
上一篇(Day 24),我們聊到 Pod ↔ Pod 之間是怎麼溝通的:靠 veth pair、bridge、CNI 插件這些基礎設施,把封包在 cluster 內送來送去。這樣 cluster 內部的交通基本搞定了。
但大家用 K8s,最常見的問題不是「Pod 能不能互相講話」,而是:外面的使用者要怎麼存取 Pod 裡的應用?
在 Day 6 我已經簡單提過 Service 可以幫我們解決「Pod IP 會變動」的問題。今天就不再重複這段,而是要來拆解 Service 在背後到底是怎麼運作的——尤其是 iptables 在裡面的角色。這部分我將繼續參考 sookocheff 的文章,並嘗試用更直白的方式整理。
先複習一下:雖然 Pod 身上有 IP 可以作為訪問一句,但是 Pod 會在 scaling 時重啟或消失、非常不穩定;而 Service 提供了一個「穩定的虛擬 IP (ClusterIP)」,Pod 可以透過這個 VIP 來存取對應的一組後端 Pod。
但問題是,這個 VIP 不是實際存在的網卡 IP,它只是一個邏輯概念。那封包打到這個 IP 的時候,誰來處理?答案就是:kube-proxy。
kube-proxy 會監聽所有 Service 與 Endpoint 的變化,然後在每個 Node 上紀錄一堆 iptables 規則,把「打到 Service VIP 的流量」轉送到實際的 Pod IP。換句話說:
