今天沒有放程式碼!就是清楚了昨天為什麼模型回答不好的原因。
這是PaliGemma的官網:https://ai.google.dev/gemma/docs/paligemma?hl=zh-tw
它上面的每一字都要詳細閱讀,才不會發生我昨天的失誤。
PaliGemma 模型分為三類:
官網上非常明白的表示:
重要事項: 預先訓練的 PaliGemma 模型需要進行調整,才能產生實用的結果。請務必對這些 PaliGemma 模型進行微調,並在將模型部署給使用者前,測試輸出內容。
所以若要直接使用,要用混合模型 mix 版,預訓練模型 pt 版需要微調才能用!!!
(若我有撐下去,後面應該就有機會玩一下模型微調)
PaliGemma可以透過Hugging face 或 Keras-Hub載入模型。昨天嘗試用Hugging face載入模型,今天改用Keras-Hub載入模型,但 Keras-Hub 底層權重存放在 Kaggle,因此需要在 Colab 中設置 Kaggle 憑證。
需要先在 Kaggle 網站上確認您已接受模型的使用條款:
https://www.kaggle.com/models/keras/paligemma2/keras/pali_gemma2_mix_3b_224/2
使用模型前也需要在 Kaggle 網站上取得 Token,今天先完成實作,如何進行授權設定之後再整理。
我昨天失誤的原因之二是我用的範例prompt 沒有用前輟字提示語法。
官網中有提到:
可以使用以下提示工作語法,要求 PaliGemma 模型執行特定行為:
"cap {lang}\n":非常簡短的字幕 (僅支援 PT)
"caption {lang}\n":簡短字幕
"describe {lang}\n":較長且較具說明性的字幕 (僅適用於 PT)
"ocr":光學字元辨識 (僅限 PT 支援)
"answer {lang} {question}\n":回答有關圖片內容的問題
"question {lang} {answer}\n":針對特定答案產生問題 (僅適用於 PT)
"detect {object} ; {object}\n":在圖片中找出所列物件,並傳回這些物件的邊界框
"segment {object} ; {object}\n":找出圖片中列出物件所佔據的區域,為該物件建立圖像區隔
我測試的結果,是有用這些提示工作語法,會得到比較好的答案,例如我用了一張有3隻北極熊的圖片

若是用一般的指令"請描述這張照片",模型就只回答"bear"。但若prompt裡有先加上前輟"describe....",模型就回覆了一段話"
Three polar bears walk across a snow-covered field. The bears are white, with black noses and eyes. The ground is covered in snow, and the sky is gray. The bears are standing in the snow, and their tracks are visible in the snow. The baby polar bear is walking, and the large polar bear is standing. The bears are looking at the camera, and their eyes are black.
比較有趣的是detect及segment:
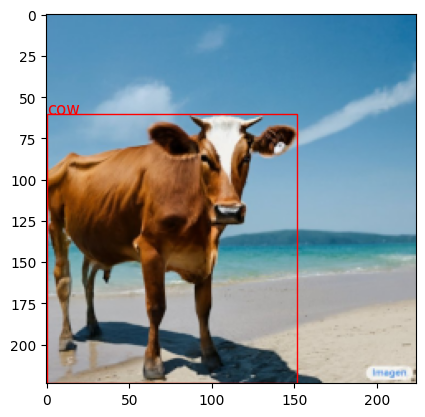
載入一張牛的照片
target_size = (224, 224)
image_url = 'https://storage.googleapis.com/keras-cv/models/paligemma/cow_beach_1.png'
cow_image = read_image(image_url, target_size)
進行物件辨識,使用了detect前輟。
物件辨識的輸出結果為固定格式,舉例:
<loc0343><loc0059><loc0791><loc0945>
官網範例程式碼有擷取及繪製bounding box的函數,請先自行參考。
之後我再陸續整理。
prompt = 'detect cow\n'
output = paligemma.generate(
inputs={
"images": cow_image,
"prompts": prompt,
}
)
boxes, labels = parse_bbox_and_labels(output)
display_boxes(cow_image, boxes, labels, target_size)
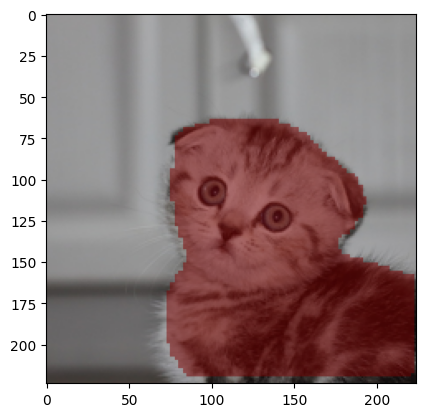
載入一張猫的照片,進行物件分割,使用了segment前輟。
物件分割的輸出結果為固定格式,舉例:
<loc0343><loc0059><loc0791><loc0945><seg066><seg074><seg074><seg081><seg082><seg011><seg018><seg066><seg101><seg055><seg029><seg049><seg039><seg059><seg064><seg008>
官網範例程式碼有擷取及繪製的函數,請先自行參考。
cat = read_image('https://cdn.pixabay.com/photo/2020/08/16/06/28/cat-5491989_1280.jpg', target_size)
prompt = 'segment cat\n'
output = paligemma.generate(
inputs={
"images": cat,
"prompts": prompt,
}
)