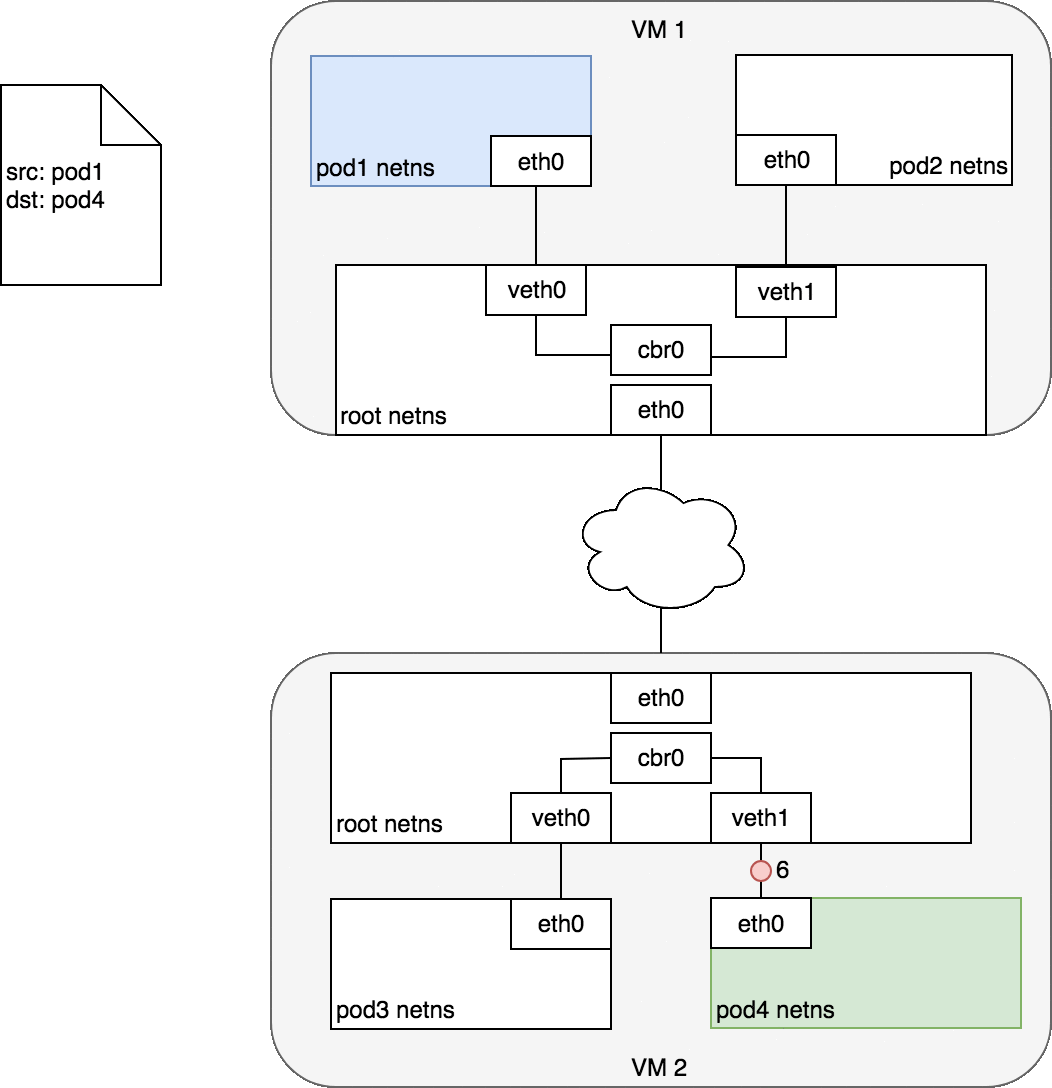
在第 2-3 步時,當 Bridge (cbr0) 發現「root netns 身上沒有對應的 MAC address (ARP failed)」之後,會把封包送去 root netns 的 eth0 (default route)。在第 4 步,假設 network 能做到根據 Node 的 CIDR block,把他送去正確的 Node 中。如此一來,第 5 步時,封包出現在正確的 node 之後,該 node 的 root netns 會再進行一次 ARP 對照,會發現 pod 4 的 MAC address 有對應到 dst IP,接著把這個封包送到 pod 4 當中。
與此同時,CNI 存在的目的即是完成上述的「Pods 之間傳輸」。以 AWS 開發的 VPC-CNI 為例:
這樣一來,即便 Pod 被分配在不同節點上,也能透過 VPC 原生的網路基礎設施互相通訊,無需額外設定 overlay。
不過這也代表著,我們在這個 cluster 裡面能開的 pods 數量會被 VPC CIDR 的大小所限制住。為了解決這個問題,我也曾經去研究其他的 CNI、像是 Cilium,這個就等到之後的章節再分享吧~
今天我們從 Container ↔ Container 講到 Pod ↔ Pod (同 Node / 跨 Node) 的實際傳輸流程,並解釋了 veth pair、Bridge、Route Table 與 CNI 的角色。理解 Pod 之間的通訊原理,能幫助我們在之後看待不同 CNI 與網路方案時更有感覺:
而在這之間,明天 (Day 25) 我們會先延伸到 外部要如何發起請求到 Service 或 Ingress 的原理,把 Pod 與外部世界的連線關係完整串起來 🚀。


 iThome鐵人賽
iThome鐵人賽