iptables 的原理會透過 linux 提供的 netfilter 框架,來達到封包過濾、NAT 位址轉換等功能,這些功能讓封包能在網路中正確導流,也能防止封包抵達相對敏感的區域。
當一個封包打到 Service 的虛擬 IP 時,iptables 就會出來接手。它會去查 kube-proxy 寫好的規則,隨機挑一個符合條件的 Pod,把原本的 Service IP 改寫成這個 Pod 的真實 IP。之後,封包就能順利送到正確的地方。每當 Pod 被新增或移除,這些規則也會自動更新,確保流量永遠有路可走。
可以把它想成「門牌對照表」:Service IP 是大樓的統一門牌號碼,而 iptables 則是大樓管理員,會告訴郵差今天要把信送到哪一戶 Pod。
當我們建立一個 Service,例如:
apiVersion: v1
kind: Service
metadata:
name: my-service
spec:
selector:
app: nginx
ports:
- port: 80
targetPort: 8080
kube-proxy 會自動在 Node 上生成一組 iptables 規則,大概長這樣:
CLUSTER-IP:80。KUBE-SERVICES 的 chain。KUBE-SERVICES chain 再把它丟到 KUBE-SVC-xxxxx(對應到這個 Service)。KUBE-SVC-xxxxx 裡面有多個 KUBE-SEP-xxxxx(對應到不同的 Pod Endpoint)。這裡的「SEP」就是 Service Endpoint 的縮寫,每一條規則都指向一個實際 Pod IP。
小結:Service VIP 其實就是一個「虛擬入口」,真正的工作都是 iptables 規則在背後做 DNAT(Destination NAT),把目的 IP 從 VIP 改成 Pod IP。
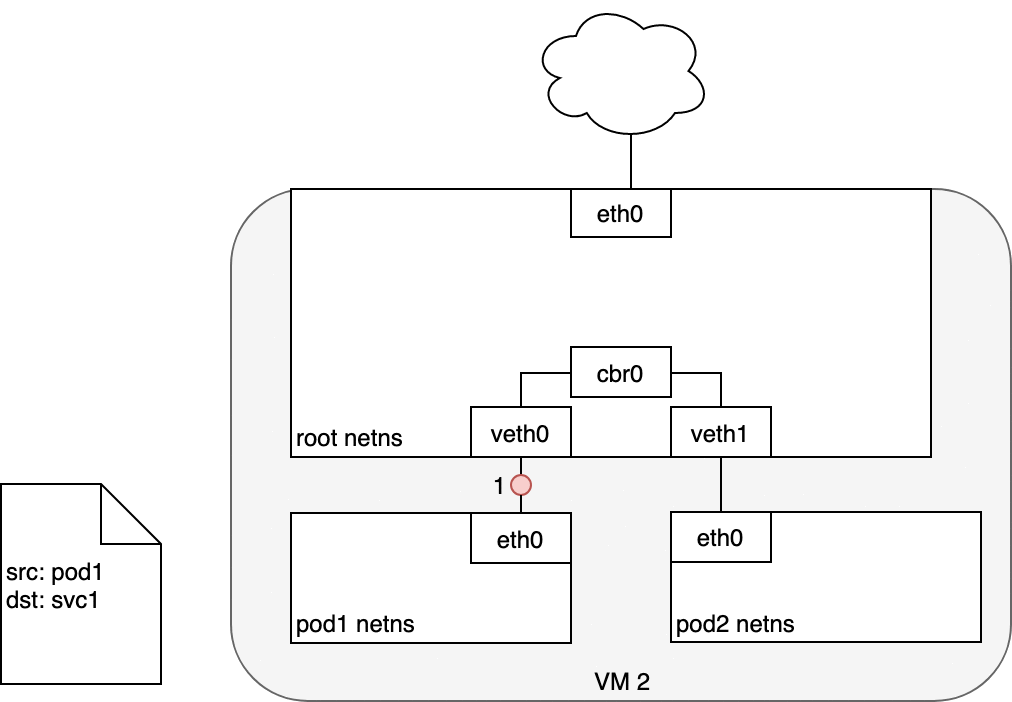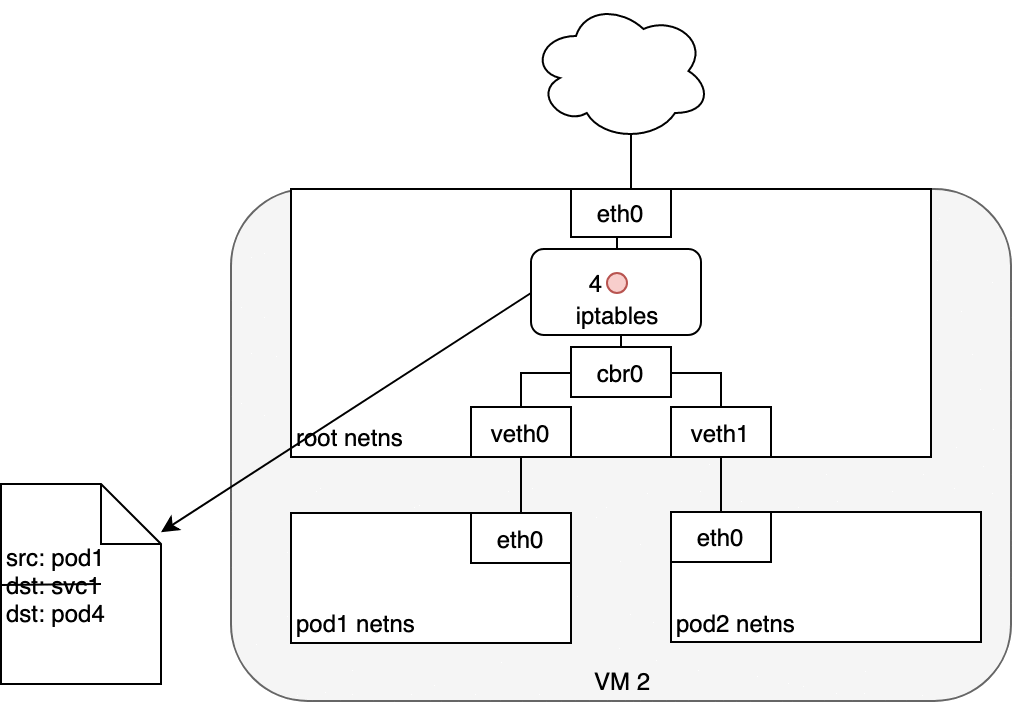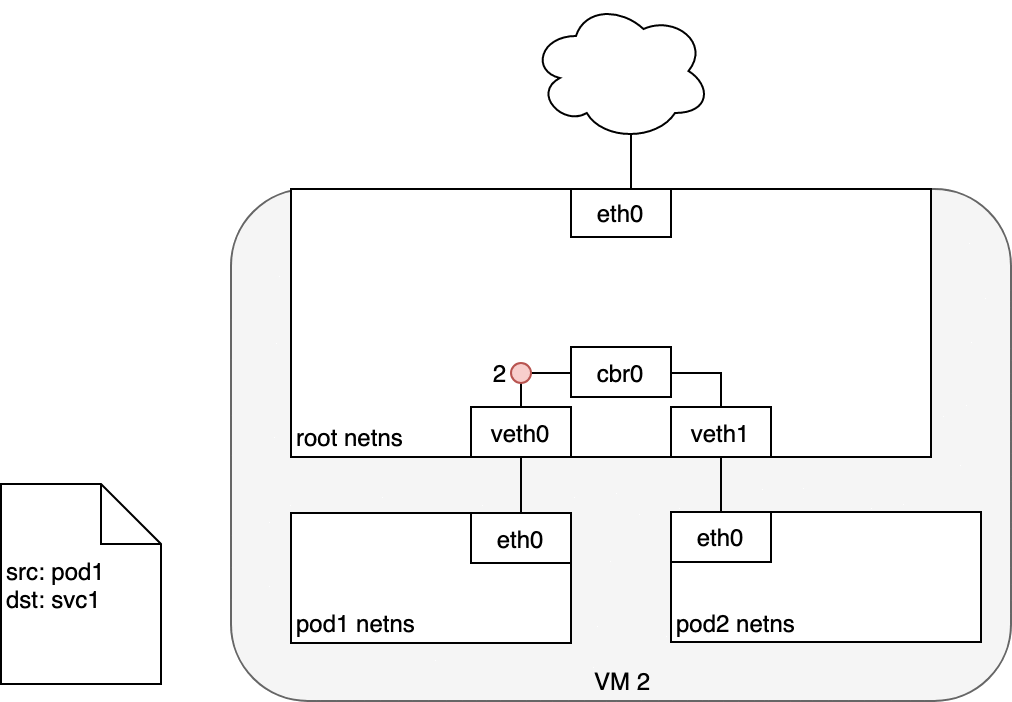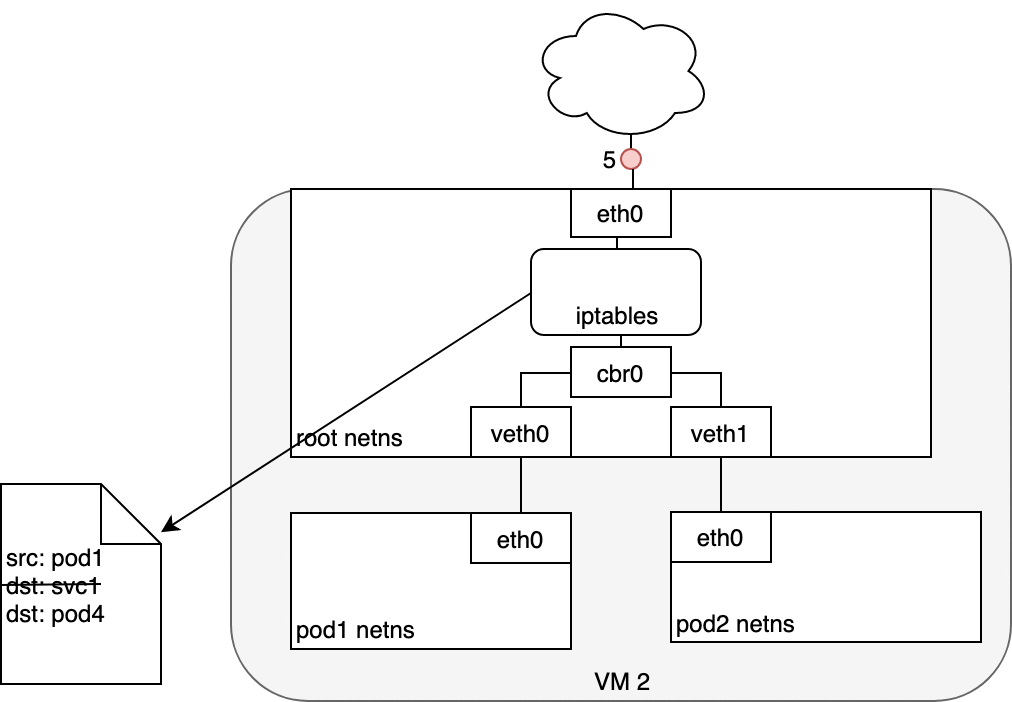
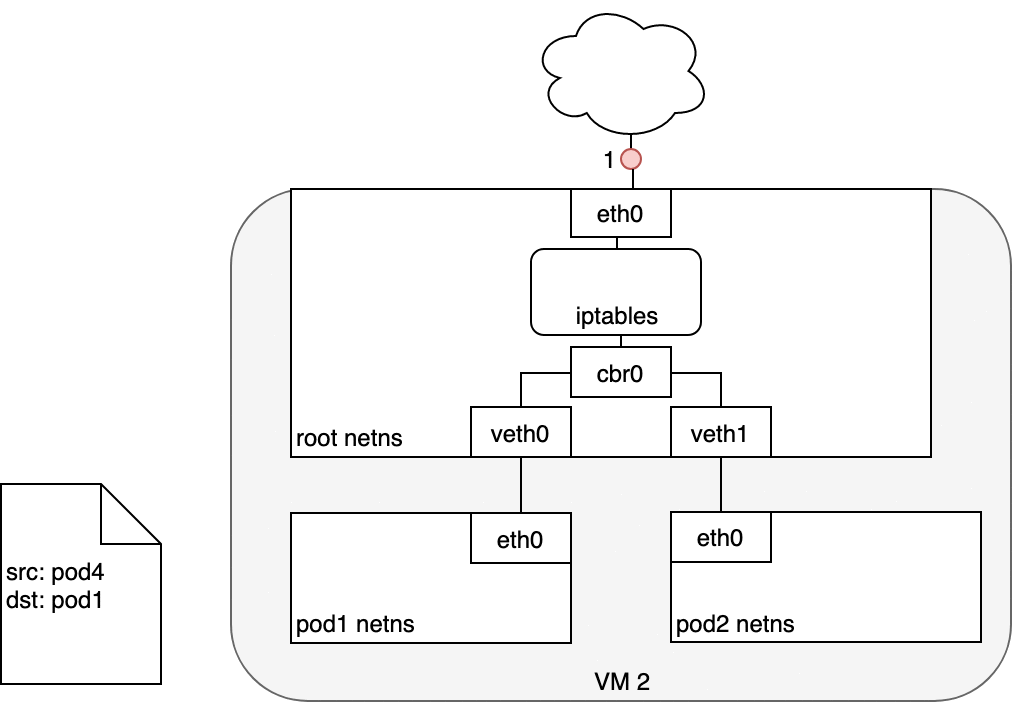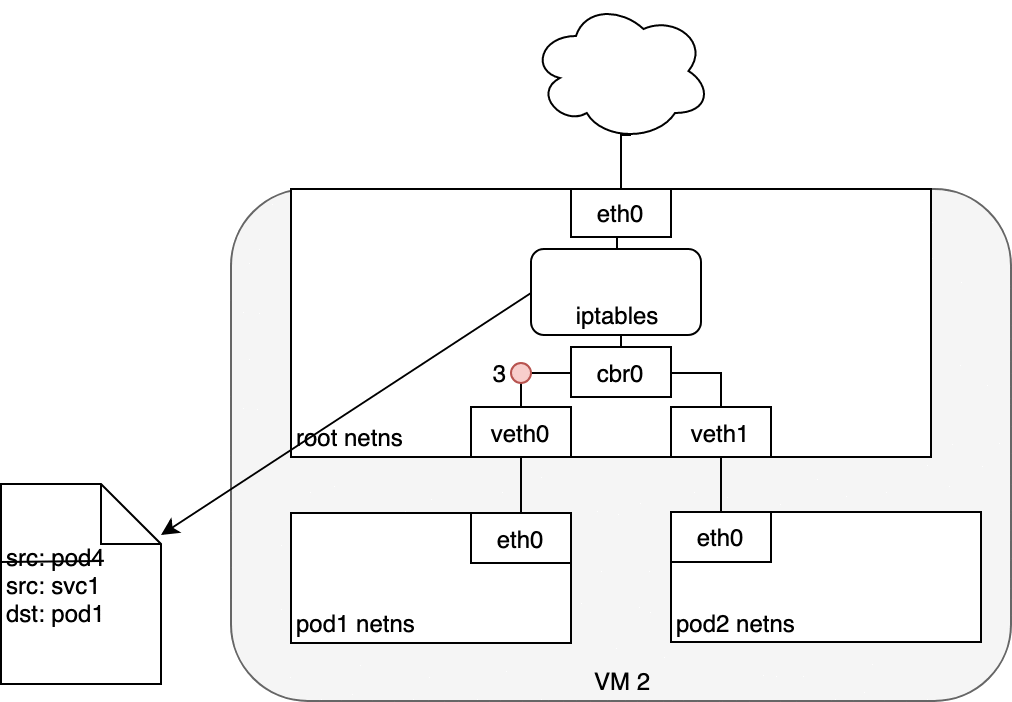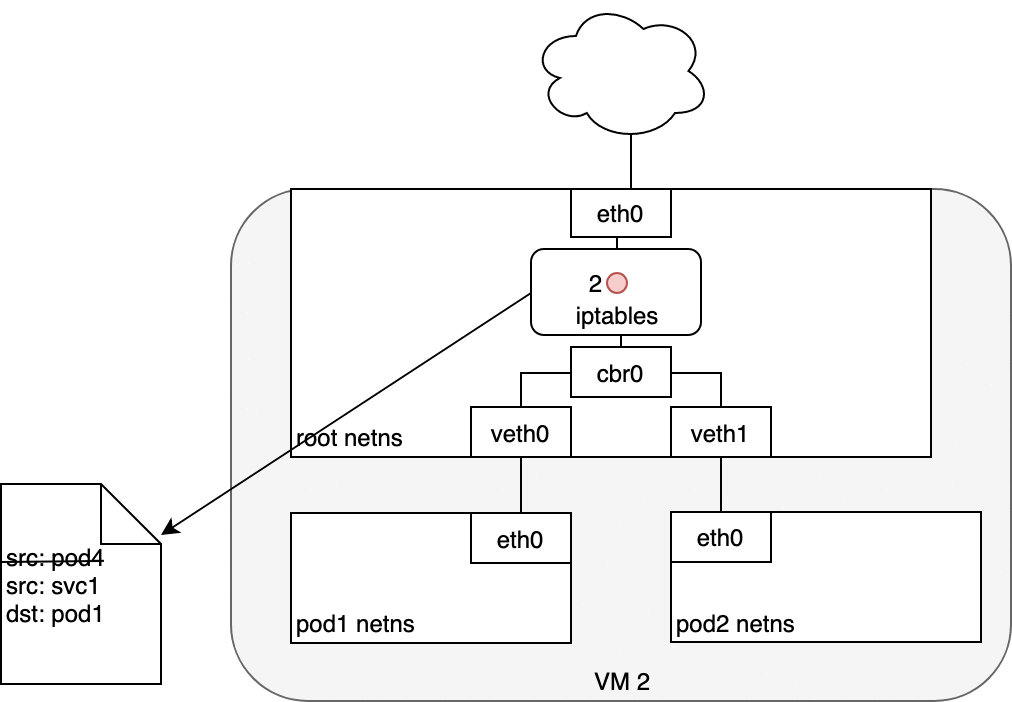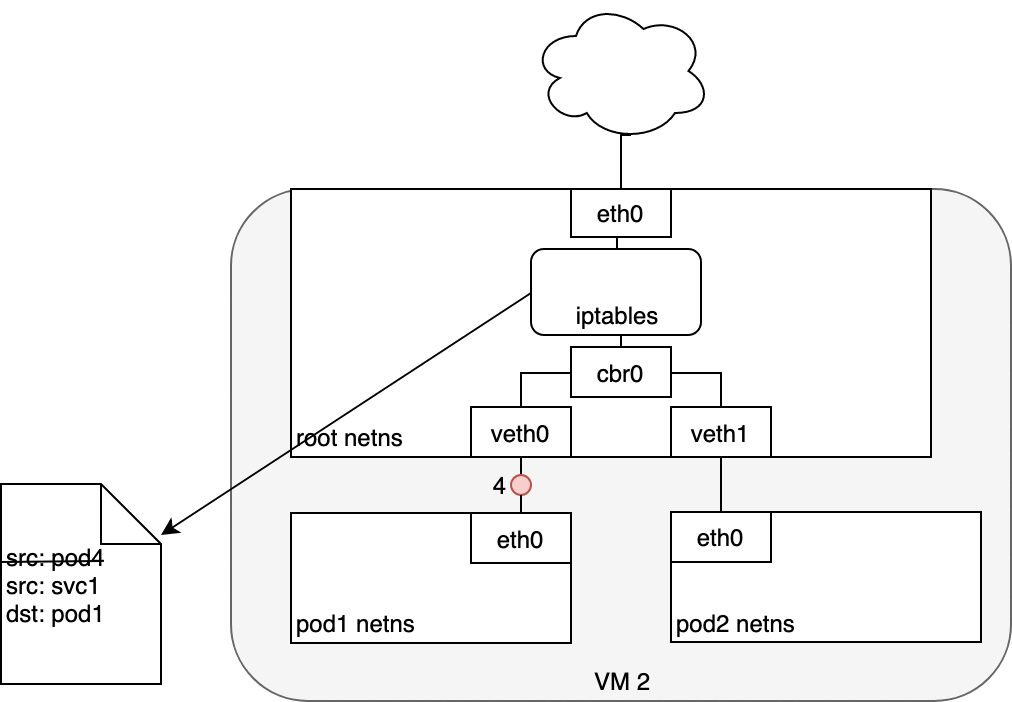
封包先從 Pod 的 eth0 出來。
接著透過 veth pair 被帶到 Node 的 Bridge。
Bridge 不認得 Service 這個虛擬 IP,所以會把封包送往 Node 的預設路由。
在 eth0 接收封包之前,它會先經過 iptables 的過濾。iptables 使用由 kube-proxy 安裝的規則,把封包的目標從 Service IP 改寫為某個特定 Pod 的 IP
現在這個封包的目標不再是 Service 的虛擬 IP,而是某個真實的 Pod。Linux kernel 的 conntrack 工具會記住這個 Pod 的選擇,確保後續流量都走同一個 Pod(除非 cluster 有 scaling event)。
從本質上來說,iptables 在 Node 上直接完成了叢集內的負載平衡。接下來流量會透過我們昨天(Day 24)介紹過的 Pod ↔ Pod 路徑傳送到目標 Pod (5)。
這個過程對 Pod A 來說是透明的,它只知道自己打了一個固定的 Service IP。
當 Pod 收到請求後會送出回應,這時候封包的來源 IP 原本是 Pod 自己。但在回程經過 iptables 時,系統會查 conntrack 的紀錄,把來源 IP 改回 Service IP。這樣對外部來說,整條連線看起來都像是在跟 Service 打交道,而不是某個特定的 Pod。這就像你去餐廳拿餐點,外送袋上只會印「餐廳名字 (Service)」,不會寫是哪位廚師 (Pod) 做的。
雖然 Service 有自己的 ClusterIP,但我們通常不會在程式裡硬寫這個 IP。因為 ClusterIP 可能會變化,這樣會導致應用程式不穩定。Kubernetes 內建的 DNS(例如 CoreDNS),會自動幫每個 Service 生成一個固定的名稱,像是 my-service.default.svc.cluster.local。應用只要記住這個名字,就能一直找到對應的 Service,而不用擔心 IP 改來改去。
在 Kubernetes 裡,DNS 本身也是以一個普通的 Service 形式存在,並被排程到叢集裡的 Pod 上運行。每個 Node 上的 kubelet 都會被設定好,讓容器能透過這個 DNS Service 的 IP 來查詢網域名稱。
這樣一來,叢集裡的每個 Service(包含 DNS Server 自己)都會擁有一個對應的 DNS 名稱。DNS 記錄會將這些名稱解析到 Service 的 ClusterIP,如果需要的話,也能直接解析到 Pod 的 IP。而對於需要指定服務埠號的情況,則會用到 SRV 記錄。
早期的 Kubernetes 使用 kube-dns,它的 Pod 其實是由三個容器組成:
這個 DNS Pod 會被暴露成一個擁有固定 ClusterIP 的 Kubernetes Service,並在容器啟動時就被注入。這樣,每個容器都能透過這個固定的 DNS Service IP 來做名稱解析。背後的流程是:kubedns 維護記憶體內的 DNS 狀態,並透過 etcd 取得叢集的實際狀態,必要時會重新同步並重建快取。
後來,Kubernetes 社群推出了 CoreDNS,它在運作方式上和 kube-dns 類似,但因為採用了 plugin 架構,更容易擴充與自訂。從 Kubernetes 1.11 開始,CoreDNS 就成了官方預設的 DNS 實作。
到目前為止,我們已經看了 Kubernetes 叢集內的流量路由。這些都很好,但如果應用被完全隔離於外部世界,就無法滿足實際需求 —— 在某個時刻,我們總是需要將服務暴露給外部流量。這會引出兩個相關問題:
本節將依次處理這兩個問題。
在 Kubernetes 叢集裡,Pod 有自己的 IP,而這個 IP 與 Node 的 VM IP 並不相同。問題在於,Internet Gateway 的 NAT 只認得 VM 的 IP,並不知道 Pod 的存在。為了讓 Pod 的流量能夠成功到達外部,Kubernetes 再次利用 iptables 進行處理。
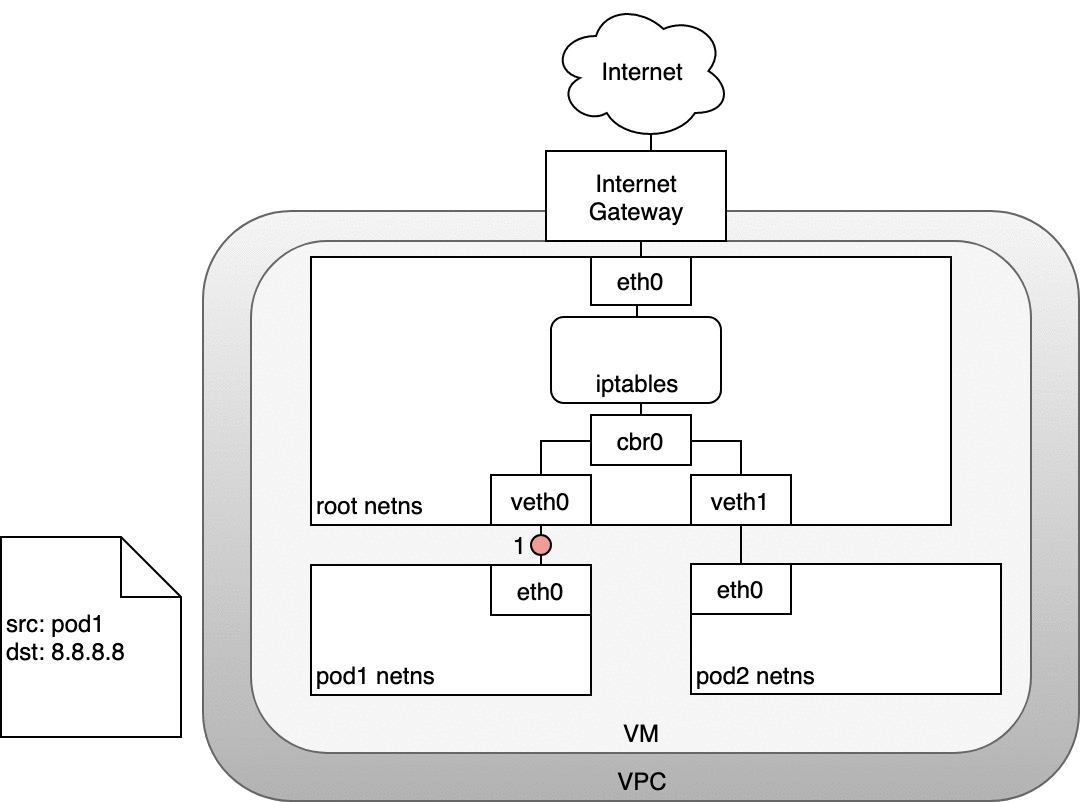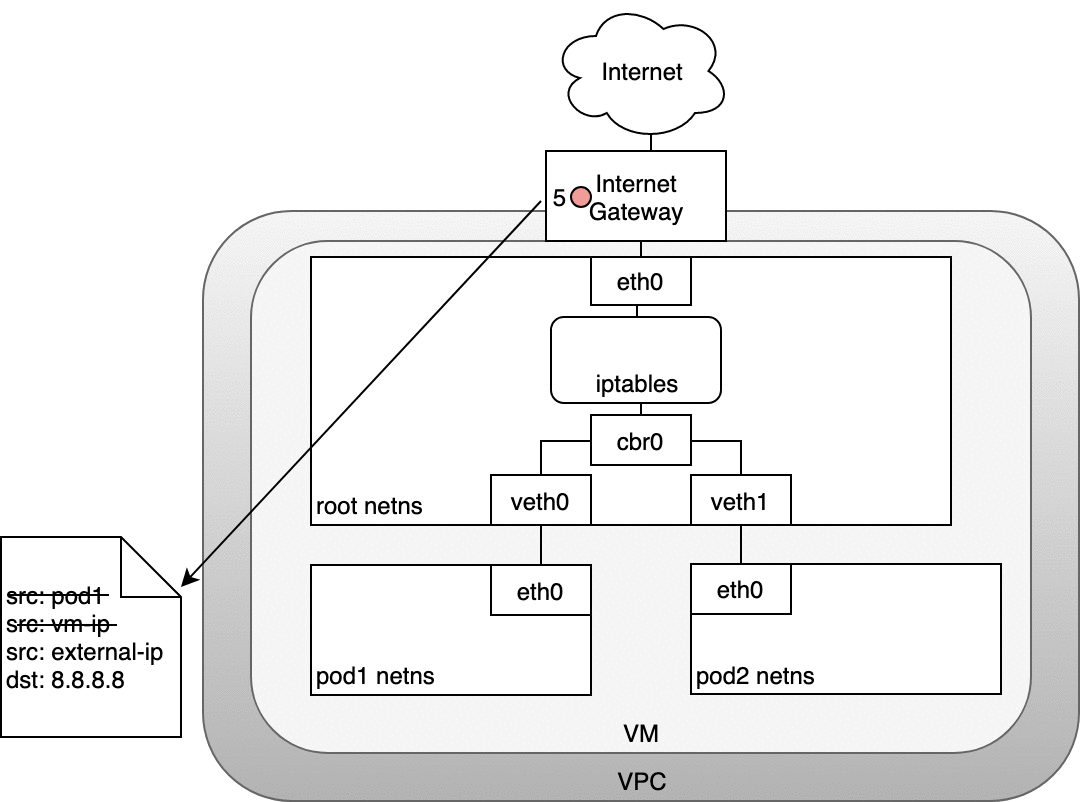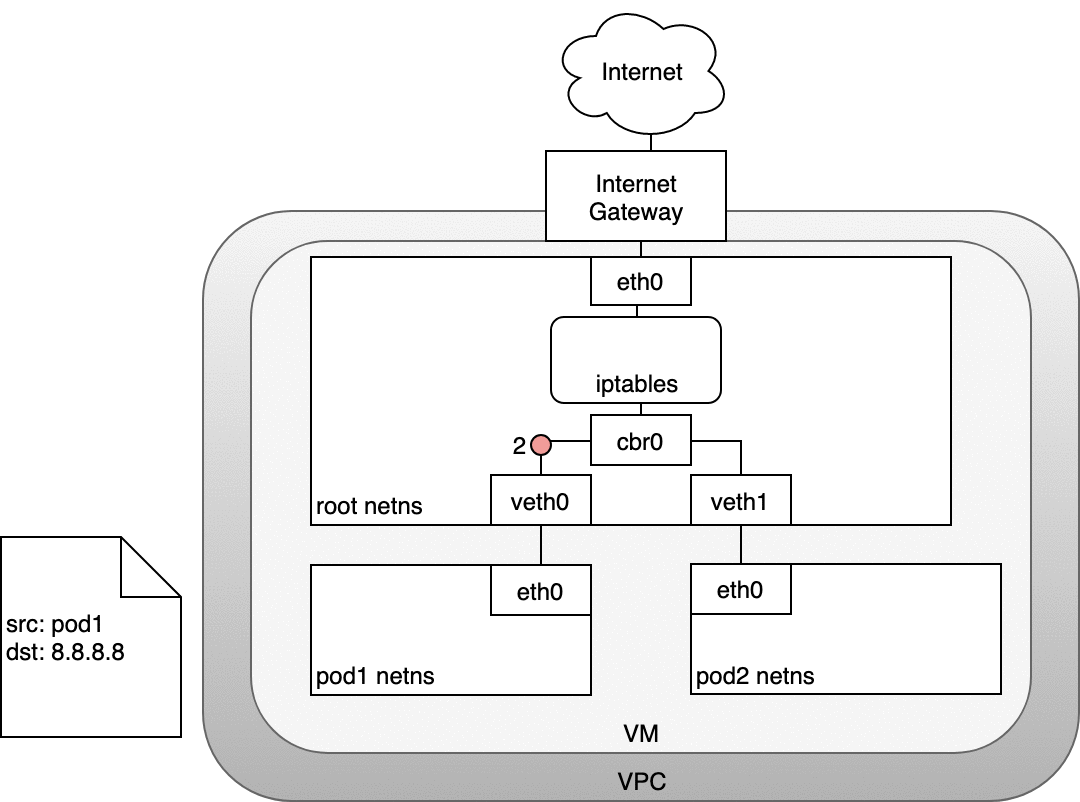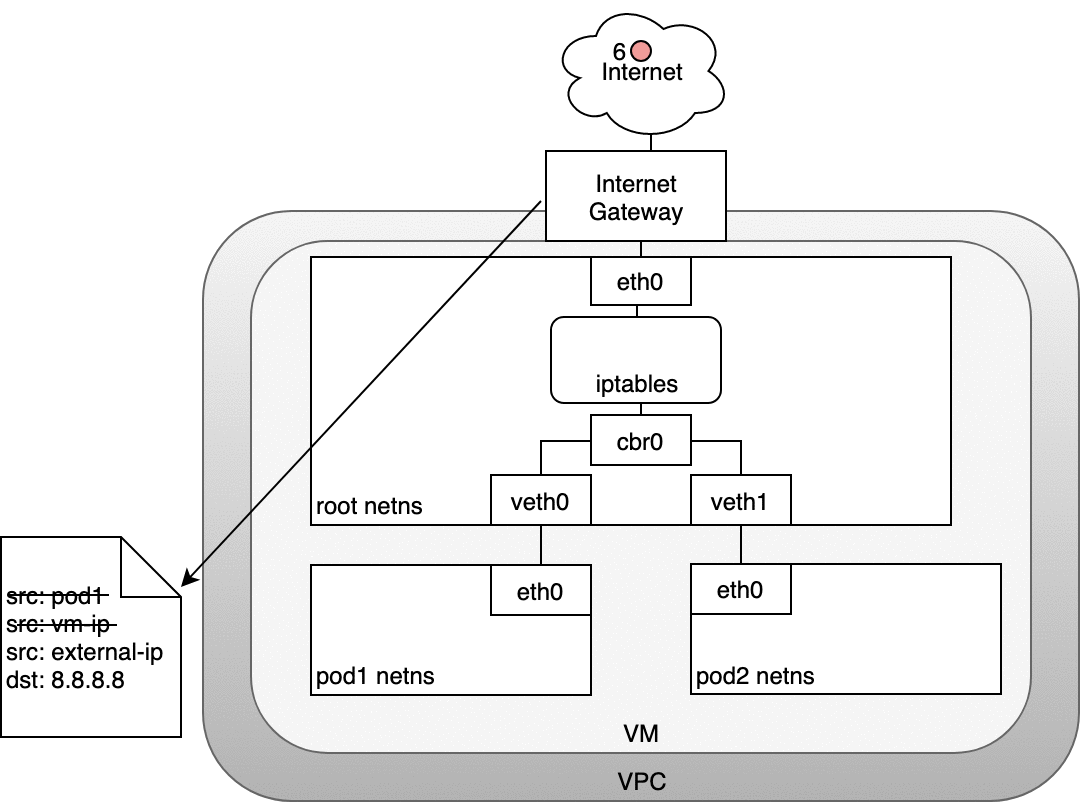
從 Pod 路由封包到 Internet 的流程
回程時,封包會沿著相同的路徑回來,並在每個步驟還原 NAT 修改,確保 Pod、Node、Gateway 各自都能正確理解封包的來源與目的。
Ingress 的挑戰在於,雲端環境與網路配置各有不同,但大致可以分成兩種方式:
當建立一個 Kubernetes Service 時,可以指定 type=LoadBalancer。此時,Cloud Controller 會自動建立一個雲端 LoadBalancer,並將其 IP 公佈出來。使用者只需要透過這個 IP 就能存取 Service。
以 AWS 為例,建立 Service 後,AWS 會配置一個 LoadBalancer,並且把叢集內所有 Node 加入到它的 Target Group。當流量到達 Node 時,iptables 規則會確保封包被轉發到正確的 Pod。
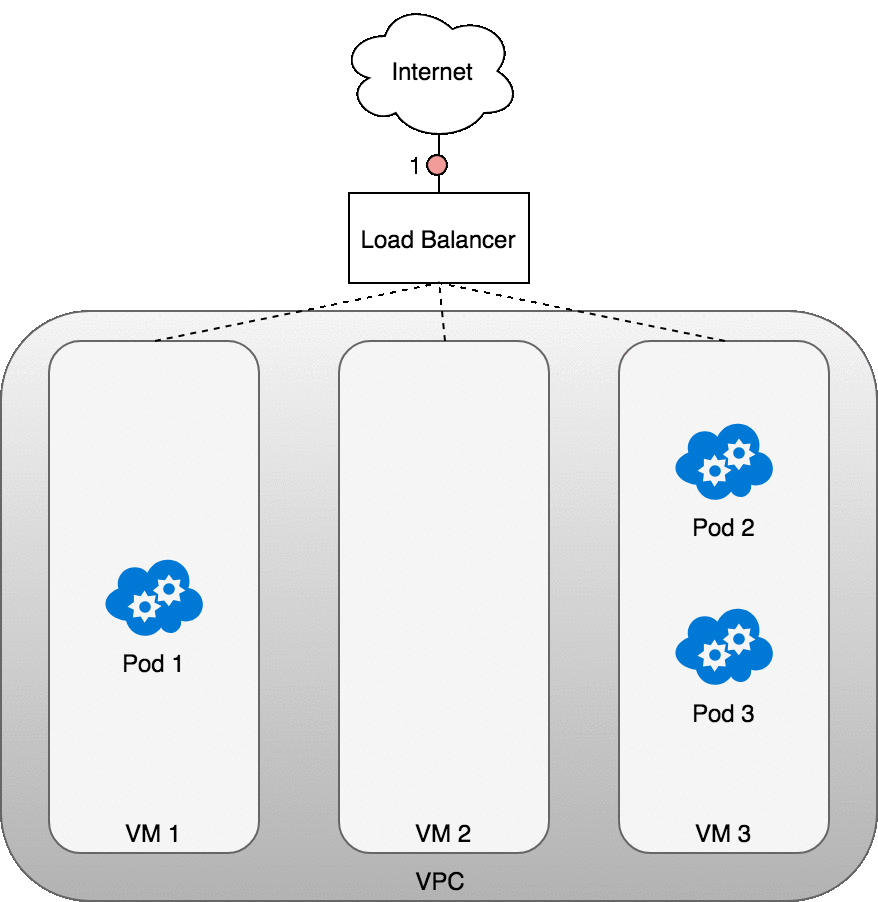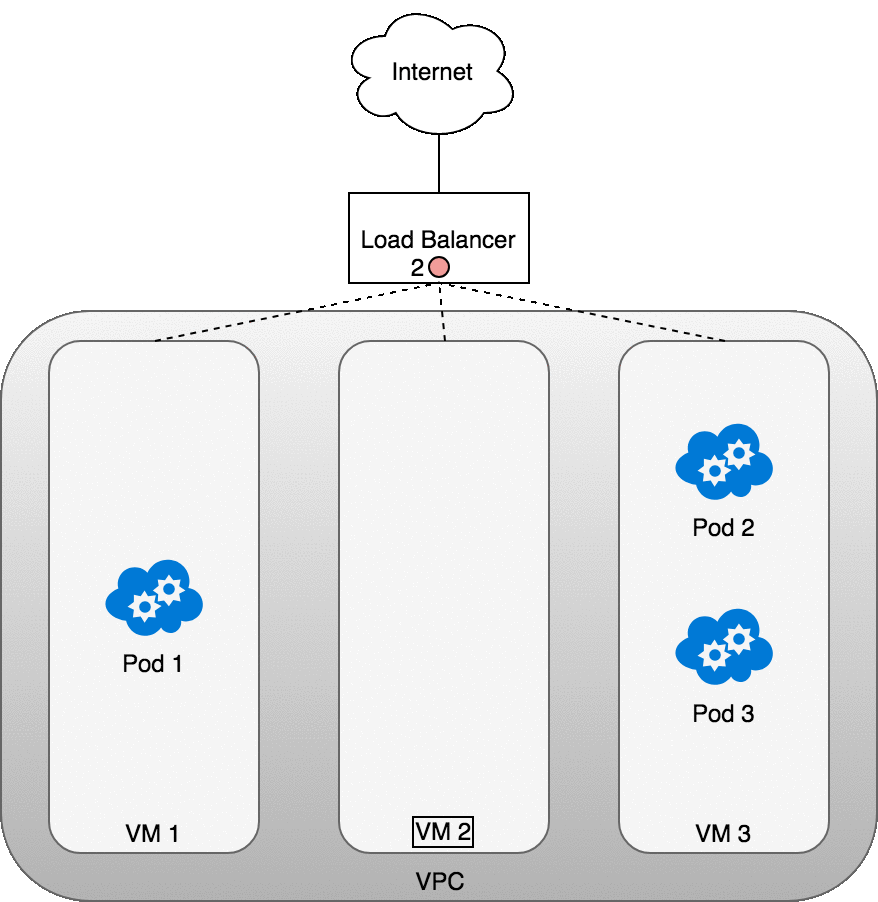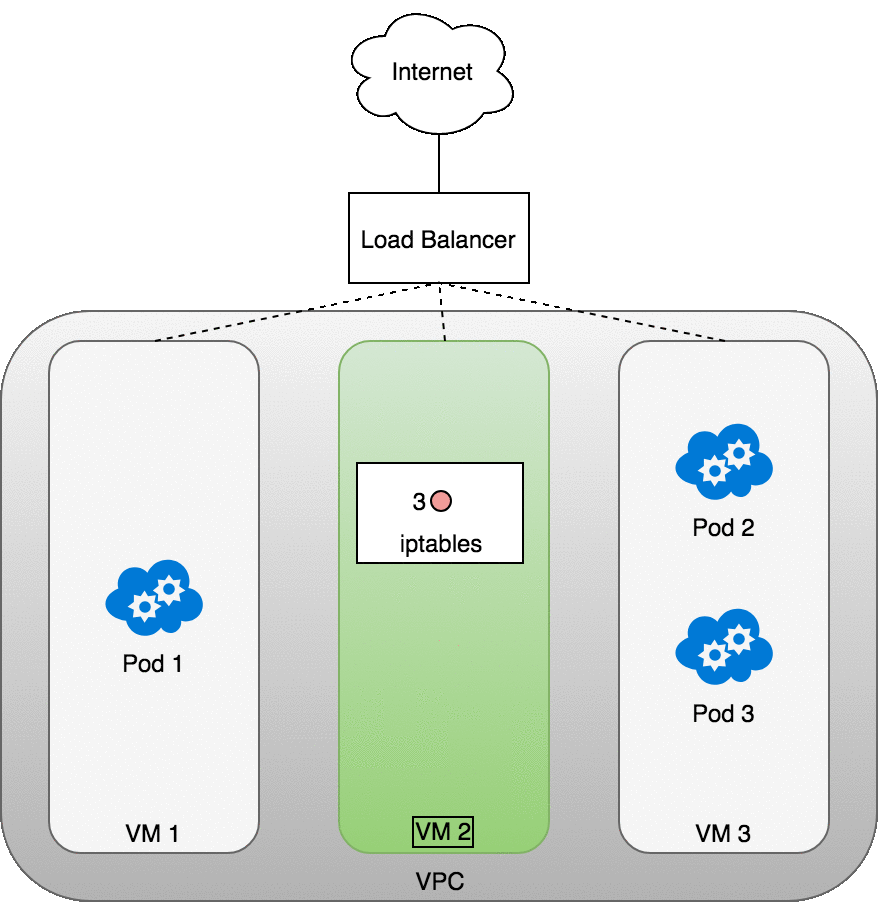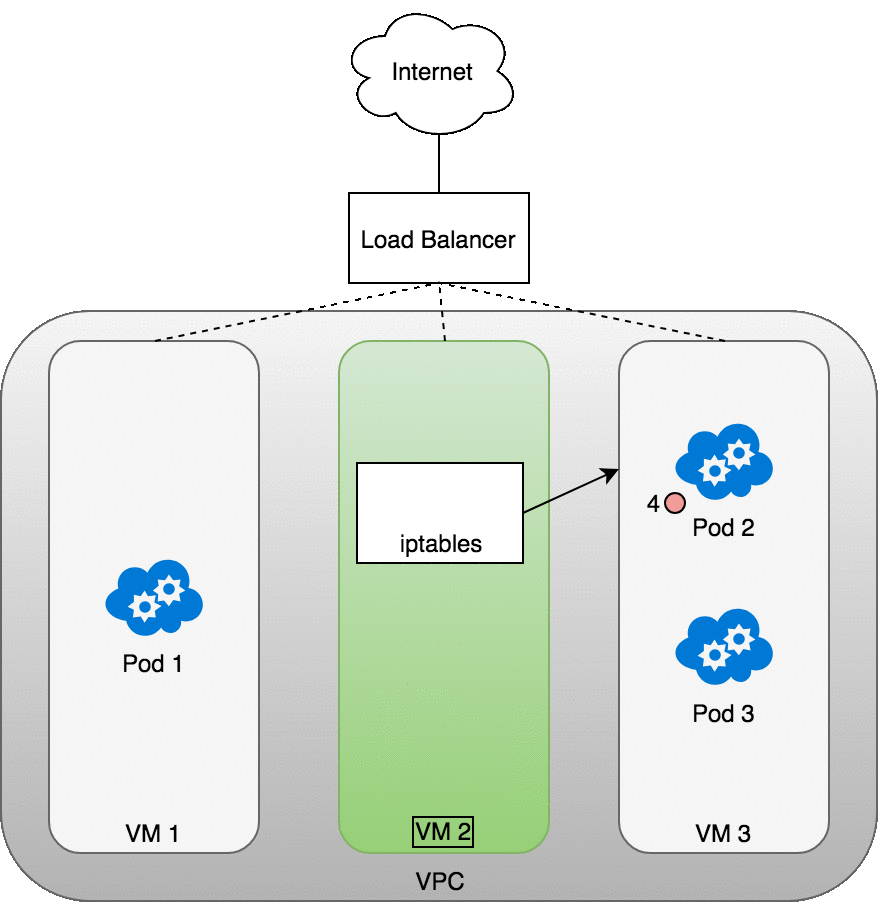
從 Internet 傳送封包到 Service 的流程
在 L7 層,Ingress 主要處理 HTTP/HTTPS 的流量。它需要依靠 NodePort Service,透過固定範圍內的埠號把流量暴露到每個 Node,然後再由 Ingress Controller 做更高階的轉發。
以 AWS 為例,Ingress Controller 會利用 Application Load Balancer (ALB) 來完成。
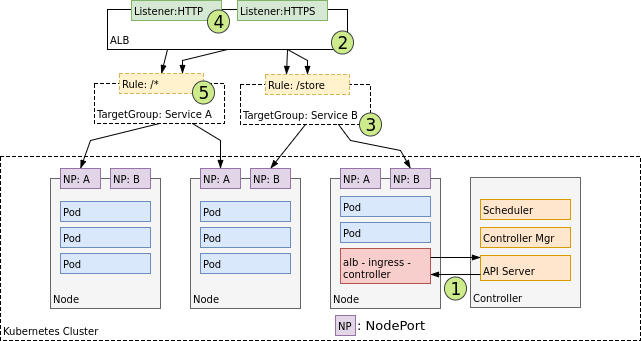
Ingress Controller 的設計
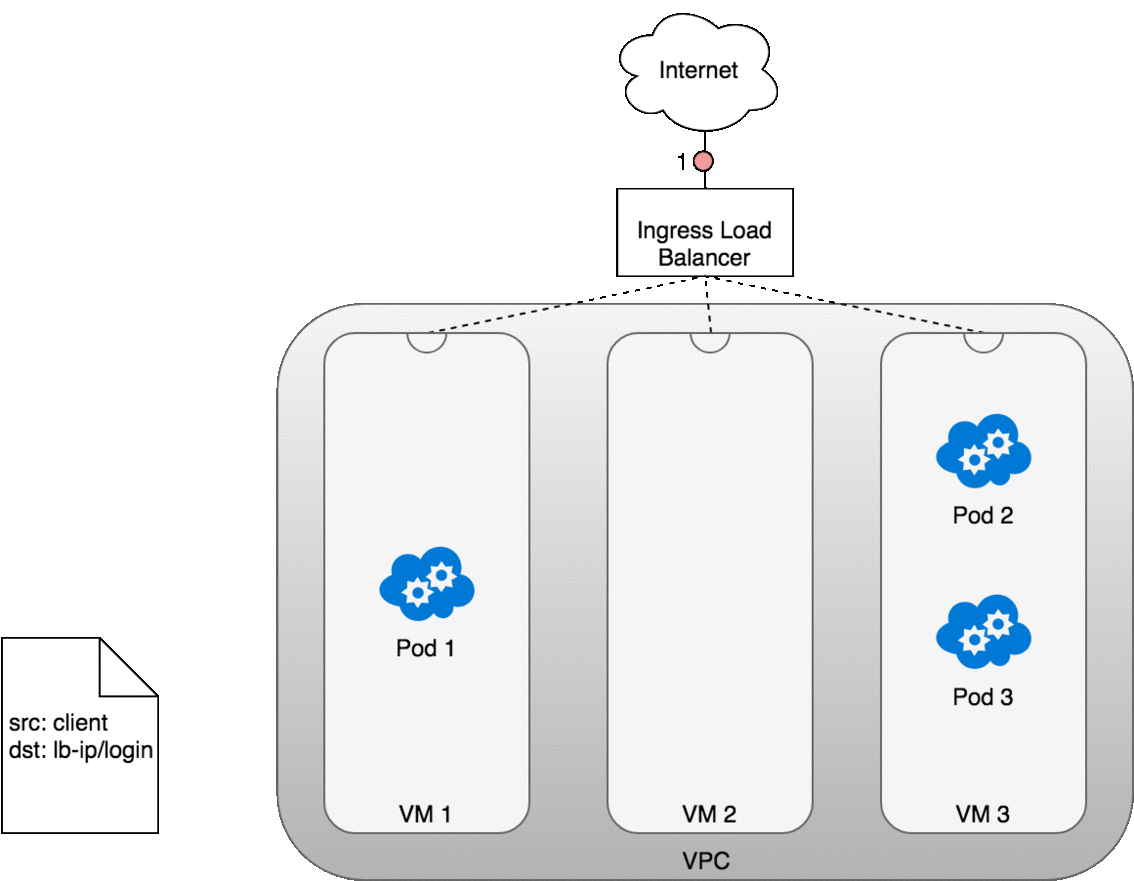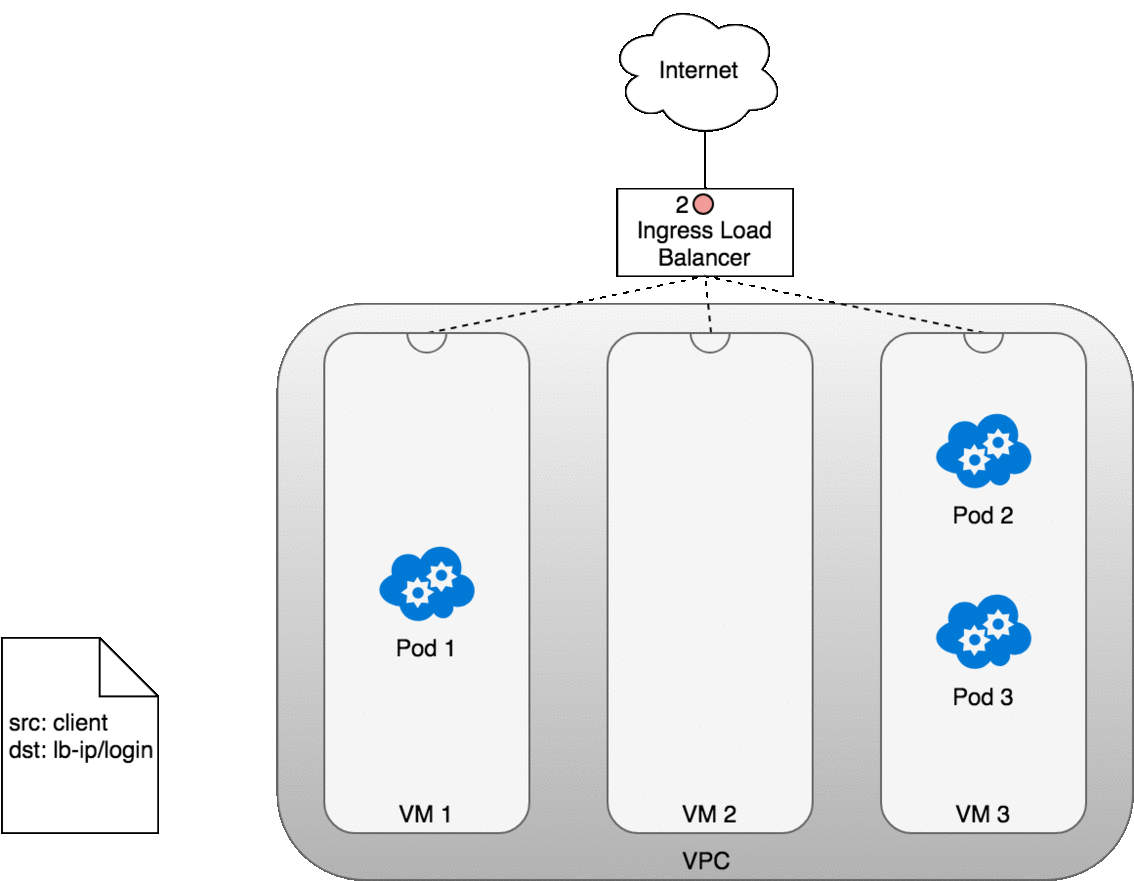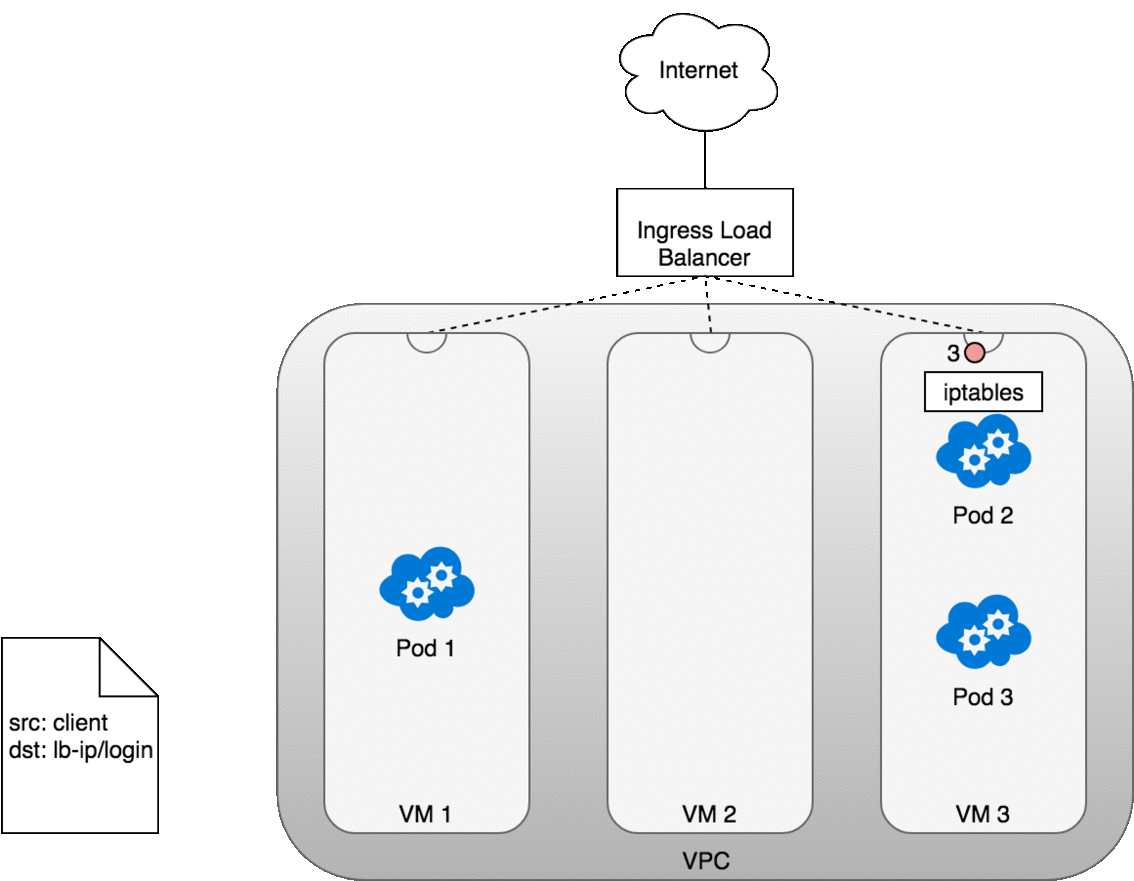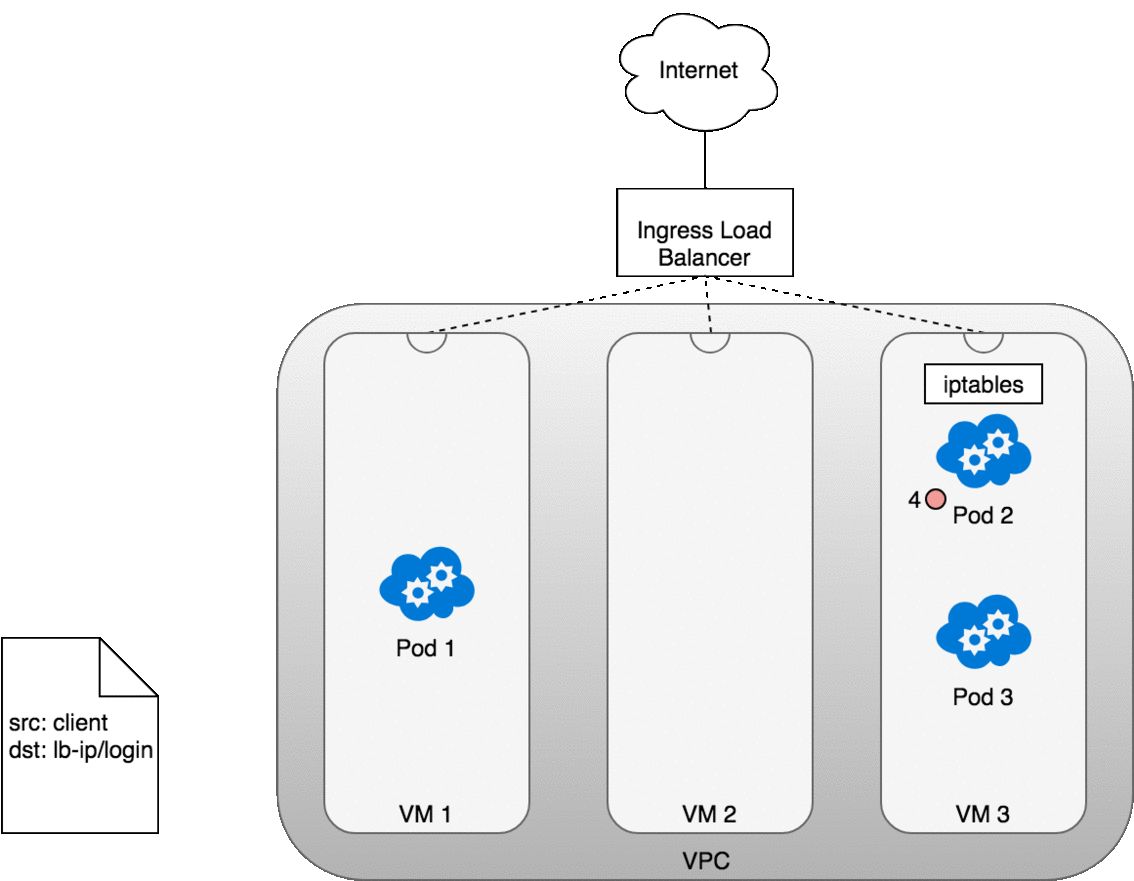
從 Ingress 傳送封包到 Service
這個流程和 LoadBalancer 類似,差別在於:
當你部署一個 Service 並建立 Ingress 時:
Ingress 與 LoadBalancer 的差別在於:Ingress 能識別 HTTP 的 Hostname 與 Path,並依照規則把流量分流到不同的 Service;同時,它也能在 HTTP Header 中保留 Client 的原始 IP(例如 X-Forwarded-For)。這些機制雖然能解決進出流量的問題,但在效能與安全性上仍然有限,這也是為什麼我們需要進一步的方案,例如 Cilium。
今天我們從 Pod-to-Service 的路徑,一路講到 Internet-to-Service 的進出流程:
這些都是 Kubernetes 網路的基礎設計,能滿足多數情境,但在 大規模運行 或 進階安全策略 上仍有不少限制。從 Day 26 開始,我們將深入介紹 Cilium,看看它如何透過 eBPF 打破這些框架,提供更靈活與高效的網路模型。Day 28 則會進一步探討 Istio,了解 Service Mesh 在這些基礎之上又能帶來哪些額外能力。 🚀
